Re: Improving btree performance through specializing by key shape, take 2
| From: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com> |
|---|---|
| To: | Peter Geoghegan <pg(at)bowt(dot)ie>, David Christensen <david(at)pgguru(dot)net> |
| Cc: | Matthias van de Meent <boekewurm+postgres(at)gmail(dot)com>, pgsql-hackers(at)lists(dot)postgresql(dot)org |
| Subject: | Re: Improving btree performance through specializing by key shape, take 2 |
| Date: | 2023-06-22 20:50:35 |
| Message-ID: | CAEze2Wh_3+_Q+BefaLrpdXXR01vKr3R2R=h5gFxR+U4+0Z=40w@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
On Tue, 4 Apr 2023 at 17:43, Gregory Stark (as CFM) <stark(dot)cfm(at)gmail(dot)com> wrote:
>
> Hm. The cfbot has a fairly trivial issue with this with a unused variable:
Attached a rebase on top of HEAD @ 8cca660b to make the patch apply
again. I think this is ready for review once again. As the patchset
has seen no significant changes since v8 of the patchset this january
[0], I've added a description of the changes below.
Kind regards,
Matthias van de Meent
Neon, Inc.
= Description of the patchset so far:
This patchset implements two features that *taken togetther* improve
the performance of our btree implementation:
== Dynamic prefix truncation (0001)
The code now tracks how many prefix attributes of the scan key are
already considered equal based on earlier binsrch results, and ignores
those prefix colums in further binsrch operations (sorted list; if
both the high and low value of your range have the same prefix, the
middle value will have that prefix, too). This reduces the number of
calls into opclass-supplied (dynamic) compare functions, and thus
increase performance for multi-key-attribute indexes where shared
prefixes are common (e.g. index on (customer, order_id)).
== Index key shape code specialization (0002-0006)
Index tuple attribute accesses for multi-column indexes are often done
through index_getattr, which gets very expensive for indexes which
cannot use attcacheoff. However, single-key and attcacheoff-able
indexes do benefit greatly from the attcacheoff optimization, so we
can't just stop applying the optimization. This is why the second part
of the patchset (0002 and up) adds infrastructure to generate
specialized code paths that access key attributes in the most
efficient way it knows of: Single key attributes do not go through
loops/condtionals for which attribute it is (except certain
exceptions, 0004), attcacheoff-able indexes get the same treatment as
they do now, and indexes where attcacheoff cannot be used for all key
attributes will get a special attribute iterator that incrementally
calculates the offset of each attribute in the current index tuple
