| From: | Peter Smith <smithpb2250(at)gmail(dot)com> |
|---|---|
| To: | "houzj(dot)fnst(at)fujitsu(dot)com" <houzj(dot)fnst(at)fujitsu(dot)com> |
| Cc: | Amit Kapila <amit(dot)kapila16(at)gmail(dot)com>, Alvaro Herrera <alvherre(at)alvh(dot)no-ip(dot)org>, Euler Taveira <euler(at)eulerto(dot)com>, Greg Nancarrow <gregn4422(at)gmail(dot)com>, vignesh C <vignesh21(at)gmail(dot)com>, Ajin Cherian <itsajin(at)gmail(dot)com>, "tanghy(dot)fnst(at)fujitsu(dot)com" <tanghy(dot)fnst(at)fujitsu(dot)com>, Dilip Kumar <dilipbalaut(at)gmail(dot)com>, Rahila Syed <rahilasyed90(at)gmail(dot)com>, Peter Eisentraut <peter(dot)eisentraut(at)enterprisedb(dot)com>, Önder Kalacı <onderkalaci(at)gmail(dot)com>, japin <japinli(at)hotmail(dot)com>, Michael Paquier <michael(at)paquier(dot)xyz>, David Steele <david(at)pgmasters(dot)net>, Craig Ringer <craig(at)2ndquadrant(dot)com>, Amit Langote <amitlangote09(at)gmail(dot)com>, PostgreSQL Hackers <pgsql-hackers(at)lists(dot)postgresql(dot)org> |
| Subject: | Re: row filtering for logical replication |
| Date: | 2022-02-09 07:48:10 |
| Message-ID: | CAHut+PvTVTXa+HGK-=78ugAS+c+jQPxEhs2FTdTNJzgi1TuJSw@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
> Are there any recent performance evaluations of the overhead of row filters? I
> think it'd be good to get some numbers comparing:
>
> 1) $workload with master
> 2) $workload with patch, but no row filters
> 3) $workload with patch, row filter matching everything
> 4) $workload with patch, row filter matching few rows
>
> For workload I think it'd be worth testing:
> a) bulk COPY/INSERT into one table
> b) Many transactions doing small modifications to one table
> c) Many transactions targetting many different tables
> d) Interspersed DDL + small changes to a table
>
We have collected the performance data results for all the different
