Re: Improve WALRead() to suck data directly from WAL buffers when possible
| From: | Bharath Rupireddy <bharath(dot)rupireddyforpostgres(at)gmail(dot)com> |
|---|---|
| To: | Andres Freund <andres(at)anarazel(dot)de> |
| Cc: | Jeff Davis <pgsql(at)j-davis(dot)com>, Dilip Kumar <dilipbalaut(at)gmail(dot)com>, Kyotaro Horiguchi <horikyota(dot)ntt(at)gmail(dot)com>, pgsql-hackers(at)lists(dot)postgresql(dot)org, SATYANARAYANA NARLAPURAM <satyanarlapuram(at)gmail(dot)com> |
| Subject: | Re: Improve WALRead() to suck data directly from WAL buffers when possible |
| Date: | 2023-01-26 05:33:28 |
| Message-ID: | CALj2ACV6rS+7iZx5+oAvyXJaN4AG-djAQeM1mrM=YSDkVrUs7g@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
On Thu, Jan 26, 2023 at 2:45 AM Andres Freund <andres(at)anarazel(dot)de> wrote:
>
> Hi,
>
> On 2023-01-14 12:34:03 -0800, Andres Freund wrote:
> > On 2023-01-14 00:48:52 -0800, Jeff Davis wrote:
> > > On Mon, 2022-12-26 at 14:20 +0530, Bharath Rupireddy wrote:
> > > > Please review the attached v2 patch further.
> > >
> > > I'm still unclear on the performance goals of this patch. I see that it
> > > will reduce syscalls, which sounds good, but to what end?
> > >
> > > Does it allow a greater number of walsenders? Lower replication
> > > latency? Less IO bandwidth? All of the above?
> >
> > One benefit would be that it'd make it more realistic to use direct IO for WAL
> > - for which I have seen significant performance benefits. But when we
> > afterwards have to re-read it from disk to replicate, it's less clearly a win.
>
> Satya's email just now reminded me of another important reason:
>
> Eventually we should add the ability to stream out WAL *before* it has locally
> been written out and flushed. Obviously the relevant positions would have to
> be noted in the relevant message in the streaming protocol, and we couldn't
> generally allow standbys to apply that data yet.
>
> That'd allow us to significantly reduce the overhead of synchronous
> replication, because instead of commonly needing to send out all the pending
> WAL at commit, we'd just need to send out the updated flush position. The
> reason this would lower the overhead is that:
>
> a) The reduced amount of data to be transferred reduces latency - it's easy to
> accumulate a few TCP packets worth of data even in a single small OLTP
> transaction
> b) The remote side can start to write out data earlier
>
>
> Of course this would require additional infrastructure on the receiver
> side. E.g. some persistent state indicating up to where WAL is allowed to be
> applied, to avoid the standby getting ahead of th eprimary, in case the
> primary crash-restarts (or has more severe issues).
>
>
> With a bit of work we could perform WAL replay on standby without waiting for
> the fdatasync of the received WAL - that only needs to happen when a) we need
> to confirm a flush position to the primary b) when we need to write back pages
> from the buffer pool (and some other things).
Thanks Andres, Jeff and Satya for taking a look at the thread. Andres
is right, the eventual plan is to do a bunch of other stuff as
