pgbench: INSERT workload, FK indexes, filler fix
| From: | Gregory Smith <gregsmithpgsql(at)gmail(dot)com> |
|---|---|
| To: | PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Cc: | david(dot)christensen(at)crunchydata(dot)com |
| Subject: | pgbench: INSERT workload, FK indexes, filler fix |
| Date: | 2021-07-01 03:18:41 |
| Message-ID: | CAHLJuCW-rdFTDtFCaGQ=tcrjd1eScBEsQ9xe6Rg=7=rcHE__qA@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
Attached is a combined diff for a set of related patches to the built-in
pgbench workloads. One commit adds an INSERT workload. One fixes the long
standing 0 length filler issue. A new --extra-indexes option adds the
indexes needed for lookups added by the --foreign-keys option.
The commits are independent but overlap in goals. I'm grouping them here
mainly to consolidate this message, covering the feedback leading to this
particular combination plus a first review from me. More graphs etc.
coming as my pgbench toolchain settles down again.
Code all by David Christensen based on vague specs from me, errors probably
mine, changes are also at
https://github.com/pgguru/postgres/commits/pgbench-improvements David ran
through the pgbench TAP regression tests and we're thinking about how to
add more for changes like this. Long term that collides with performance
testing for things like CREATE INDEX, which I've done some work on myself
recently in pgbench-tools.
After bouncing the possibilities around a little, David and I thought this
specific set of changes might be the right amount of change for one PG
version. Core development could bite on all these pgbench changes or even
more [foreshadowing] as part of a themed rework of pgbench's workload
that's known to adjust results a bit, so beware direct comparisons to old
versions. That's what I'd prefer to do, a break it all at once strategy
for these items and whatever else we can dig up this cycle. I'll do my
usual thing to help with that, starting with more benchmark graphs of this
patch and such once my pgbench toolchain settles again.
To me pgbench should continue to demonstrate good PostgreSQL client
behavior, and all this is just modernizing polish. Row size and indexing
matter of course, but none of these changes really alter the fundamentals
of pgbench results. With modern hardware acceleration, the performance
drag due to the increased size of the filler is so much further down in the
benchmark noise from where I started at with PG. The $750 USD AMD retail
chip in my basement lab pushes 1M TPS of prepared SELECT statements over
sockets. Plus or minus 84 bytes per row in a benchmark database doesn't
worry me so much anymore. Seems down there with JSON overhead as a lost
micro optimization fight nowadays.
# Background: pgbench vs. sysbench
This whole rework idea came from a performance review pass where I compared
pgbench and sysbench again, as both have evolved a good bit since my last
comparison. All of the software defined storage testing brewing right now
is shining a brighter light on both tools lately than I've seen in a while.
The goal I worked on a bit (with Joe Conway and RedHat, thank you to our
sponsors) was how to make both tools closer to equal when performing
similar tasks. pgbench can duplicate the basics of the sysbench OLTP
workload easily enough, running custom pgbench scripts against the
generated pgbench_accounts and/or the initially empty pgbench_history. Joe
and I did some work on sysbench to improve its error handling to where it
reconnected automatically as part of that. How to add a reconnection
feature to pgbench is a struggle because of where it fits between PG's
typical connection and connection pooler abstractions; different story than
this one. sysbench had the basics and just needed some error handling bug
fixes, which might even have made their way upstream. These three patches
are the changes I thought core PG could use in parallel, as a mix of
correctness, new features, and fair play in benchmarking.
# INSERT workload
The easiest way to measure the basic COMMIT overhead of network storage is
by doing an INSERT into an empty database and seeing the latency. I've
been doing that regularly since 9.1 added sync rep and that was the easiest
way to test client scaling. From my perspective as an old CRUD app writer,
creating a row is the main interesting operation that's not already
available in pgbench. (No one has a DELETE heavy workload for very long)
Some chunk of pgbench users are trying to do that job now using the
built-ins, and none of the options fit well. Anything that touches the
accounts table becomes heavily wrapped into the checkpoint cycle, and
extracting signal from checkpoint noise is so hard dudes charge for books
about it. In this context I trust INSERT results more than I do the output
from pg_test_fsync, which is too low level for me to recommend as a
general-purpose tool.
