| From: | Blessy Thomas <blessy456bthomas(at)gmail(dot)com> |
|---|---|
| To: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Extension - multilingual_fuzzy_match : Multilingual phonetic matching extension for PostgreSQL |
| Date: | 2026-03-02 07:25:26 |
| Message-ID: | CAJyyjtA_MwGY+_TgmixjJ8-pkTAUSnUwS3j7cJ2UMSbDjFmbjw@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-general pgsql-hackers |
Hello PostgreSQL Community,
I would like to introduce a PostgreSQL extension called
multilingual_fuzzy_match. This extension enables multilingual name
normalization, transliteration, and fuzzy phonetic matching directly inside
PostgreSQL at query time.
1. What Problem It Solves:
In multilingual datasets (especially Indian language datasets), the same
name may appear in:
- Different scripts
- Different transliterations
- Slight spelling variations
- Multiple languages
For example:
राम ≈ Raam ≈ رَام ≈ ராம்
Traditional equality or LIKE queries fail in such cases. Even trigram
matching doesn’t fully address cross-script phonetic similarity.
2. What This Extension Does
- Detects the script of the input text
- Performs transliteration and normalization
- Generates a phonetic key
- Uses Levenshtein distance (via python-Levenshtein)
- Returns similarity-scored results
All of this happens inside PostgreSQL using PL/Python (plpython3u).
3. Key Features
- No schema changes required
- Query-level matching
- Supports 11 major Indian scripts:
Devanagari, Tamil, Telugu, Bengali, Urdu, Malayalam, Kannada, Odia,
Gujarati, Punjabi
- Works on existing tables
4. Requirements
- PostgreSQL 17 (compiled with Python support)
- Python 3.12+
- plpython3u
- Python packages:
pip install indic-transliteration python-Levenshtein
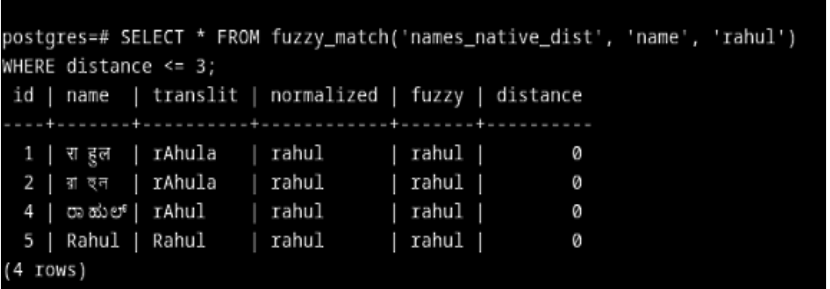
5. Example Usage
-----------------------------------------------------------------------------------------------------------------------------
postgres=#
SELECT * FROM fuzzy_match('names_native_dist', 'name', 'Rahul')
WHERE distance <= 1;
id | name | translit | normalized | fuzzy | distance
----+-------+----------+------------+-------+----------
1 | राहुल | rAhula | rahul | rahul | 0
2 | রাহুল | rAhula | rahul | rahul | 0
4 | ರಾಹುಲ್ | rAhul | rahul | rahul | 0
5 | Rahul | Rahul | rahul | rahul | 0
(4 rows)
--------------------------------------------------------------------------------------------------------------------------------
6. Feedback Requested
I would really appreciate feedback from the community on:
- Extension design approach
- Performance considerations
- Suitability for PGXN submission
I would love suggestions, improvements, and any guidance on making this
production-ready. I’m sharing this not just as a project, but as a starting
point for discussion about multilingual data handling inside PostgreSQL.
Looking forward to your thoughts and critiques.
Thank you!
Regards
Blessy Thomas
| Attachment | Content-Type | Size |
|---|---|---|
| Screenshot from 2026-03-02 12-29-45.png | image/png | 73.7 KB |
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Peter J. Holzer | 2026-03-02 18:29:08 | Re: Documentation weirdness |
| Previous Message | Igor Korot | 2026-03-02 02:49:09 | Re: Documentation weirdness |
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Peter Eisentraut | 2026-03-02 07:27:15 | Re: Check for memset_explicit() and explicit_memset() |
| Previous Message | jian he | 2026-03-02 07:20:24 | Re: pg_dumpall --roles-only interact with other options |
{kind=link}