described above and we've discussed this in another thread (see
below). I would like to once again clarify motivation behind this
feature:
1. It enables WAL readers (callers of WALRead() - wal senders,
pg_walinspect etc.) to use WAL buffers as first level cache which
might reduce number of IOPS at a peak load especially when the pread()
results in a disk read (WAL isn't available in OS page cache). I had
earlier presented the buffer hit ratio/amount of pread() system calls
reduced with wal senders in the first email of this thread (95% of the
time wal senders are able to read from WAL buffers without impacting
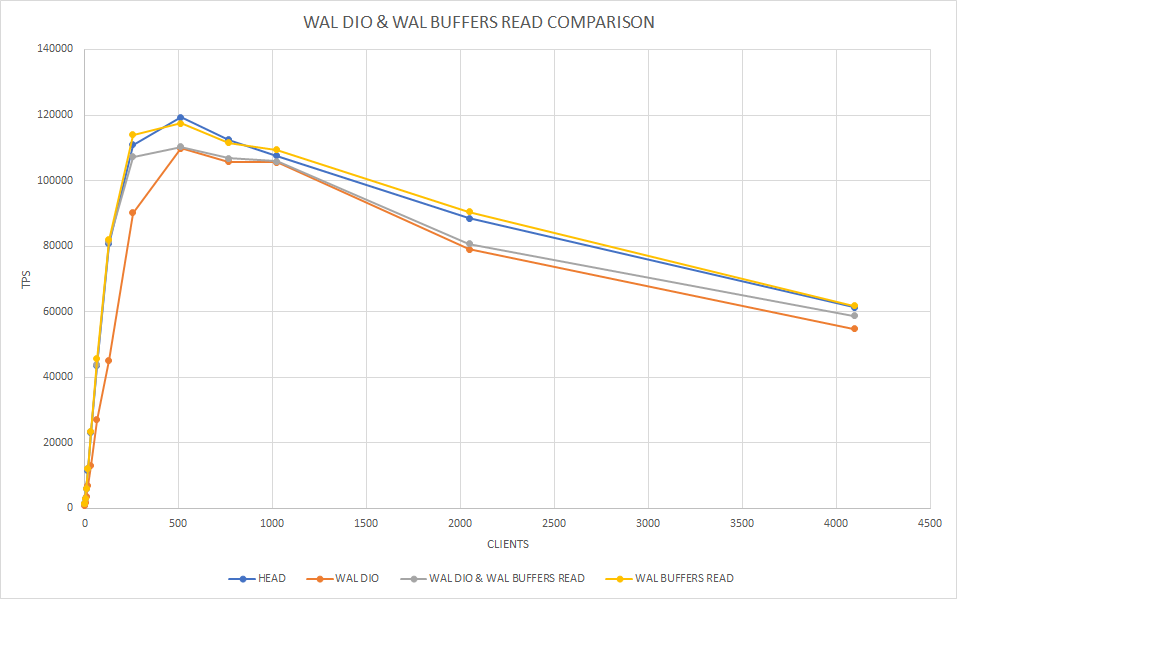
anybody). Now, here are the results with the WAL DIO patch [1] - where
WAL pread() turns into a disk read, see the results [2] and attached
graph.
2. As Andres rightly mentioned, it helps WAL DIO; since there's no OS
page cache, using WAL buffers as read cache helps a lot. It is clearly
evident from my experiment with WAL DIO patch [1], see the results [2]
and attached graph. As expected, WAL DIO brings down the TPS, whereas
WAL buffers read i.e. this patch brings it up.
3. As Andres rightly mentioned above, it enables flushing WAL in
parallel on primary and all standbys [3]. I haven't yet started work
on this, I will aim for PG 17.
4. It will make the work on - disallow async standbys or subscribers
getting ahead of the sync standbys [3] possible. I haven't yet started
work on this, I will aim for PG 17.
5. It implements the following TODO item specified near WALRead():
* XXX probably this should be improved to suck data directly from the
* WAL buffers when possible.
*/
bool
WALRead(XLogReaderState *state,
That said, this feature is separately reviewable and perhaps can go
separately as it has its own benefits.
[2] Test case is an insert pgbench workload.
clients HEAD WAL DIO WAL DIO & WAL BUFFERS READ WAL BUFFERS READ
1 1404 1070 1424 1375
2 1487 796 1454 1517
4 3064 1743 3011 3019
8 6114 3556 6026 5954
16 11560 7051 12216 12132
32 23181 13079 23449 23561
64 43607 26983 43997 45636
128 80723 45169 81515 81911
256 110925 90185 107332 114046
512 119354 109817 110287 117506
768 112435 105795 106853 111605
1024 107554 105541 105942 109370
2048 88552 79024 80699 90555
4096 61323 54814 58704 61743
[3]
https://www.postgresql.org/message-id/20220309020123.sneaoijlg3rszvst@alap3.anarazel.de
https://www.postgresql.org/message-id/CALj2ACXCSM%2BsTR%3D5NNRtmSQr3g1Vnr-yR91azzkZCaCJ7u4d4w%40mail.gmail.com
--
Bharath Rupireddy
PostgreSQL Contributors Team
RDS Open Source Databases
Amazon Web Services: https://aws.amazon.com
| Attachment | Content-Type | Size |
|---|---|---|
|
image/png | 43.1 KB |
In response to
- Re: Improve WALRead() to suck data directly from WAL buffers when possible at 2023-01-25 21:15:40 from Andres Freund
Responses
- Re: Improve WALRead() to suck data directly from WAL buffers when possible at 2023-01-27 05:24:51 from Masahiko Sawada
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Michael Paquier | 2023-01-26 05:49:27 | Re: Add LZ4 compression in pg_dump |
| Previous Message | Michael Paquier | 2023-01-26 04:46:54 | Re: Add LZ4 compression in pg_dump |