Re: Slow standby snapshot
| From: | Michail Nikolaev <michail(dot)nikolaev(at)gmail(dot)com> |
|---|---|
| To: | Simon Riggs <simon(dot)riggs(at)enterprisedb(dot)com> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Andres Freund <andres(at)anarazel(dot)de>, Andrey Borodin <x4mmm(at)yandex-team(dot)ru>, Kyotaro Horiguchi <horikyota(dot)ntt(at)gmail(dot)com>, Alexander Korotkov <aekorotkov(at)gmail(dot)com>, reshkekirill <reshkekirill(at)gmail(dot)com>, PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Slow standby snapshot |
| Date: | 2022-11-22 21:53:33 |
| Message-ID: | CANtu0ogpTvOtQgpQbKmHYjst6XBHowyHRhBHkN-54uoPOD4drw@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
Hello, everyone.
I have tried to put it all together.
> In the absence of that approach, falling back to a counter that
> compresses every N xids would be best, in addition to the two new
> forced compression events.
Done.
> Also, if we add more forced compressions, it seems like we should have
> a short-circuit for a forced compression where there's nothing to do.
Done.
> I'm also wondering why there's not an
>
> Assert(compress_index == pArray->numKnownAssignedXids);
>
> after the loop, to make sure our numKnownAssignedXids tracking
> is sane.
Done.
> * when idle - since we have time to do it when that happens, which
> happens often since most workloads are bursty
I have added getting of ProcArrayLock for this case.
Also, I have added maximum frequency as 1 per second to avoid
contention with heavy read load in case of small,
episodic but regular WAL traffic (WakeupRecovery() for each 100ms for
example). Or it is useless?
> It'd be more reliable
> to use a static counter to skip all but every N'th compress attempt
> (something we could do inside KnownAssignedXidsCompress itself, instead
> of adding warts at the call sites).
Done. I have added “reason” enum for calling KnownAssignedXidsCompress
to keep it as much clean as possible.
But not sure that I was successful here.
Also, I think while we still in the context, it is good to add:
* Simon's optimization (1) for KnownAssignedXidsRemoveTree (it is
simple and effective for some situations without any seen drawbacks)
* Maybe my patch (2) for replacing known_assigned_xids_lck with memory barrier?
New version in attach. Running benchmarks now.
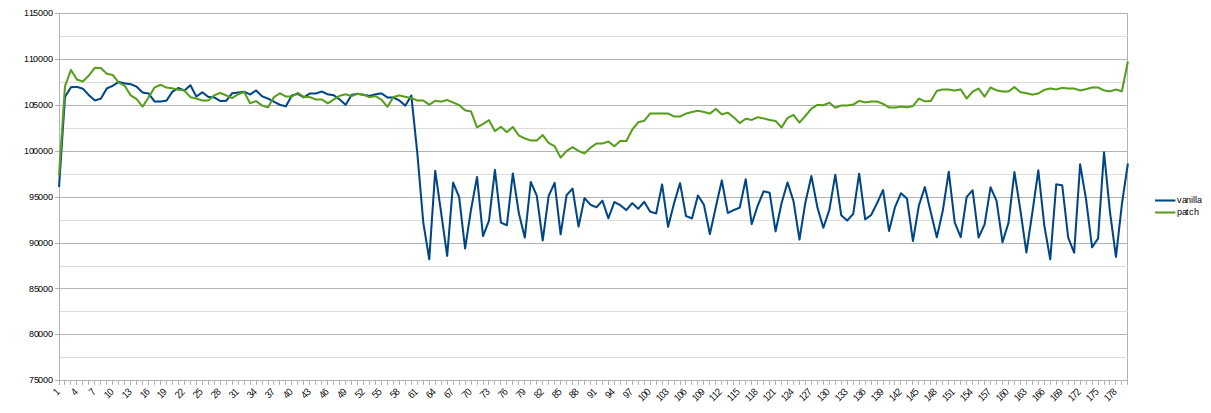
Preliminary result in attachments (16CPU, 5000 max_connections, now 64
active connections instead of 16).
Also, interesting moment - with 64 connections, vanilla version is
unable to recover its performance after 30-sec transaction on primary.
[1]: https://www.postgresql.org/message-id/flat/CANbhV-Ey8HRYPvnvQnsZAteCfzN3VHVhZVKfWMYcnjMnSzs4dQ%40mail.gmail.com#05993cf2bc87e35e0dff38fec26b9805
[2]: https://www.postgresql.org/message-id/flat/CANtu0oiPoSdQsjRd6Red5WMHi1E83d2%2B-bM9J6dtWR3c5Tap9g%40mail.gmail.com#cc4827dee902978f93278732435e8521
--
Michail Nikolaev
| Attachment | Content-Type | Size |
|---|---|---|
| vnext-0001-Currently-KnownAssignedXidsGetAndSetXmin-requi.patch | text/x-patch | 8.9 KB |
|
image/png | 66.8 KB |
In response to
- Re: Slow standby snapshot at 2022-11-22 17:06:40 from Simon Riggs
Responses
- Re: Slow standby snapshot at 2022-11-28 07:19:31 from Michail Nikolaev
- Re: Slow standby snapshot at 2022-11-28 21:29:27 from Tom Lane
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | David Rowley | 2022-11-22 21:58:07 | Re: Prefetch the next tuple's memory during seqscans |
| Previous Message | Andres Freund | 2022-11-22 20:53:09 | Re: Introduce a new view for checkpointer related stats |