| From: | Jakub Wartak <jakub(dot)wartak(at)enterprisedb(dot)com> |
|---|---|
| To: | Andres Freund <andres(at)anarazel(dot)de> |
| Cc: | Nazir Bilal Yavuz <byavuz81(at)gmail(dot)com>, Jacob Champion <jacob(dot)champion(at)enterprisedb(dot)com>, Jelte Fennema-Nio <postgres(at)jeltef(dot)nl>, Thomas Munro <thomas(dot)munro(at)gmail(dot)com>, pgsql-hackers(at)postgresql(dot)org, Zsolt Parragi <zsolt(dot)parragi(at)percona(dot)com>, Peter Eisentraut <peter(at)eisentraut(dot)org> |
| Subject: | Re: Heads Up: cirrus-ci is shutting down June 1st |
| Date: | 2026-06-11 09:04:29 |
| Message-ID: | CAKZiRmw1XVmBzJxFY3uZStURL3OU-a5Ty_iJT5-on5e7dzQq1g@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
On Wed, Jun 10, 2026 at 4:12 PM Andres Freund <andres(at)anarazel(dot)de> wrote:
> Hi,
>
> On 2026-06-10 13:13:49 +0200, Jakub Wartak wrote:
> > On Tue, Jun 9, 2026 at 2:14 PM Andres Freund <andres(at)anarazel(dot)de> wrote:
> > > On 2026-06-09 12:32:31 +0200, Jakub Wartak wrote:
> > > > And I've bumped TEST_JOBS 4->8 (even with 4 VCPUs), because my local
> > runs
> > > > showed in taskmgr that after quite some time we have ended up using
just
> > > > ~40% CPU (also with 4 VCPUs) while not doing I/O (this is somehow
> > contrary
> > > > to what Andres was stating earlier).
> > >
> > > FWIW, I only measured this for linux, not for windows. On linux it was
> > easy to
> > > do
> > >
> > > + vmstat -y -n -w 1 > vmstat.log &
> > > +
> > > + meson test ${{env.MTEST_ARGS}} --num-processes
> > ${{env.TEST_JOBS}} --no-suite setup ${{env.MTEST_TARGET}}
> > > +
> > > + killall iostat vmstat || true
> > > +
> > > + - name: Upload stats
> > > +uses: actions/upload-artifact(at)v7
> > > +with:
> > > + path: |
> > > +iostat.log
> > > +vmstat.log
> > >
> > > Which showed that there is very little idle CPU other than during
first
> > few
> > > seconds and at the end.
> [..]
> > Attached are: patch how it was gathered, raw CSV data, and most
importantly
> > graph.
>
> Looking at the raw data, I think something must not be quite right. Note
how
> low the absolute read/write IO numbers are. Is it possible that that's
for the
> C:/ disk, but that we're doing IO on D:/?
It's "_Total", so should include everything. That would mean we are doing
I/O
somewhere.
> How exctly did you translate the csv data to %cpu utilization?
It's raw, and ""% Processor Time shows the total percentage of processor
utilization across all processes."
> > We were both right and wrong. It is either CPU bottleneck, but also
> > if the I/O is involved the CPU drops to <20% in case of runner #1 (same
> > happens with runner#2 but for short time of 2 mins). Pretty much had
> > similiar local Windows behavior.
>
> Kinda looks like what we might want is to increase the times / amounts
> equivalent to
>
/proc/sys/vm/{dirty_expire_centisecs,dirty_writeback_centisecs,dirty_background_ratio,dirty_ratio}
>
> But due to the issue mentioned above, I'm not sure we can conclude that
much
> yet.
I've searched GH issues and there are hundreths of people complaining
(and dozes of issues) that Windows is simply slower especially if I/O is
involved. I found this link [1] which is short and nice summary of those
issues. It has ready to use recipes, so I've used one for RAM disk
:rotfl: (on more serious note: I wanted to make it GH env "fast_noIO"=true
if not chaning anything to IO/fs), but ...:
- 'Test world' alone took 12min + 16min (so thats 2 runners each with
4VCPUs)
- and that was NOT much faster than normal than we had yesterday on D:\
(and this was with R:\build on ramdisk, sic!)