workloads [*].
The test strategy is now using pg_recvlogical with steps as Andres
suggested [1].
Note - "Allow 0%" and "Allow 100%" are included as tests cases, but in
practice, a user is unlikely to deliberately use a filter that allows
nothing to pass through it, or allows everything to pass through it.
PSA the bar charts of the results. All other details are below.
~~~~~
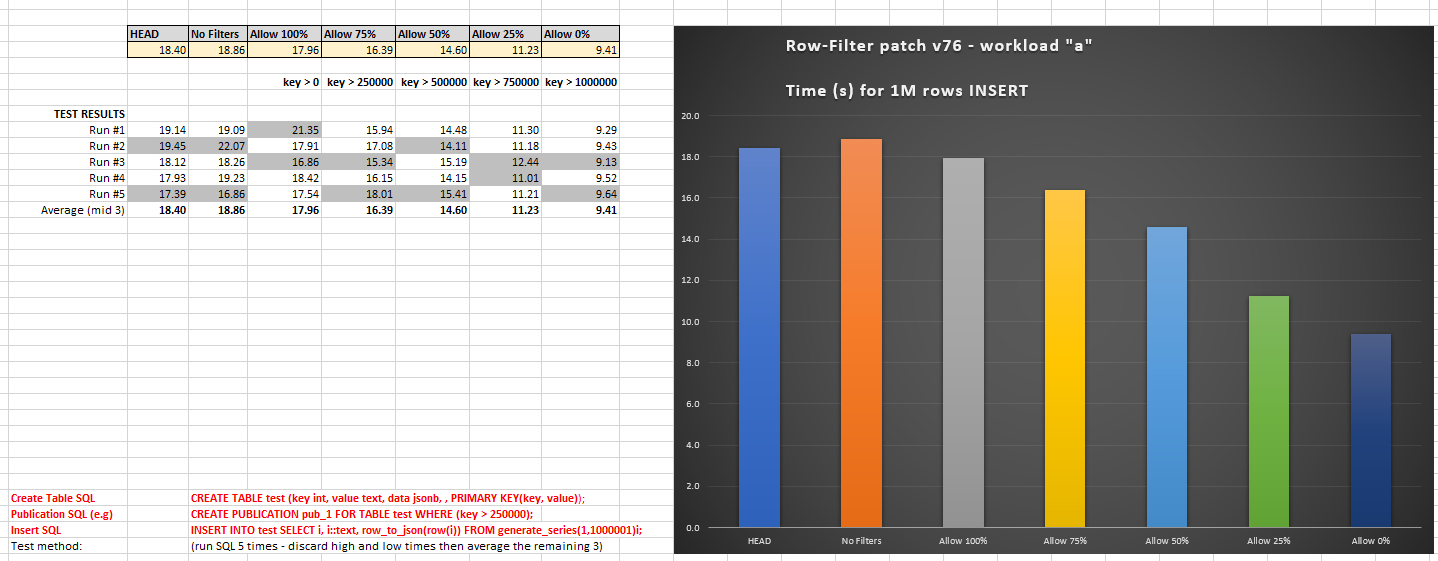
RESULTS - workload "a" (v76)
======================
HEAD 18.40
No Filters 18.86
Allow 100% 17.96
Allow 75% 16.39
Allow 50% 14.60
Allow 25% 11.23
Allow 0% 9.41
Observations for "a":
- Using row filters has minimal overhead in the worst case (compare
HEAD versus "Allow 100%")
- As more % data is filtered out (less is replicated) then the times decrease
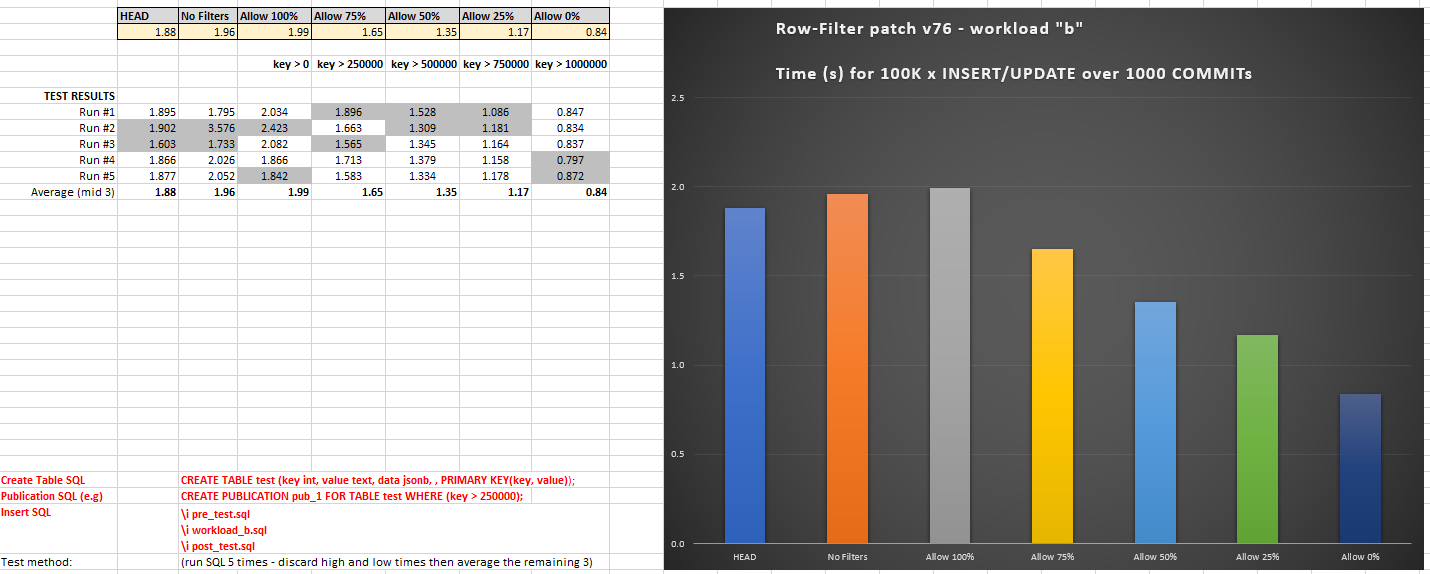
RESULTS - workload "b" (v76)
======================
HEAD 2.30
No Filters 1.96
Allow 100% 1.99
Allow 75% 1.65
Allow 50% 1.35
Allow 25% 1.17
Allow 0% 0.84
Observations for "b":
- Using row filters has minimal overhead in the worst case (compare
HEAD versus "Allow 100%")
- As more % data is filtered out (less is replicated) then the times decrease
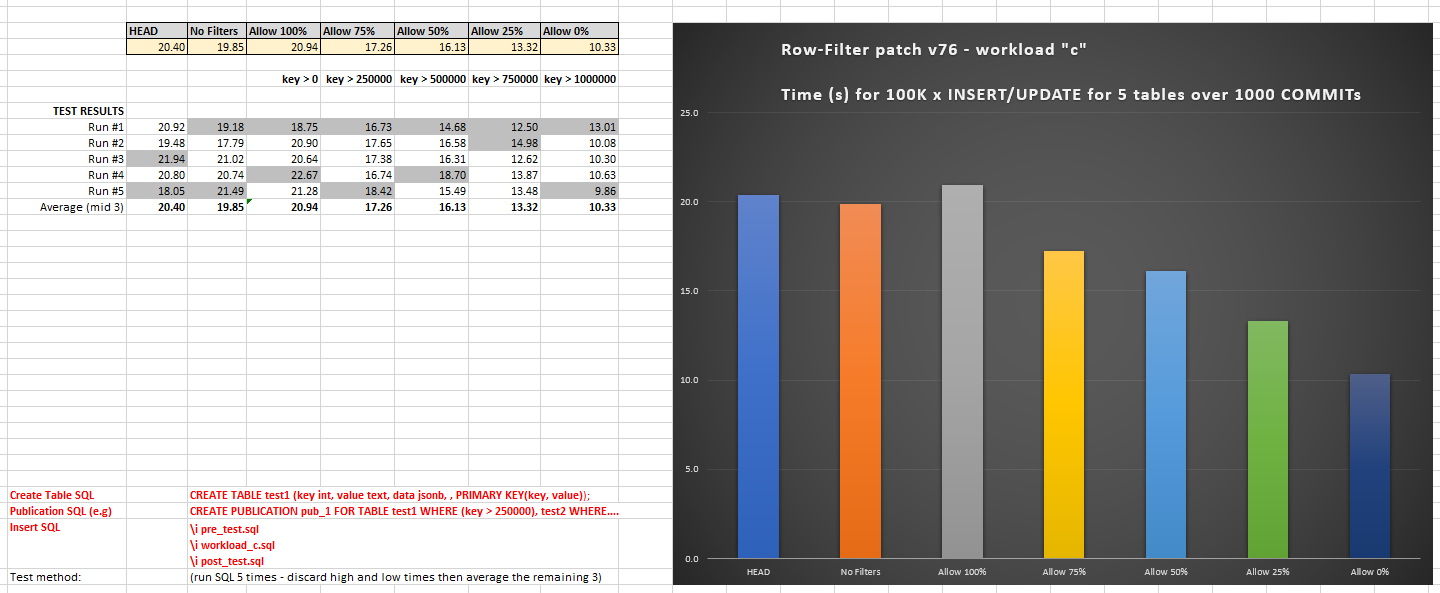
RESULTS - workload "c" (v76)
======================
HEAD 20.40
No Filters 19.85
Allow 100% 20.94
Allow 75% 17.26
Allow 50% 16.13
Allow 25% 13.32
Allow 0% 10.33
Observations for "c":
- Using row filters has minimal overhead in the worst case (compare
HEAD versus "Allow 100%")
- As more % data is filtered out (less is replicated) then the times decrease
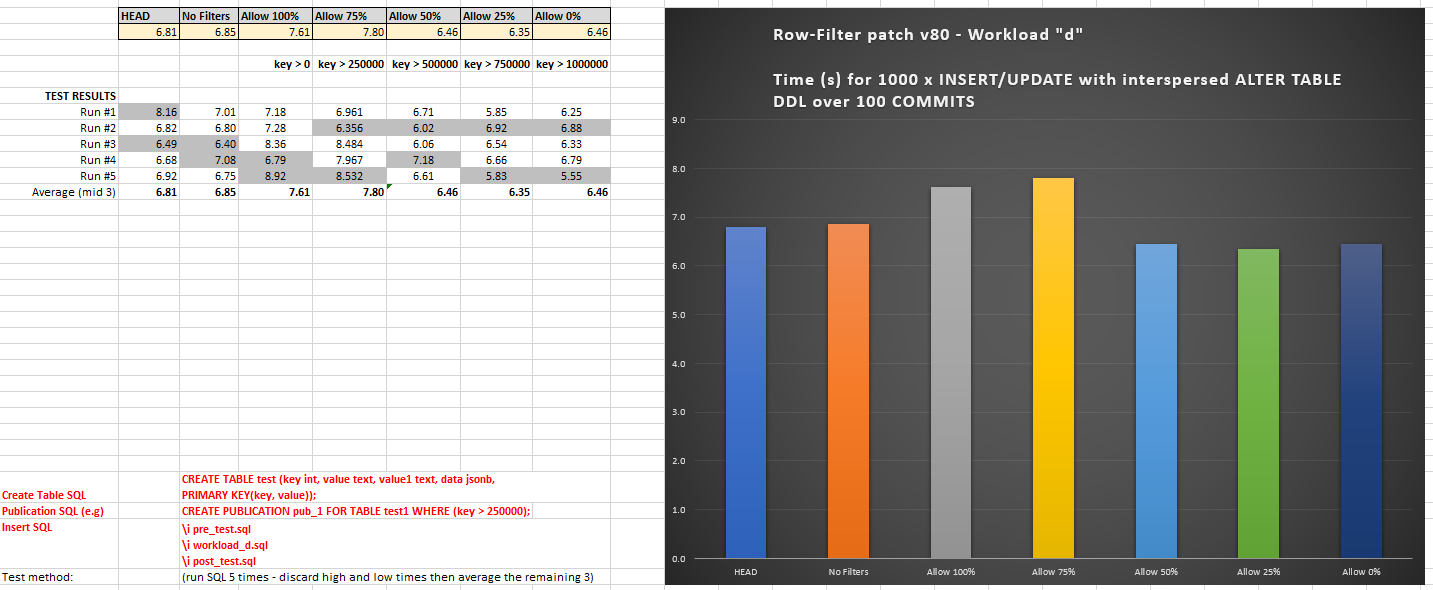
RESULTS - workload "d" (v80)
======================
HEAD 6.81
No Filters 6.85
Allow 100% 7.61
Allow 75% 7.80
Allow 50% 6.46
Allow 25% 6.35
Allow 0% 6.46
Observations for "d":
- As more % data is filtered out (less is replicated) then the times