For better or worse pgbench is a primary tool in that role to PG customers,
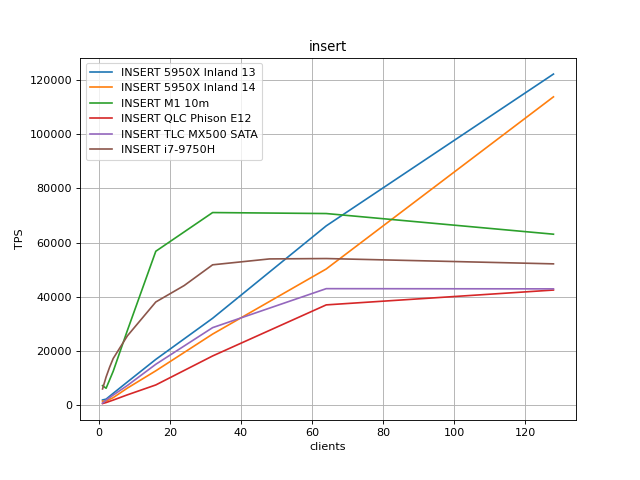
and the INSERT scaling looks great all over. I've attached an early sample
comparing 5 models of SSD to show it; what looks like a PG14 regression
there is a testing artifact I'm working on.
The INSERT workload is useful with or without the history indexes, which
again as written here only are created if you ask for the FKs. When I do
these performance studies of INSERT scaling as a new history table builds,
for really no good reason other than my curiosity, the slowdowns from
whether the pgbench_history has keys on it seem like basic primary key
overhead to me.
# FK indexes
The new extra index set always appears if you turn on FKs after this
change. Then there's also the original path to turn on the indexes but not
the FKs.
As I don't consider the use case of FKs without indexes to exist in the
wild, I was surprised at the current state of things, that you could even
have FKs but not the associated indexes. I have not RTFA for it but I'd
wager it's been brought up before. In that case, +1 from me and David for
this patch's view of database correctness I guess.
On a fresh pgbench database, the history table is empty and only the
accounts table has serious size to it. Adding indexes to the other tables,
like this patch does, has light overhead during the creation cycle.
My take on INSERT/UPDATE workloads that once you're hitting disk and have
WAL changes, whether one or three index blocks are touched each time on the
small tables is so much more of a checkpoint problem than anything else.
The overhead these new indexes add should be in the noise of the standard
pgbench "TPC-B (sort of)" workload.
The index overhead only gets substantial once you've run pgbench long
enough that history has some size to it. The tiny slice of people using
pgbench for long-term simulation--which might only be me--are surely
sophisticated enough to deal with index overhead increasing from zero to
normal primary key index overhead.
I personally would prefer to see pgbench lead by example here, that tables
related this way should be indexed with FKs by default, as the Right Way to
do such things. There's a slow deprecation plan leading that way possible
from here. This patch set adds options to add those indexes, and slowly
those options could become the defaults. Or there's the break it all at
once and the FK+Index path is the new default path forward, and users would
have to turn it off if they want to reduce overhead.
# filler
Every few years a customer I deal with discovers pgbench's generated tables
don't really fill its filler column. I think on modern hardware it's time
to pay for that fully, as not as scary of a performance regression.
memcpy() is AVX accelerated for me on Linux now; it's not the old C
standard library doing the block work. When I field detailed questions
about the filler, why it's length is 0, how the problem was introduced, and
why it was never fixed before, it's not the best look.
From port 5432 you can identify if a patched pgbench client created the
database like this:
pgbench# SELECT length(filler) FROM pgbench_accounts LIMIT 1;
length | 84
That is 0 in HEAD. I'd really prefer not to have to pause and explain this
filler thing again. It looks a little too much like benchmark mischief for
my comfort, which the whole sysbench comparison really highlighted again.
| Attachment | Content-Type | Size |
|---|---|---|
| pgbench-insert-workload.patch | application/octet-stream | 14.1 KB |
|
image/png | 48.0 KB |
Responses
- Re: pgbench: INSERT workload, FK indexes, filler fix at 2021-07-01 10:47:57 from Fabien COELHO
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Tom Lane | 2021-07-01 03:45:10 | Re: Preventing abort() and exit() calls in libpq |
| Previous Message | Amit Kapila | 2021-07-01 03:09:10 | Re: New committers: Daniel Gustafsson and John Naylor |