Re: Todo: Teach planner to evaluate multiple windows in the optimal order
| From: | John Naylor <john(dot)naylor(at)enterprisedb(dot)com> |
|---|---|
| To: | David Rowley <dgrowleyml(at)gmail(dot)com> |
| Cc: | Ankit Kumar Pandey <itsankitkp(at)gmail(dot)com>, pghackers <pgsql-hackers(at)lists(dot)postgresql(dot)org>, Vik Fearing <vik(at)postgresfriends(dot)org> |
| Subject: | Re: Todo: Teach planner to evaluate multiple windows in the optimal order |
| Date: | 2023-02-15 11:45:01 |
| Message-ID: | CAFBsxsG5h_Tq1p90QaVcok4TE5zWZ-7J_z-x4YqjXxoKk0jNoA@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
On Wed, Feb 15, 2023 at 3:02 PM David Rowley <dgrowleyml(at)gmail(dot)com> wrote:
>
> On Wed, 15 Feb 2023 at 17:23, John Naylor <john(dot)naylor(at)enterprisedb(dot)com>
wrote:
> > HEAD:
> >
> > 4 ^ 8: latency average = 113.976 ms
> > 5 ^ 8: latency average = 783.830 ms
> > 6 ^ 8: latency average = 3990.351 ms
> > 7 ^ 8: latency average = 15793.629 ms
> >
> > Skip rechecking first key:
> >
> > 4 ^ 8: latency average = 107.028 ms
> > 5 ^ 8: latency average = 732.327 ms
> > 6 ^ 8: latency average = 3709.882 ms
> > 7 ^ 8: latency average = 14570.651 ms
> Yeah, just a hack. My intention with it was just to prove we had a
> problem because sometimes Sort -> Incremental Sort was faster than
> Sort. Ideally, with your change, we'd see that it's always faster to
> do the full sort in one go. It would be good to see your patch with
> and without the planner hack patch to ensure sort is now always faster
> than sort -> incremental sort.
Okay, here's a rerun including the sort hack, and it looks like incremental
sort is only ahead with the smallest set, otherwise same or maybe slightly
slower:
HEAD:
4 ^ 8: latency average = 113.461 ms
5 ^ 8: latency average = 786.080 ms
6 ^ 8: latency average = 3948.388 ms
7 ^ 8: latency average = 15733.348 ms
tiebreaker:
4 ^ 8: latency average = 106.556 ms
5 ^ 8: latency average = 734.834 ms
6 ^ 8: latency average = 3640.507 ms
7 ^ 8: latency average = 14470.199 ms
tiebreaker + incr sort hack:
4 ^ 8: latency average = 93.998 ms
5 ^ 8: latency average = 740.120 ms
6 ^ 8: latency average = 3715.942 ms
7 ^ 8: latency average = 14749.323 ms
And as far as this:
> I suspect that I fat-fingered work_mem yesterday, so next I'll pick a
badly-performing mod like 32, then range over work_mem and see if that
explains anything, especially whether L3 effects are in fact more important
in this workload.
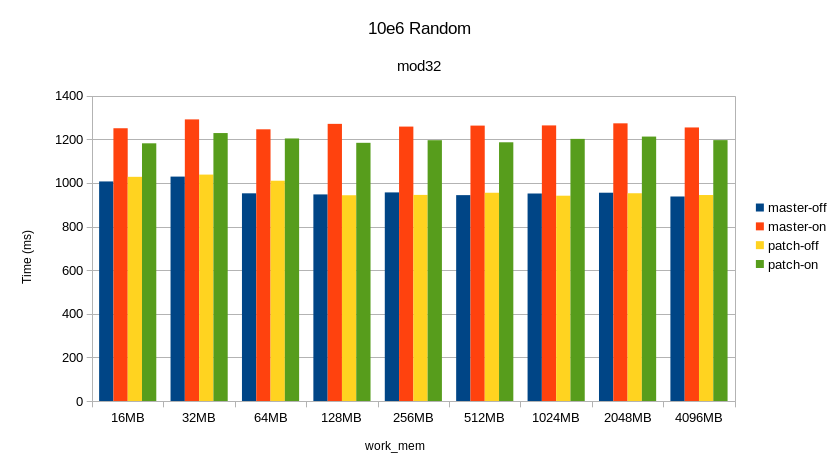
Attached is a script and image for fixing the input at random / mod32 and
varying work_mem. There is not a whole lot of variation here: pushdown
regresses and the tiebreaker patch only helped marginally. I'm still not
sure why the results from yesterday looked better than today.
--
John Naylor
EDB: http://www.enterprisedb.com
| Attachment | Content-Type | Size |
|---|---|---|
| bench_windowsort_workmem-20230215.sh | application/x-shellscript | 1.6 KB |
|
image/png | 22.4 KB |
In response to
- Re: Todo: Teach planner to evaluate multiple windows in the optimal order at 2023-02-15 08:02:31 from David Rowley
Responses
- Re: Todo: Teach planner to evaluate multiple windows in the optimal order at 2023-02-16 03:02:44 from David Rowley
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Etsuro Fujita | 2023-02-15 11:53:00 | Re: Refactoring postgres_fdw/connection.c |
| Previous Message | Hayato Kuroda (Fujitsu) | 2023-02-15 11:29:18 | RE: Time delayed LR (WAS Re: logical replication restrictions) |