became less than HEAD, but not much.
- Improvements due to row filtering are less noticeable (e.g. HEAD
versus "Allow 0%") for this workload; we attribute this to the fact
that for this script there are fewer rows getting replicated in the
1st place so we are only comparing 1000 x INSERT/UPDATE against 0 x
INSERT/UPDATE.
~~~~~~
Details - workload "a"
=======================
CREATE TABLE test (key int, value text, data jsonb, PRIMARY KEY(key, value));
CREATE PUBLICATION pub_1 FOR TABLE test;
CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 0); -- 100% allowed
CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 250000); -- 75% allowed
CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 500000); -- 50% allowed
CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 750000); -- 25% allowed
CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 1000000); -- 0% allowed
INSERT INTO test SELECT i, i::text, row_to_json(row(i)) FROM
generate_series(1,1000001)i;
Details - workload "b"
======================
CREATE TABLE test (key int, value text, data jsonb, PRIMARY KEY(key, value));
CREATE PUBLICATION pub_1 FOR TABLE test;
CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 0); -- 100% allowed
CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 250000); -- 75% allowed
CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 500000); -- 50% allowed
CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 750000); -- 25% allowed
CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 1000000); -- 0% allowed
DO
$do$
BEGIN
FOR i IN 0..1000001 BY 10 LOOP
INSERT INTO test VALUES(i,'BAH', row_to_json(row(i)));
UPDATE test SET value = 'FOO' WHERE key = i;
IF I % 1000 = 0 THEN
COMMIT;
END IF;
END LOOP;
END
$do$;
Details - workload "c"
======================
CREATE TABLE test1 (key int, value text, data jsonb, PRIMARY KEY(key, value));
