RE: Parallel Apply
| From: | "Hayato Kuroda (Fujitsu)" <kuroda(dot)hayato(at)fujitsu(dot)com> |
|---|---|
| To: | 'Andrei Lepikhov' <lepihov(at)gmail(dot)com> |
| Cc: | PostgreSQL Hackers <pgsql-hackers(at)lists(dot)postgresql(dot)org> |
| Subject: | RE: Parallel Apply |
| Date: | 2025-12-18 10:34:49 |
| Message-ID: | OS7PR01MB1496878FFE96B9C4A350FA33BF5A8A@OS7PR01MB14968.jpnprd01.prod.outlook.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
Dear Andrei,
> > Yes, ideally parallel apply can reduce the lag, but note that it affects after
> > changes are reached to the subscriber. It may not be so effective if lag is
> > caused by the network. If your transaction is large and you did not enable the
> > streaming option, changing it to 'on' or 'parallel' can improve the lag.
> > It allows to replicate changes before huge transactions are committed.
>
> Sorry if I was inaccurate. I want to understand the scope of this
> feature: what benefit does the code provide to the current master in the
> case of async LR?
This feature, applying non-streaming transactions in parallel, can improve the
performance when many numbers of transactions are committed on the publisher side
and apply worker is a bottleneck.
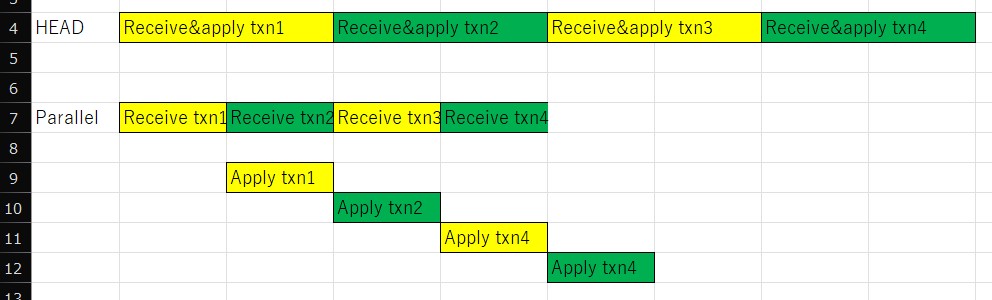
Please see the attached primitive diagram. Assuming receiving changes need one
time unit and applying changes also need a time unit. If leader does all tasks alone,
it needs eight time-units. But if there are parallel workers which apply changes
in parallel, leader can concentrate receiving items and reduce the total time.
I think this fact is not depends on whether it is the sync LR or not.
> Of course, it is a prerequisite to enable streaming
> and parallel apply - without these settings, your code is not working,
> is it?
Let me clarify. A subscription option 'streaming' affects how we handle large
transactions. 'on' means that large transactions can be streamed before the commit,
and it is stored on the subscriber side. 'parallel' also means transactions can
be streamed and it can be applied by the parallel workers.
Actually these options are not related with the proposal. This patch focuses on
the relatively small ones which are not streamed before committing.
> I just wonder if the main use case for this approach is synchronous
> commit and a good-enough network. Is it correct?
Both (a)-sync replication can work well.
But it might not so effective if the transporting data spent 90% of the time.
Leader would spend most of the same time with HEAD and the patched case.
Best regards,
Hayato Kuroda
FUJITSU LIMITED
| Attachment | Content-Type | Size |
|---|---|---|
|
image/jpeg | 56.4 KB |
In response to
- Re: Parallel Apply at 2025-12-18 08:44:33 from Andrei Lepikhov
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Alexander Korotkov | 2025-12-18 10:38:43 | Re: Implement waiting for wal lsn replay: reloaded |
| Previous Message | Jelte Fennema-Nio | 2025-12-18 10:27:05 | Re: RFC: adding pytest as a supported test framework |