(0005+0006).
Although patch 0002 is large, most of the modified lines are functions
being moved into different files. Once 0002 is understood, the
following patches should be fairly easy to understand as well.
= Why both features in one patchset?
The overhead of keeping track of the prefix in 0001 can add up to
several % of performance lost for the common index shape where dynamic
prefix truncation cannot be applied (measured 5-9%); single-column
unique indexes are the most sensitive to this. By adding the
single-key-column code specialization in 0004, we reduce other types
of overhead for the indexes most affected, which thus compensates for
the additional overhead in 0001, resulting in a net-neutral result.
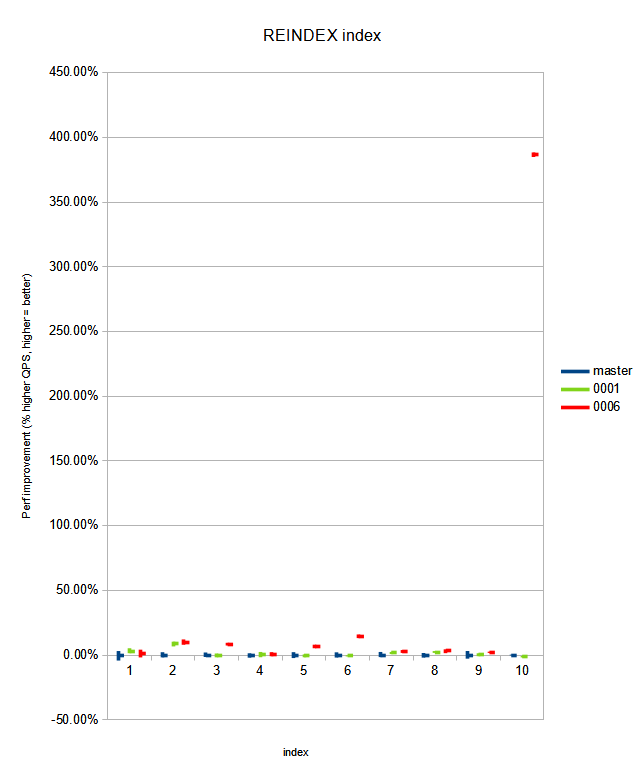
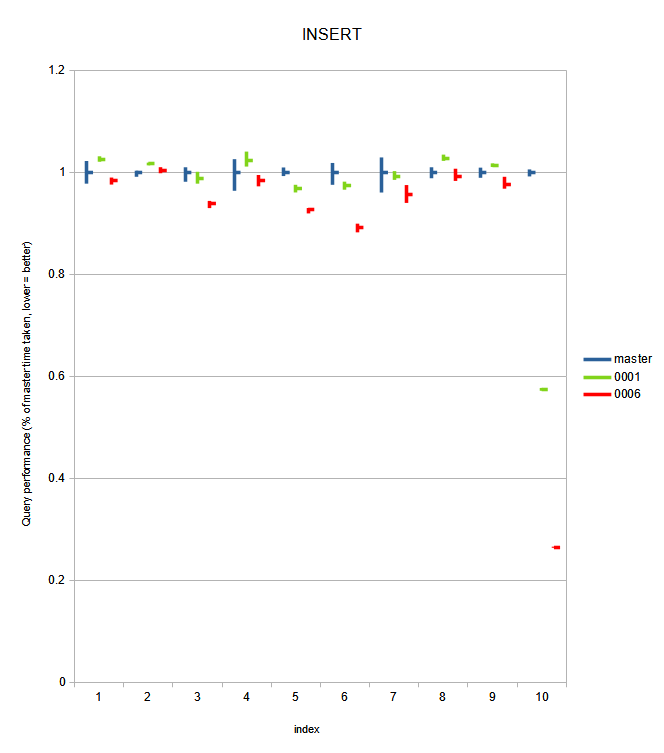
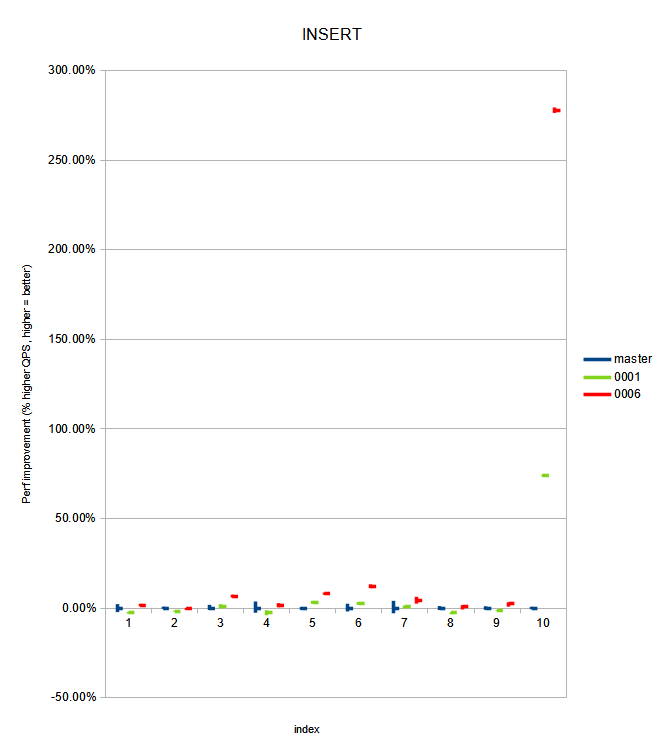
= Benchmarks
I haven't re-run the benchmarks for this since v8 at [0] as I haven't
modified the patch significantly after that patch - only compiler
complaint fixes and changes required for rebasing. The results from
that benchmark: improvements vary between 'not significantly different
from HEAD' to '250+% improved throughput for select INSERT workloads,
and 360+% improved for select REINDEX workloads'. Graphs from that
benchmark are also attached now; as LibreOffice Calc wasn't good at
exporting the sheet with working graphs.
| Attachment | Content-Type | Size |
|---|---|---|
| v11-0003-Use-specialized-attribute-iterators-in-the-speci.patch | application/octet-stream | 12.0 KB |
| v11-0004-Optimize-nbts_attiter-for-nkeyatts-1-btrees.patch | application/octet-stream | 5.5 KB |
| v11-0005-Add-an-attcacheoff-populating-function.patch | application/octet-stream | 4.7 KB |
| v11-0001-Implement-dynamic-prefix-compression-in-nbtree.patch | application/octet-stream | 23.0 KB |
| v11-0002-Specialize-nbtree-functions-on-btree-key-shape.patch | application/octet-stream | 249.7 KB |
| v11-0006-btree-specialization-for-variable-length-multi-a.patch | application/octet-stream | 11.6 KB |
|
image/png | 19.4 KB |
|
image/png | 15.5 KB |

|
image/png | 18.1 KB |
|
image/png | 17.5 KB |
In response to
- Re: Improving btree performance through specializing by key shape, take 2 at 2023-04-04 15:42:54 from Gregory Stark (as CFM)
Responses
- Re: Improving btree performance through specializing by key shape, take 2 at 2023-06-23 09:26:21 from Dilip Kumar
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Greg Sabino Mullane | 2023-06-22 20:56:43 | Re: Bytea PL/Perl transform |
| Previous Message | David Zhang | 2023-06-22 19:08:05 | Re: [PATCH] pg_regress.c: Fix "make check" on Mac OS X: Pass DYLD_LIBRARY_PATH |