CREATE TABLE test2 (key int, value text, data jsonb, PRIMARY KEY(key, value));
CREATE TABLE test3 (key int, value text, data jsonb, PRIMARY KEY(key, value));
CREATE TABLE test4 (key int, value text, data jsonb, PRIMARY KEY(key, value));
CREATE TABLE test5 (key int, value text, data jsonb, PRIMARY KEY(key, value));
CREATE PUBLICATION pub_1 FOR TABLE test1, test2, test3, test4, test5;
CREATE PUBLICATION pub_1 FOR TABLE test1 WHERE (key > 0), test2 WHERE
(key > 0), test3 WHERE (key > 0), test4 WHERE (key > 0), test5 WHERE
(key > 0);
CREATE PUBLICATION pub_1 FOR TABLE test1 WHERE (key > 250000), test2
WHERE (key > 250000), test3 WHERE (key > 250000), test4 WHERE (key >
250000), test5 WHERE (key > 250000);
CREATE PUBLICATION pub_1 FOR TABLE test1 WHERE (key > 500000), test2
WHERE (key > 500000), test3 WHERE (key > 500000), test4 WHERE (key >
500000), test5 WHERE (key > 500000);
CREATE PUBLICATION pub_1 FOR TABLE test1 WHERE (key > 750000), test2
WHERE (key > 750000), test3 WHERE (key > 750000), test4 WHERE (key >
750000), test5 WHERE (key > 750000);
CREATE PUBLICATION pub_1 FOR TABLE test1 WHERE (key > 1000000), test2
WHERE (key > 1000000), test3 WHERE (key > 1000000), test4 WHERE (key >
1000000), test5 WHERE (key > 1000000);
DO
$do$
BEGIN
FOR i IN 0..1000001 BY 10 LOOP
-- test1
INSERT INTO test1 VALUES(i,'BAH', row_to_json(row(i)));
UPDATE test1 SET value = 'FOO' WHERE key = i;
-- test2
INSERT INTO test2 VALUES(i,'BAH', row_to_json(row(i)));
UPDATE test2 SET value = 'FOO' WHERE key = i;
-- test3
INSERT INTO test3 VALUES(i,'BAH', row_to_json(row(i)));
UPDATE test3 SET value = 'FOO' WHERE key = i;
-- test4
INSERT INTO test4 VALUES(i,'BAH', row_to_json(row(i)));
UPDATE test4 SET value = 'FOO' WHERE key = i;
-- test5
INSERT INTO test5 VALUES(i,'BAH', row_to_json(row(i)));
