| From: | Alexander Korotkov <a(dot)korotkov(at)postgrespro(dot)ru> |
|---|---|
| To: | Dmitry Dolgov <9erthalion6(at)gmail(dot)com> |
| Cc: | pgsql-hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: WIP: "More fair" LWLocks |
| Date: | 2018-12-13 21:11:43 |
| Message-ID: | CAPpHfduV3v3EG7K74-9htBZz_mpE993zGz-=2k5RNA3tqabUAA@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
On Mon, Oct 15, 2018 at 7:06 PM Alexander Korotkov
<a(dot)korotkov(at)postgrespro(dot)ru> wrote:
> I'm going to continue my experiments. I would like to have something
> like 4th version of patch, but without extra atomic instructions. May
> be by placing number of sequential shared lockers past into separate
> (non-atomic) variable. The feedback is welcome.
I did try this in 6th version of patch. Now number of shared lwlocks
taken in a row is stored in usagecount field of LWLock struct. Thus,
this patch doesn't introduce more atomic operations, because
usagecount field is not atomic. Also, size of LWLock struct didn't
grow, because usagecount takes place of struct padding. Since
usagecount is not atomic, it might happens that increment and setting
to zero operations overlap together. In this case, setting to zero
can appear to be ignored. But that's not catastrophic, because in
that case LWLock will just switch to fair more sooner than it normally
should. Also, I turn number of sequential shared lwlocks taken before
switching to fair mode into a lwlock_shared_limit GUC. Zero disables
fair mode completely.
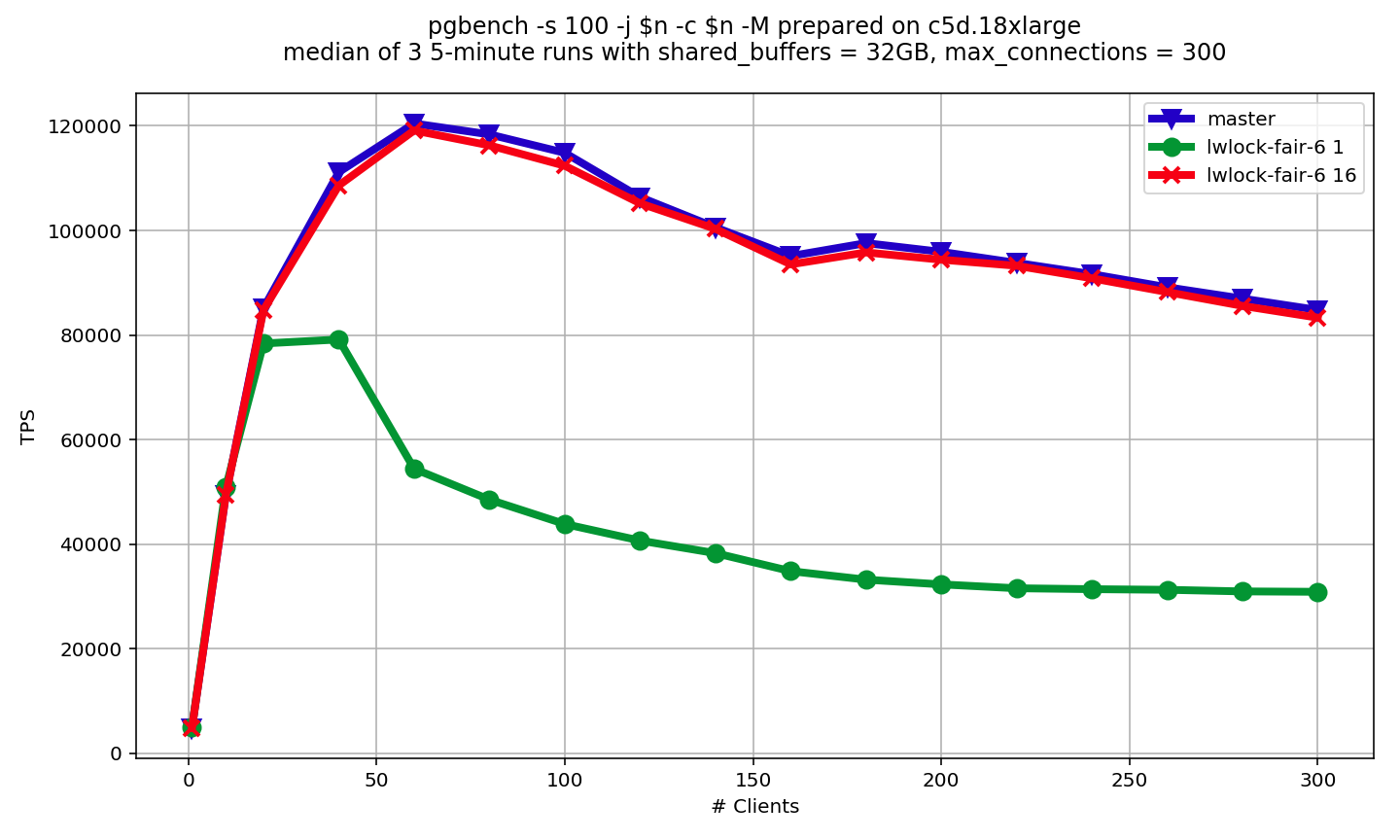
Results of pgbench scalability benchmark is attached, With
lwlock_shared_limit = 16, no LWLocks are switched to fair mode in the
benchmark. However, there is still small overhead. I think it's
related to extra cacheline invalidation caused by access to usagecount
variable. So, I probably did my best in this direction. For now, I
don't have any idea of how to make overhead of "fair mode"
availability lower.
We (Postgres Pro) found this patch useful and integrated it into our
proprietary fork. In my opinion PostgreSQL would also benefit from
this patch, because it can dramatically improve the situation on some
NUMA systems. Also, this feature is controlled by GUC. So,
lwlock_shared_limit = 0 completely disables it, and there is no
measurable overhead. Any thoughts?
------
Alexander Korotkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
| Attachment | Content-Type | Size |
|---|---|---|
| lwlock-fair-6-rw.png | image/png | 105.5 KB |
| lwlock-fair-6.patch | application/x-patch | 13.8 KB |
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Andrew Gierth | 2018-12-13 21:24:21 | Re: Ryu floating point output patch |
| Previous Message | Andrew Gierth | 2018-12-13 21:01:22 | Re: Ryu floating point output patch |
{kind=link}