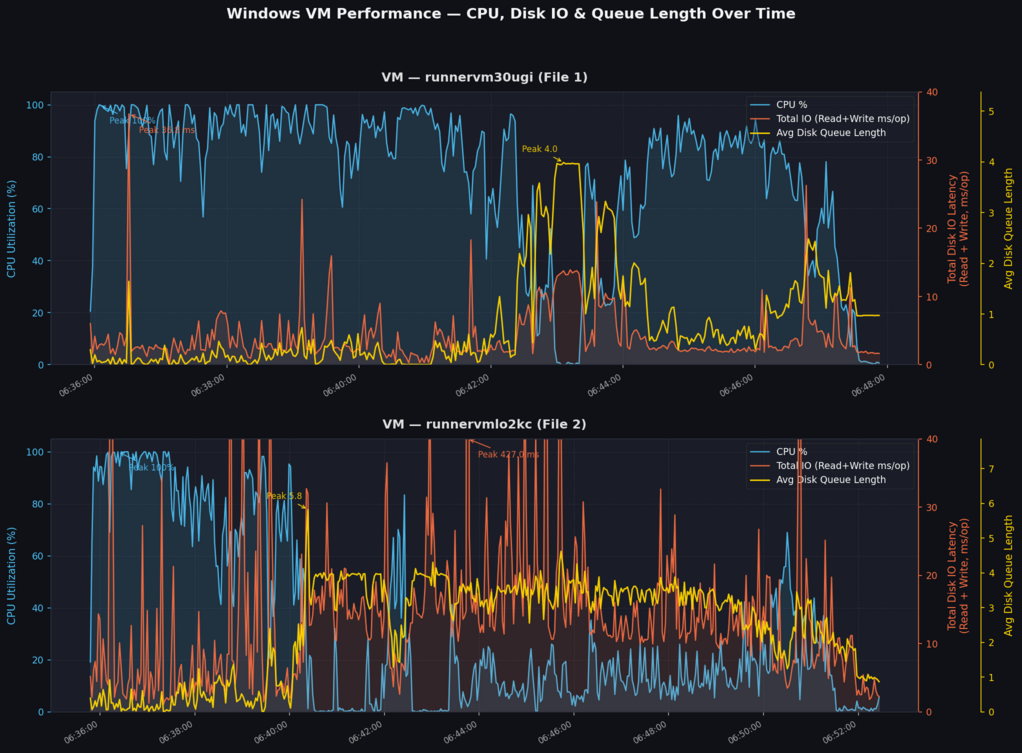
- along the way I've captured metrics (attached) + graphs (see ..totals.jpg
first), so we were are still IDLE on CPU when doing some I/O (_Total),
but this is not I/O for ramdisk as one cannot have 10ms+ IO on ramdisk
all the time, right? (not to mention those peaks to 400ms+)
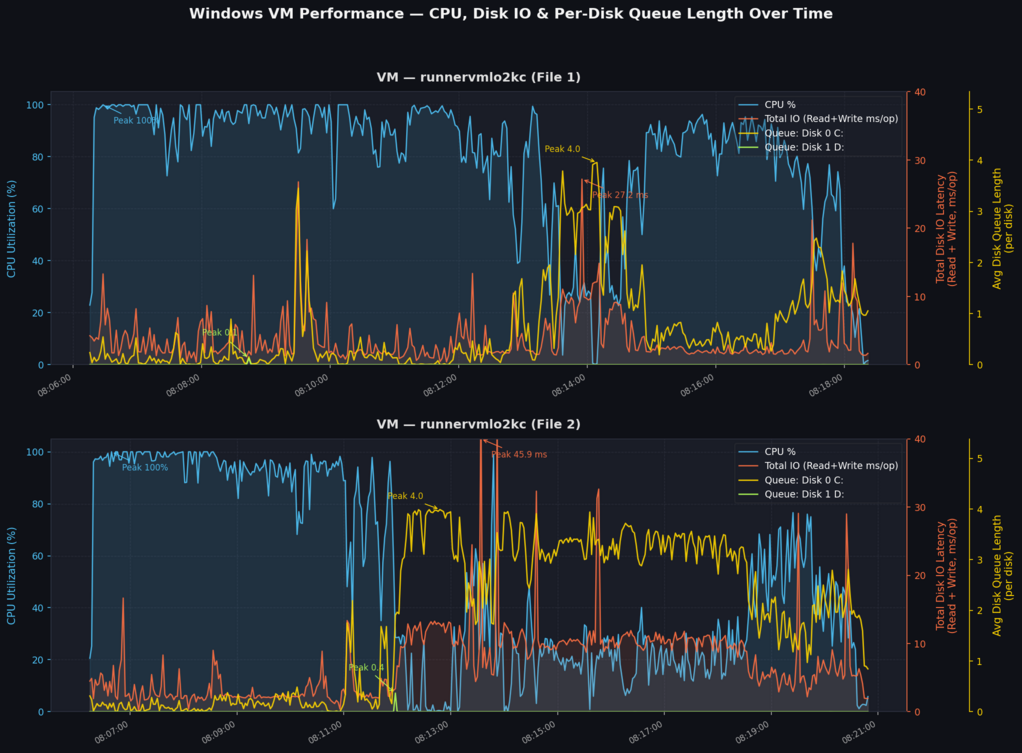
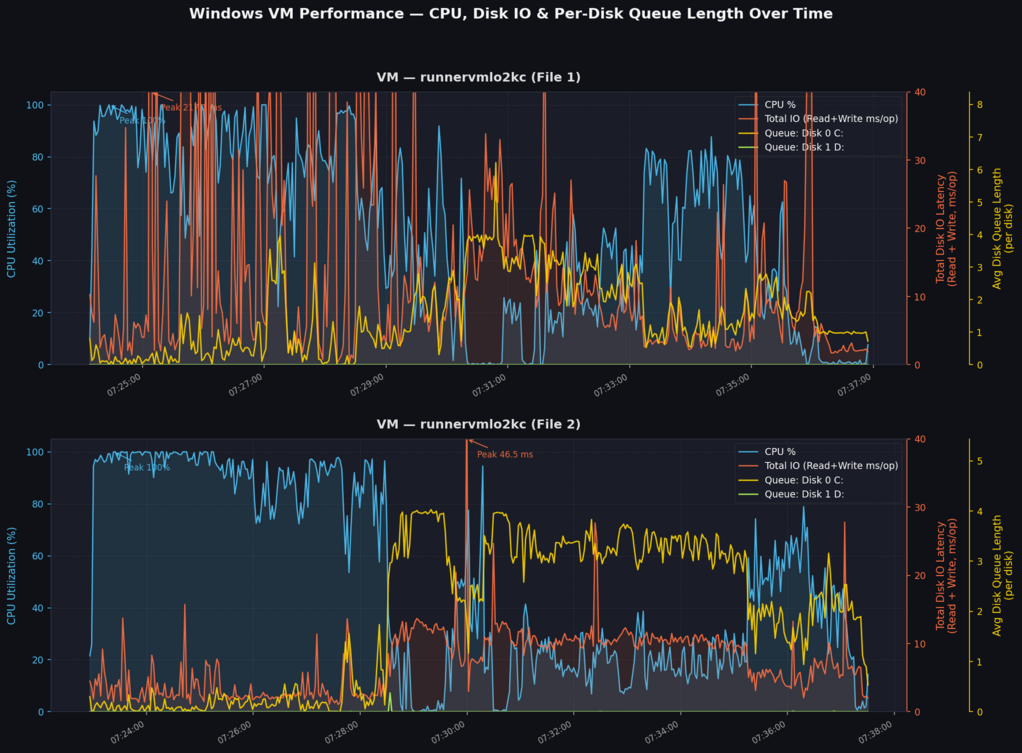
- so I've collected more detailed per-disk IO data (_Total, but also "*")
using attached patch
- and if you look at the second graph we are doing I/O on __very__ slow C:
when are __slow__ during tests and that correlates with low CPU usage, so
something is being used on C: is slowing us down to crawl
- I thrown 3rd run to collect per-process I/O into that CSV and later thrown
that onto Claude to find cross-corellation between processes doing lots
of
I/O, it confirmed, but didnt find anything specific:
Your hypothesis is confirmed — but the cause isn't what you'd expect
CPU and C: queue length are almost perfectly inversely correlated (r =
‑0.947).The clearest stretch is 08:12:09–08:13:09, where the C: queue
pins at ~3.9–4.0 while CPU collapses toward 0%. There are weaker
recurrences through ~08:18. But when I rank processes by actual I/O
on C: during those exact windows, nobody is moving meaningful volume:
[..slop mentioning everything a bit, including system-writeback and
Azure throttling]
- btw: I've set TMP and TEMP to d:\wintmp and it did not help and I'm not
Windows expert at all, but something there is borked and at least
it's clear what (pagefile is already on D:)
To sum up, to me it looks like we are losing ~60..70% of compute on
Window due to that slow C: being issue, but I have to stop here.
