Re: Speedup twophase transactions
| From: | Stas Kelvich <s(dot)kelvich(at)postgrespro(dot)ru> |
|---|---|
| To: | Simon Riggs <simon(at)2ndquadrant(dot)com> |
| Cc: | Andres Freund <andres(at)anarazel(dot)de>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com>, Jesper Pedersen <jesper(dot)pedersen(at)redhat(dot)com>, pgsql-hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Speedup twophase transactions |
| Date: | 2016-01-26 12:43:42 |
| Message-ID: | E7497864-DE11-4099-83F5-89FB97AF5073@postgrespro.ru |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
Hi,
Thanks for reviews and commit!
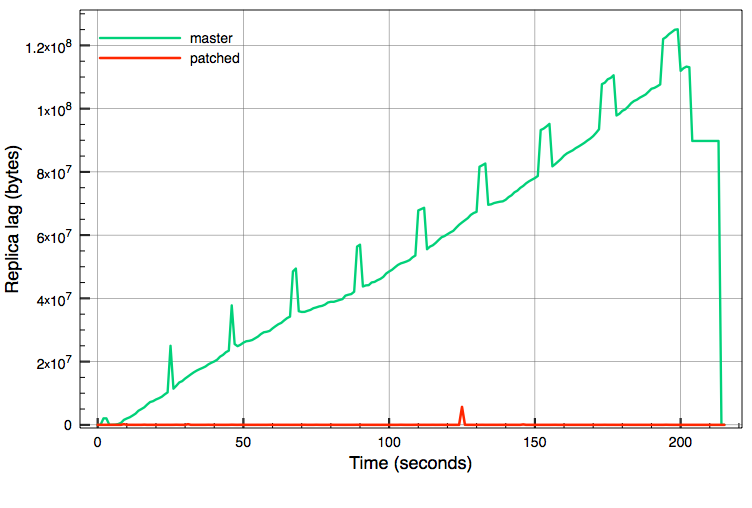
As Simon and Andres already mentioned in this thread replay of twophase transaction is significantly slower then the same operations in normal mode. Major reason is that each state file is fsynced during replay and while it is not a problem for recovery, it is a problem for replication. Under high 2pc update load lag between master and async replica is constantly increasing (see graph below).
One way to improve things is to move fsyncs to restartpoints, but as we saw previously it is a half-measure and just frequent calls to fopen can cause bottleneck.
Other option is to use the same scenario for replay that was used already for non-recovery mode: read state files to memory during replay of prepare, and if checkpoint/restartpoint occurs between prepare and commit move data to files. On commit we can read xlog or files. So here is the patch that implements this scenario for replay.
Patch is quite straightforward. During replay of prepare records RecoverPreparedFromXLOG() is called to create memory state in GXACT, PROC, PGPROC; on commit XlogRedoFinishPrepared() is called to clean up that state. Also there are several functions (PrescanPreparedTransactions, StandbyTransactionIdIsPrepared) that were assuming that during replay all prepared xacts have files in pg_twophase, so I have extended them to check GXACT too.
Side effect of that behaviour is that we can see prepared xacts in pg_prepared_xacts view on slave.
While this patch touches quite sensible part of postgres replay and there is some rarely used code paths, I wrote shell script to setup master/slave replication and test different failure scenarios that can happened with instances. Attaching this file to show test scenarios that I have tested and more importantly to show what I didn’t tested. Particularly I failed to reproduce situation where StandbyTransactionIdIsPrepared() is called, may be somebody can suggest way how to force it’s usage. Also I’m not too sure about necessity of calling cache invalidation callbacks during XlogRedoFinishPrepared(), I’ve marked this place in patch with 2REVIEWER comment.
Tests shows that this patch increases speed of 2pc replay to the level when replica can keep pace with master.
Graph: replica lag under a pgbench run for a 200 seconds with 2pc update transactions (80 connections, one update per 2pc tx, two servers with 12 cores each, 10GbE interconnect) on current master and with suggested patch. Replica lag measured with "select sent_location-replay_location as delay from pg_stat_replication;" each second.
| Attachment | Content-Type | Size |
|---|---|---|
|
image/png | 50.5 KB |
| unknown_filename | text/plain | 1 byte |
| twophase_replay.diff | application/octet-stream | 16.3 KB |
| check.sh | application/octet-stream | 8.0 KB |
| unknown_filename | text/plain | 10.0 KB |
In response to
- Re: Speedup twophase transactions at 2016-01-12 19:57:45 from Simon Riggs
Responses
- Re: Speedup twophase transactions at 2016-01-26 17:20:30 from Alvaro Herrera
- Re: Speedup twophase transactions at 2016-03-11 16:41:03 from Jesper Pedersen
- Re: Speedup twophase transactions at 2016-04-08 18:42:28 from Robert Haas
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Vitaly Burovoy | 2016-01-26 12:48:07 | Re: custom function for converting human readable sizes to bytes |
| Previous Message | Masahiko Sawada | 2016-01-26 12:33:24 | Existence check for suitable index in advance when concurrently refreshing. |