UPDATE test5 SET value = 'FOO' WHERE key = i;
IF I % 1000 = 0 THEN
-- raise notice 'commit: %', i;
COMMIT;
END IF;
END LOOP;
END
$do$;
Details - workload "d"
======================
CREATE TABLE test (key int, value text, data jsonb, PRIMARY KEY(key, value));
CREATE PUBLICATION pub_1 FOR TABLE test;
CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 0); -- 100% allowed
CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 250000); -- 75% allowed
CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 500000); -- 50% allowed
CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 750000); -- 25% allowed
CREATE PUBLICATION pub_1 FOR TABLE test WHERE (key > 1000000); -- 0% allowed
DO
$do$
BEGIN
FOR i IN 0..1000000 BY 1000 LOOP
ALTER TABLE test ALTER COLUMN value1 TYPE varchar(30);
INSERT INTO test VALUES(i,'BAH','BAH', row_to_json(row(i)));
ALTER TABLE test ALTER COLUMN value1 TYPE text;
UPDATE test SET value = 'FOO' WHERE key = i;
IF I % 10000 = 0 THEN
COMMIT;
END IF;
END LOOP;
END
$do$;
------
[*] This post repeats some results for already sent for workloads
"a","b","c"; this is so the complete set is now all here in one place
[1] https://www.postgresql.org/message-id/20220203182922.344fhhqzjp2ah6yp%40alap3.anarazel.de
Kind Regards,
Peter Smith.
Fujitsu Australia
| Attachment | Content-Type | Size |
|---|---|---|
| workload-a-v76.PNG | image/png | 152.2 KB |
| workload-d-v80.PNG | image/png | 153.7 KB |
| workload-b-v76.PNG | image/png | 158.0 KB |
| workload-c-v76.PNG | image/png | 159.9 KB |
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Kyotaro Horiguchi | 2022-02-09 07:55:49 | Re: Support escape sequence for cluster_name in postgres_fdw.application_name |
| Previous Message | Kyotaro Horiguchi | 2022-02-09 07:44:14 | Re: Make mesage at end-of-recovery less scary. |
{kind=link}
{kind=link}
{kind=link}
{kind=link}