| From: | Manni Wood <manni(dot)wood(at)enterprisedb(dot)com> |
|---|---|
| To: | Nazir Bilal Yavuz <byavuz81(at)gmail(dot)com> |
| Cc: | KAZAR Ayoub <ma_kazar(at)esi(dot)dz>, Mark Wong <markwkm(at)gmail(dot)com>, Nathan Bossart <nathandbossart(at)gmail(dot)com>, Andrew Dunstan <andrew(at)dunslane(dot)net>, Shinya Kato <shinya11(dot)kato(at)gmail(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Speed up COPY FROM text/CSV parsing using SIMD |
| Date: | 2026-01-06 20:05:05 |
| Message-ID: | CAKWEB6qQmPejLwndzMcVqhO+u9vgUf44kYAKg4QtyG-=KH=YGg@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
On Wed, Dec 31, 2025 at 7:04 AM Nazir Bilal Yavuz <byavuz81(at)gmail(dot)com>
wrote:
> Hi,
>
> On Wed, 24 Dec 2025 at 18:08, KAZAR Ayoub <ma_kazar(at)esi(dot)dz> wrote:
> >
> > Hello,
> > Following the same path of optimizing COPY FROM using SIMD, i found that
> COPY TO can also benefit from this.
> >
> > I attached a small patch that uses SIMD to skip data and advance as far
> as the first special character is found, then fallback to scalar processing
> for that character and re-enter the SIMD path again...
> > There's two ways to do this:
> > 1) Essentially we do SIMD until we find a special character, then
> continue scalar path without re-entering SIMD again.
> > - This gives from 10% to 30% speedups depending on the weight of special
> characters in the attribute, we don't lose anything here since it advances
> with SIMD until it can't (using the previous scripts: 1/3, 2/3 specials
> chars).
> >
> > 2) Do SIMD path, then use scalar path when we hit a special character,
> keep re-entering the SIMD path each time.
> > - This is equivalent to the COPY FROM story, we'll need to find the same
> heuristic to use for both COPY FROM/TO to reduce the regressions (same
> regressions: around from 20% to 30% with 1/3, 2/3 specials chars).
> >
> > Something else to note is that the scalar path for COPY TO isn't as
> heavy as the state machine in COPY FROM.
> >
> > So if we find the sweet spot for the heuristic, doing the same for COPY
> TO will be trivial and always beneficial.
> > Attached is 0004 which is option 1 (SIMD without re-entering), 0005 is
> the second one.
>
> Patches look correct to me. I think we could move these SIMD code
> portions into a shared function to remove duplication, although that
> might have a performance impact. I have not benchmarked these patches
> yet.
>
> Another consideration is that these patches might need their own
> thread, though I am not completely sure about this yet.
>
> One question: what do you think about having a 0004-style approach for
> COPY FROM? What I have in mind is running SIMD for each line & column,
> stopping SIMD once it can no longer skip an entire chunk, and then
> continuing with the next line & column.
>
> --
> Regards,
> Nazir Bilal Yavuz
> Microsoft
>
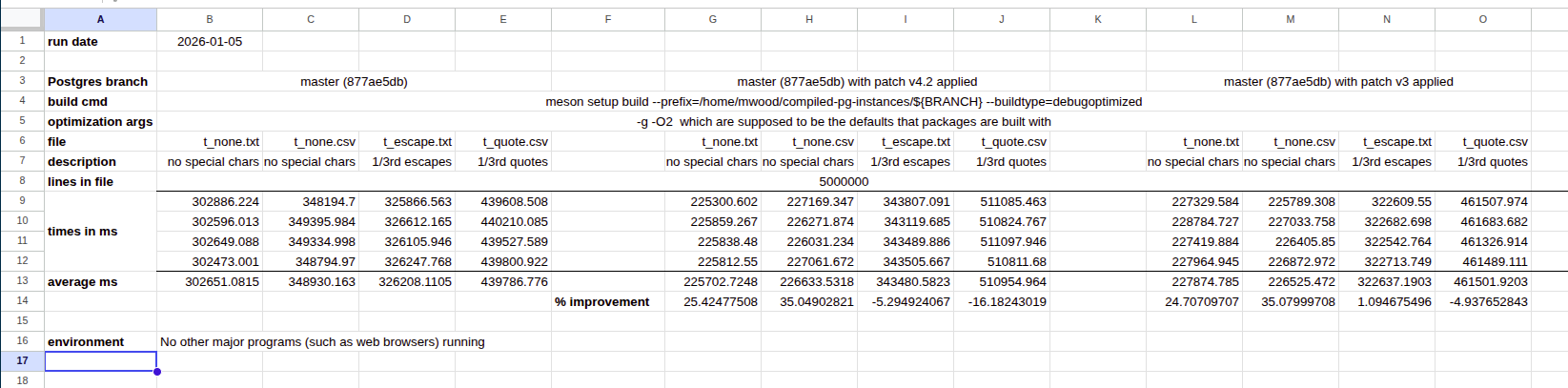
Hello, Nazir, I tried your suggested cpupower commands as well as disabling
turbo, and my results are indeed more uniform. (see attached screenshot of
my spreadsheet).
This time, I ran the tests on my Tower PC instead of on my laptop.
I also followed Mark Wong's advice and used the taskset command to pin my
postgres postmaster (and all of its children) to a single cpu core.
So when I start postgres, I do this to pin it to core 27:
${PGHOME}/bin/pg_ctl -D ${PGHOME}/data -l ${PGHOME}/logfile.txt start
PGPID=$(head -1 ${PGHOME}/data/postmaster.pid)
taskset --cpu-list -p 27 ${PGPID}
My results seem similar to yours:
master: Nazir 85ddcc2f4c | Manni 877ae5db
text, no special: 102294 | 302651
text, 1/3 special: 108946 | 326208
csv, no special: 121831 | 348930
csv, 1/3 special: 140063 | 439786
v3
text, no special: 88890 (13.1% speedup) | 227874 (24.7% speedup)
text, 1/3 special: 110463 (1.4% regression) | 322637 (1.1% speedup)
csv, no special: 89781 (26.3% speedup) | 226525 (35.1% speedup)
csv, 1/3 special: 147094 (5.0% regression) | 461501 (4.9% regression)
v4.2
text, no special: 87785 (14.2% speedup) | 225702 (25.4% speedup)
text, 1/3 special: 127008 (16.6% regression) | 343480 (5.3% regression)
csv, no special: 88093 (27.7% speedup) | 226633 (35.0% speedup)
csv, 1/3 special: 164487 (17.4% regression) | 510954 (16.2% regression)
It would seem that both your results and mine show a more serious
worst-case regression for the v4.2 patches than for the v3 patches. It
seems also that the speedups for v4.2 and v3 are similar.
I'm currently working with Mark Wong to see if his results continue to be
dissimilar (as they currently are now) and, if so, why.
--
-- Manni Wood EDB: https://www.enterprisedb.com
| Attachment | Content-Type | Size |
|---|---|---|
| simd_copy_performance_2025_01_06.png | image/png | 114.9 KB |
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Kirill Reshke | 2026-01-06 20:05:45 | Re: Reduce build times of pg_trgm GIN indexes |
| Previous Message | Jeff Davis | 2026-01-06 19:54:29 | Re: NLS: use gettext() to translate system error messages |
{kind=link}