> > IMHO *if* we want to push that faster it would make some sense to
eliminate
> > that I/O (but after observing that matrix split trich I'm not so sure
if it
> > is worth investing more into it). We seem to drop CPU use every time the
> > avg disk queue len >= 2.
>
> I'm not that concerned about the VS runtime right now, due to the split,
but
> mingw very frequently is the slowest task (with an empty / inapplicable
cache
> it's compilerwarnings, but I have some pending improvements for that, by
> converting it to meson the worst case time halves). We can't just split
all
> tasks, that uses too many of the available "job slots".
>
>
> > Or maybe offload that and ask GH folks to provide images with XFS and
ReFS
> > on D:\ by default instead ?
>
> I suspect that will be a very heavy lift. That'd be a large change and
there
> are lot of users of this stuff.
>
> It's probably worth seeing what the times with a newer windows image are,
> before we do much more.
Simplest tweak s/windows-2022/windows-2025/ says:
Run-time dependency openssl found: NO (tried pkg-config and system)
meson.build:1645:17: ERROR: C header 'openssl/ssl.h' not found
I remember we have installed openssl in previous CI patches, but not on what
is right now on master, dunno, I haven't pressed harder.
> > Alvaro had an idea here in [1] about instance reusing.
>
> We have the ability to run instances against a running cluster already,
but
> only use that in one place. I was wondering about a meson test "setup"
that
> will only run tests that can *not* be run against a running instance.
>
> With a bit of additional scripting (we need the ability to set
LD_LIBRARY_PATH
> in a cross platform, we have that in a bunch of places, just need to
expose
> it), that'd allow us to convert all the meson based tests to use the
running
> tests, and all the tests that don't support that, without duplication
between
> the runs.
it kind of sounds like black-magic wizardy to me, and that LD_LIBRARY_PATH
there, sorry, I'm not following , to override which libs? (not sure how
that's
supposed to work) :)
> It's not really a fair comparison (due to what's running concurrently),
but
> here's the time for a few tests in running and a dedicated cluster:
>
> 70/398 postgresql:bloom / bloom/regress OK1.97s 1 subtests passed
> 6/88 postgresql:bloom-running / bloom-running/regress OK0.54s 1
subtests passed
>
> 68/398 postgresql:auto_explain / auto_explain/regress OK1.96s 2
subtests passed
> 5/88 postgresql:auto_explain-running / auto_explain-running/regress
OK0.33s 2 subtests passed
>
> 77/398 postgresql:cube / cube/regress OK2.27s 2 subtests passed
> 11/88 postgresql:cube-running / cube-running/regress OK0.84s 2
subtests passed
>
> Clearly we could gain some if we we didn't run the tests that supported
> running against an existing cluster against separate clusters each.
... That's like 3x-4x :o
-J.
[1] -
https://chadgolden.com/blog/github-actions-hosted-windows-runners-slower-than-expected-ci-and-you
| Attachment | Content-Type | Size |
|---|---|---|
| system_perf_cpu_vs_io_ramdisk_totals.png | image/png | 401.2 KB |
| v2-0001-Measure-Windows-CPU-usage-during-tests-poor-man-s.patch | text/x-patch | 5.1 KB |
| system_perf_cpu_vs_io_perdisk2.png | image/png | 388.7 KB |
| system_perf_cpu_vs_io_perdisk.png | image/png | 427.0 KB |
| csvs.zip | application/zip | 353.1 KB |
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Amit Langote | 2026-06-11 09:05:34 | Re: PG19 FK fast path: OOB write and missed FK checks during batched |
| Previous Message | Srinath Reddy Sadipiralla | 2026-06-11 09:01:38 | Re: First draft of PG 19 release notes |
{kind=link}
{kind=link}
{kind=link}