Re: pgbench - allow to create partitioned tables
| From: | Fabien COELHO <coelho(at)cri(dot)ensmp(dot)fr> |
|---|---|
| To: | Simon Riggs <simon(at)2ndquadrant(dot)com> |
| Cc: | PostgreSQL Developers <pgsql-hackers(at)lists(dot)postgresql(dot)org> |
| Subject: | Re: pgbench - allow to create partitioned tables |
| Date: | 2019-07-24 22:26:34 |
| Message-ID: | alpine.DEB.2.21.1907242215210.8640@lancre |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
>>> # and look at latency:
>>> # no parts = 0.071 ms
>>> # 1 hash = 0.071 ms (did someone optimize this case?!)
>>> # 2 hash ~ 0.126 ms (+ 0.055 ms)
>>> # 50 hash ~ 0.155 ms
>>> # 100 hash ~ 0.178 ms
>>> # 150 hash ~ 0.232 ms
>>> # 200 hash ~ 0.279 ms
>>> # overhead ~ (0.050 + [0.0005-0.0008] * nparts) ms
>>
>> It is linear?
>
> Good question. I would have hoped affine, but this is not very clear on these
> data, which are the median of about five runs, hence the bracket on the slope
> factor. At least it is increasing with the number of partitions. Maybe it
> would be clearer on the minimum of five runs.
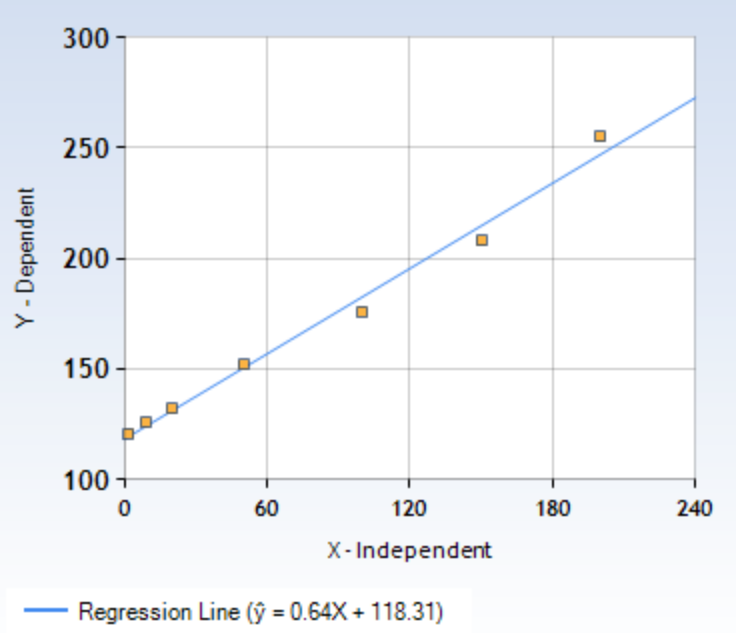
Here is a fellow up.
On the minimum of all available runs the query time on hash partitions is
about:
0.64375 nparts + 118.30979 (in µs).
So the overhead is about 47.30979 + 0.64375 nparts, and it is indeed
pretty convincingly linear as suggested by the attached figure.
--
Fabien.
| Attachment | Content-Type | Size |
|---|---|---|
|
image/png | 39.8 KB |
In response to
- Re: pgbench - allow to create partitioned tables at 2019-07-24 08:23:44 from Fabien COELHO
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | David Rowley | 2019-07-24 22:36:26 | Re: Statistical aggregate functions are not working with PARTIAL aggregation |
| Previous Message | Peter Geoghegan | 2019-07-24 22:06:13 | Re: [HACKERS] [WIP] Effective storage of duplicates in B-tree index. |