RE: Initial COPY of Logical Replication is too slow
| From: | "Hayato Kuroda (Fujitsu)" <kuroda(dot)hayato(at)fujitsu(dot)com> |
|---|---|
| To: | 'Masahiko Sawada' <sawada(dot)mshk(at)gmail(dot)com>, Amit Kapila <amit(dot)kapila16(at)gmail(dot)com> |
| Cc: | Jan Wieck <jan(at)wi3ck(dot)info>, "pgsql-hackers(at)lists(dot)postgresql(dot)org" <pgsql-hackers(at)lists(dot)postgresql(dot)org> |
| Subject: | RE: Initial COPY of Logical Replication is too slow |
| Date: | 2026-03-26 08:35:51 |
| Message-ID: | OS9PR01MB121494C802D79DAAEA1B1D073F556A@OS9PR01MB12149.jpnprd01.prod.outlook.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
Dear Sawada-san,
(Sending again because blocked by some rules)
I ran the performance testing independently for the 0001 patch. Overall performance looked
very nice, new function spent O(1) time based on the total number of tables.
It seems good enough.
Source code:
----------------
HEAD (4287c50f) + v4-0001 patch.
Setup:
---------
A database cluster was set up with shared_buffers=100GB. Several tables were
defined on the public schema, and same number of tables were on the sch1.
Total number of tables were {50, 500, 5000, 50000}.
A publication included a schema sch1 and all public tables individually.
Attached script setup the same. The suffix is changed to .txt to pass the rule.
Workload Run:
--------------------
I ran two types of SQLs and measured the execution time via \timing metacommand.
Cases were emulated which tablesync worker would do.
Case 1: old SQL
```
SELECT DISTINCT
(CASE WHEN (array_length(gpt.attrs, 1) = c.relnatts)
THEN NULL ELSE gpt.attrs END)
FROM pg_publication p,
LATERAL pg_get_publication_tables(p.pubname) gpt,
pg_class c
WHERE gpt.relid = 17885 AND c.oid = gpt.relid
AND p.pubname IN ( 'pub' );
```
Case 2: new SQL
```
SELECT DISTINCT
(CASE WHEN (array_length(gpt.attrs, 1) = c.relnatts)
THEN NULL ELSE gpt.attrs END)
FROM pg_publication p,
LATERAL pg_get_publication_tables(p.pubname, 16535) gpt,
pg_class c
WHERE c.oid = gpt.relid
AND p.pubname IN ( 'pub' );
```
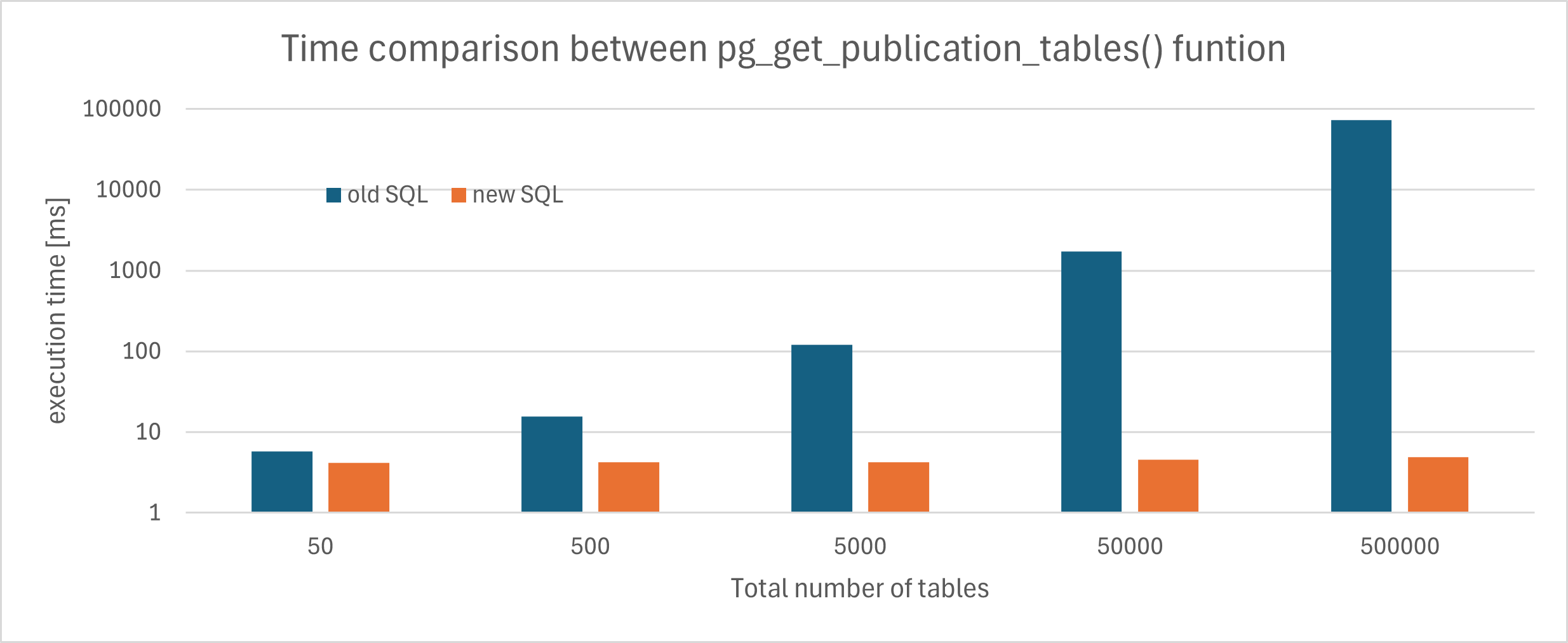
Result Observations:
---------------
Attached bar graph shows the result. A logarithmic scale is used for the execution
time (y-axis) to see both small/large scale case. The spent time became approximately
10x longer for 500->5000, and 5000->50000, in case of old SQL is used.
Apart from that, the spent time for the new SQL is mostly the stable based on the
number of tables.
Detailed Result:
--------------
Each cell are the median of 10 runs.
Total tables Execution time for the old SQL was done [ms] Execution time for the old SQL was done [ms]
50 5.77 4.19
500 15.75 4.28
5000 120.39 4.22
50000 1741.89 4.60
500000 73287.16 4.95
Also, here is a small code comment. I think we can have an Assert at the
begining of the pg_get_publication_tables(), something like below.
```
@@ -1392,6 +1392,9 @@ pg_get_publication_tables(FunctionCallInfo fcinfo, ArrayType *pubnames,
FuncCallContext *funcctx;
List *table_infos = NIL;
+ Assert((pubnames && (!pubname && !OidIsValid(target_relid))) ||
+ (!pubnames && (pubname && OidIsValid(target_relid))));
```
Best regards,
Hayato Kuroda
FUJITSU LIMITED
| Attachment | Content-Type | Size |
|---|---|---|
|
image/png | 30.3 KB |
| setup.txt | text/plain | 1.2 KB |
In response to
- Re: Initial COPY of Logical Replication is too slow at 2026-03-25 05:06:54 from Masahiko Sawada
Responses
- RE: Initial COPY of Logical Replication is too slow at 2026-03-26 12:46:27 from Hayato Kuroda (Fujitsu)
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | David Geier | 2026-03-26 08:50:28 | Re: Use correct collation in pg_trgm |
| Previous Message | Andrey Borodin | 2026-03-26 08:32:41 | Re: Add uuid_to_base32hex() and base32hex_to_uuid() built-in functions |