| From: | Nataliia <k(dot)natalissa(at)gmail(dot)com> |
|---|---|
| To: | D Laaren <dlaaren8(at)gmail(dot)com> |
| Cc: | pgsql-hackers(at)lists(dot)postgresql(dot)org |
| Subject: | Re: Timeline switching with partial WAL records can break replica recovery |
| Date: | 2025-09-04 08:40:47 |
| Message-ID: | CANbKXii0VsaEcxkd4m1Es_uJoX8D7BAZSVg1+wTVWhxGV8MOkA@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
On Thu, Sep 4, 2025 at 1:33 PM D Laaren <dlaaren8(at)gmail(dot)com> wrote:
> [FIX] Timeline switching with partial WAL records can break replica recovery
>
> Hi Hackers,
>
> I've encountered an issue where physical replicas may enter an infinite WAL
> request loop under the following conditions:
> 1. A promotion occurs during a multi-block WAL record write.
Hi everyone,
I would like to reinforce the need for this fix because I've encountered
another critical failure related to timeline switching with contrecord. In my
case in cascading replication.
Configuration: Primary -> Upstream-Replica -> Downstream-Replica
Scenario that caused a problem:
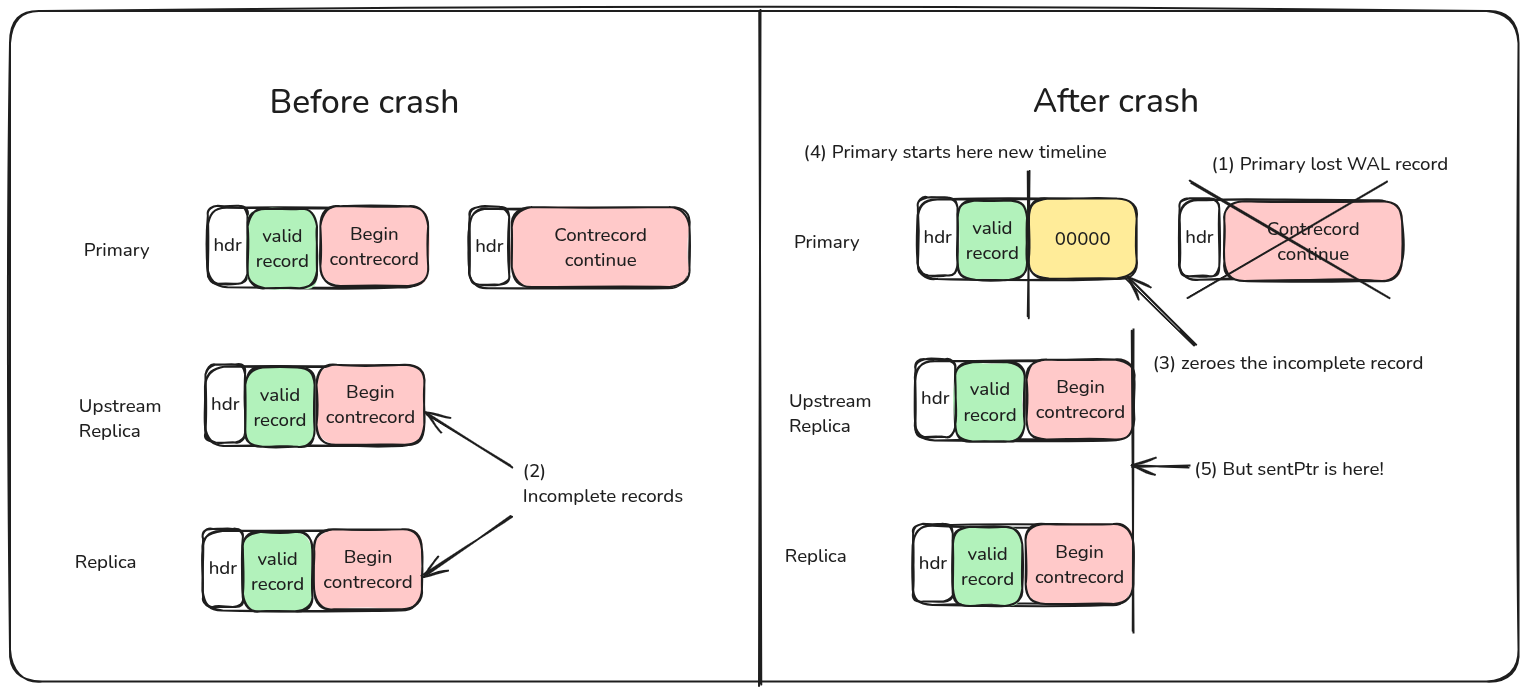
1. The primary is abruptly shut down during a multi-block WAL write.
2. Replicas received an incomplete multi-block WAL record
3. The primary zeroes the incomplete record but does not write
XLOG_OVERWRITE_CONTRECORD because it is going to switch to the new TLI
4. The primary switches timeline at the point of the incomplete
record, not after it
5. The Upstream-Replica's walreceiver processes the new timeline and rewrites
its WAL. However, its cascading walsender is unaware of this underlying
change and attempts to send data it has already sent to Downstream-Replica,
triggering an Assert.
I've attached an illustration of the WAL records on instances for better
understanding. Also I've attached a TAP test that reproduces this behaviour.
The test reproduces the issue by directly removing a WAL file to simulate
the corrupted state. In a real-world scenario, I encountered this situation
through normal replication.
Symptom: Assert in walsender.c on Upstream-Replica
-------
TRAP: failed Assert("sentPtr <= SendRqstPtr")
-------
This is an important issue to fix. While the assertion will crash a debug
build, a production build would continue, potentially causing the downstream
replica to receive corrupted or divergent WAL data.
In the scenario above, if we continue to insert data on the primary, it can
lead to a panic on replica:
-------
PANIC: could not open file "pg_wal/000000020000000000000001": No such
file or directory
-------
This panic is arguably the best outcome right now, as it stops the system
before more severe data corruption can accumulate.
> == Proposed Solution ==
> I propose preserving WAL's append-only linear nature by graceful handling of
> incomplete records during timeline switches:
> 1. Timeline Finalization:
> Before switching timelines write an XLOG_OVERWRITE_CONTRECORD record to
> mark the incomplete record in the current timeline. Only then initialize the
> new timeline and continue recovery. Since no concurrent WAL writes can occur
> during this phase, the operation is safe.
This solution repairs the situation above. On one hand, it might seem that
the walsender's code needs to change to be aware of such switches. However,
I believe the patch proposed in this thread is the better decision because
it addresses the root cause.
Best regards,
Nataliia Kokunina
| Attachment | Content-Type | Size |
|---|---|---|
| v1-0002-scenario_wal_divergence.png | image/png | 129.4 KB |
| v1-0001-assert_in_cascade_walsender.pl | text/x-perl | 3.3 KB |
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Paul Ohlhauser | 2025-09-04 08:59:36 | Re: [PG19-3 PATCH] Don't ignore passfile |
| Previous Message | Richard Guo | 2025-09-04 08:21:10 | Re: plan shape work |
{kind=link}