| From: | Benjamin Manes <ben(dot)manes(at)gmail(dot)com> |
|---|---|
| To: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> |
| Cc: | Peter Geoghegan <pg(at)bowt(dot)ie>, Andrey Borodin <x4mmm(at)yandex-team(dot)ru>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org>, Arslan Gumerov <garsthe1st(at)gmail(dot)com>, Andrey Chausov <dxahtepb(at)gmail(dot)com>, geymer_98(at)mail(dot)ru, dafi913(at)yandex(dot)ru, edigaryev(dot)ig(at)phystech(dot)edu |
| Subject: | Re: [Patch][WiP] Tweaked LRU for shared buffers |
| Date: | 2019-02-16 00:48:50 |
| Message-ID: | CAGu0=MM4jwHrcWzL246B9Q7-73LFKSnXWRC8RYEiv+Y7=JF=Jw@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
Hi,
I was not involved with Andrey and his team's work, which looks like a very
promising first pass. I can try to clarify a few minor details.
What is CAR? Did you mean ARC, perhaps?
CAR is the Clock variants of ARC: CAR: Clock with Adaptive Replacement
<https://www.usenix.org/legacy/publications/library/proceedings/fast04/tech/full_papers/bansal/bansal.pdf>
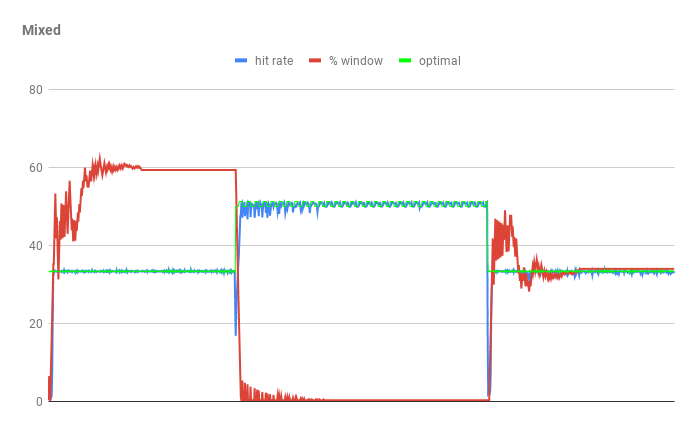
I believe the main interest in ARC is its claim of adaptability with high
hit rates. Unfortunately the reality is less impressive as it fails to
handle many frequency workloads, e.g. poor scan resistance, and the
adaptivity is poor due to the accesses being quite noisy. For W-TinyLFU, we
have recent improvements which show near perfect adaptivity
<https://user-images.githubusercontent.com/378614/52891655-2979e380-3141-11e9-91b3-00002a3cc80b.png>
in
our stress case that results in double the hit rate of ARC and is less than
1% from optimal.
Can you point us to the thread/email discussing those ideas? I have tried
> searching through archives, but I haven't found anything :-(
This thread
<https://www.postgresql.org/message-id/1526057854777-0.post%40n3.nabble.com>
doesn't explain Andrey's work, but includes my minor contribution. The
longer thread discusses the interest in CAR, et al.
Are you suggesting to get rid of the buffer rings we use for sequential
> scans, for example? IMHO that's going to be tricky, e.g. because of
> synchronized sequential scans.
If you mean "synchronized" in terms of multi-threading and locks, then this
is a solved problem
<http://highscalability.com/blog/2016/1/25/design-of-a-modern-cache.html>
in terms of caching. My limited understanding is that the buffer rings are
used to protect the cache from being polluted by scans which flush the
LRU-like algorithms. This allows those policies to capture more frequent
items. It also avoids lock contention on the cache due to writes caused by
misses, where Clock allows lock-free reads but uses a global lock on
writes. A smarter cache eviction policy and concurrency model can handle
this without needing buffer rings to compensate.
Somebody should write a patch to make buffer eviction completely random,
> without aiming to get it committed. That isn't as bad of a strategy as it
> sounds, and it would help with assessing improvements in this area.
>
A related and helpful patch would be to capture the access log and provide
anonymized traces. We have a simulator
<https://github.com/ben-manes/caffeine/wiki/Simulator> with dozens of
policies to quickly provide a breakdown. That would let you know the hit
rates before deciding on the policy to adopt.
Cheers.
On Fri, Feb 15, 2019 at 4:22 PM Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com>
wrote:
>
> On 2/16/19 12:51 AM, Peter Geoghegan wrote:
> > On Fri, Feb 15, 2019 at 3:30 PM Tomas Vondra
> > <tomas(dot)vondra(at)2ndquadrant(dot)com> wrote:
> >> That TPS chart looks a bit ... wild. How come the master jumps so much
> >> up and down? That's a bit suspicious, IMHO.
> >
> > Somebody should write a patch to make buffer eviction completely
> > random, without aiming to get it committed. That isn't as bad of a
> > strategy as it sounds, and it would help with assessing improvements
> > in this area.
> >
> > We know that the cache replacement algorithm behaves randomly when
> > there is extreme contention, while also slowing everything down due
> > to maintaining the clock.
>
> Possibly, although I still find it strange that the throughput first
> grows, then at shared_buffers 1GB it drops, and then at 3GB it starts
> growing again. Considering this is on 200GB data set, I doubt the
> pressure/contention is much different with 1GB and 3GB, but maybe it is.
>
> > A unambiguously better caching algorithm would at a minimum be able
> > to beat our "cheap random replacement" prototype as well as the
> > existing clocksweep algorithm in most or all cases. That seems like a
> > reasonably good starting point, at least.
> >
>
> Yes, comparison to cheap random replacement would be an interesting
> experiment.
>
>
> regards
>
> --
> Tomas Vondra http://www.2ndQuadrant.com
> PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
>
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Michael Paquier | 2019-02-16 01:12:19 | Re: Channel binding |
| Previous Message | Tomas Vondra | 2019-02-16 00:22:36 | Re: [Patch][WiP] Tweaked LRU for shared buffers |
{kind=link}