Re: Improving spin-lock implementation on ARM.
| From: | Krunal Bauskar <krunalbauskar(at)gmail(dot)com> |
|---|---|
| To: | Alexander Korotkov <aekorotkov(at)gmail(dot)com> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, Peter Eisentraut <peter(dot)eisentraut(at)enterprisedb(dot)com>, Michael Paquier <michael(at)paquier(dot)xyz>, pgsql-hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Improving spin-lock implementation on ARM. |
| Date: | 2020-12-01 12:43:38 |
| Message-ID: | CAB10pyYgh+KM4rY6XYbj3NNHkUQVV9UNpqaVmb9_fLbsUW+Vyg@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
On Tue, 1 Dec 2020 at 02:16, Alexander Korotkov <aekorotkov(at)gmail(dot)com>
wrote:
> On Mon, Nov 30, 2020 at 9:21 PM Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> wrote:
> > Alexander Korotkov <aekorotkov(at)gmail(dot)com> writes:
> > > I tend to think that LSE is enabled by default in Apple's clang based
> > > on your previous message[1]. In order to dispel the doubts could you
> > > please provide assembly of SpinLockAcquire for following clang
> > > options.
> > > "-O2"
> > > "-O2 -march=armv8-a+lse"
> > > "-O2 -march=armv8-a"
> >
> > Huh. Those options make exactly zero difference to the code generated
> > for SpinLockAcquire/SpinLockRelease; it's the same as I showed upthread,
> > for either the HEAD definition of TAS() or the CAS patch's version.
> >
> > So now I'm at a loss as to the reason for the performance difference
> > I got. -march=armv8-a+lse does make a difference to code generation
> > someplace, because the overall size of the postgres executable changes
> > by 16kB or so. One might argue that the performance difference is due
> > to better code elsewhere than the spinlocks ... but the test I'm running
> > is basically just
> >
> > while (count-- > 0)
> > {
> > XLogGetLastRemovedSegno();
> >
> > CHECK_FOR_INTERRUPTS();
> > }
> >
> > so it's hard to see where a non-spinlock-related code change would come
> > in. That loop itself definitely generates the same code either way.
> >
> > I did find this interesting output from "clang -v":
> >
> > -target-cpu vortex -target-feature +v8.3a -target-feature +fp-armv8
> -target-feature +neon -target-feature +crc -target-feature +crypto
> -target-feature +fullfp16 -target-feature +ras -target-feature +lse
> -target-feature +rdm -target-feature +rcpc -target-feature +zcm
> -target-feature +zcz -target-feature +sha2 -target-feature +aes
> >
> > whereas adding -march=armv8-a+lse changes that to just
> >
> > -target-cpu vortex -target-feature +neon -target-feature +lse
> -target-feature +zcm -target-feature +zcz
> >
> > On the whole, that would make one think that -march=armv8-a+lse
> > should produce worse code than the default settings.
>
> Great, thanks.
>
> So, I think the following hypothesis isn't disproved yet.
> 1) On ARM with LSE support, PostgreSQL built with LSE is faster than
> PostgreSQL built without LSE. Even if the latter is patched with
> anything considered in this thread.
> 2) None of the patches considered in this thread give a clear
> advantage for PostgreSQL built with LSE.
>
> To further confirm this let's wait for Kunpeng 920 tests by Krunal
> Bauskar and Amit Khandekar. Also it would be nice if someone will run
> benchmarks similar to [1] on Apple M1.
>
------------------------------------------------------------------------------------------------------------------------------------------
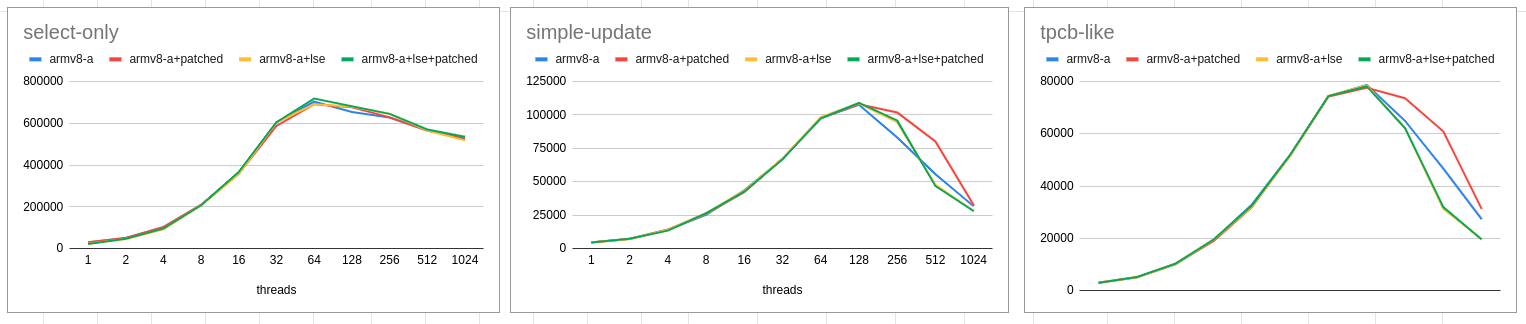
I have completed benchmarking with lse.
Graph attached.
* For me, lse failed to perform. With lse enabled performance with higher
scalability was infact less than baseline (with TAS).
[This is true with and without patch (cas)]. So lse is unable to push
things.
* Graph traces all 4 lines (baseline (tas), baseline-patched (cas),
baseline-lse (tas+lse), baseline-patched-lse (cas+lse))
- for select, there is no clear winner but baseline-patched-lse (cas+lse)
perform better than others (2-4%).
- for update/tpcb like baseline-patched (cas) continue to outperform all
the 3 options (10-40%).
In fact, with lse enabled a regression (compared to baseline/head) is
observed.
[I am not surprised since MySQL showed the same behavior with lse of-course
with a lesser percentage].
I have repeated the test 2 times to confirm the behavior.
Also, to reduce noise I normally run 4 rounds discarding 1st round and
taking the median of the last 3 rounds.
In all, I see consistent numbers.
conf:
https://github.com/mysqlonarm/benchmark-suites/blob/master/pgsql-pbench/conf/pgsql.cnf/postgresql.conf
-----------------------------------------------------------------------------------------------------------------------------------------------
From all the observations till now following points are clear:
* Patch doesn't seem to make a significant difference with lse enabled.
Ir-respective of the machine (Kunpeng, Graviton2, M1). [infact introduces
regression with Kunpeng].
* Patch helps generate significant +ve difference in performace with lse
disabled.
Observed and Confirmed with both Kunpeng, Graviton2.
(not possible to disable lse on m1).
* Does the patch makes things worse with lse enabled.
* Graviton2: No (based on Alexander graph)
* M1: No (based on Tom's graph. Wondering why was debug build used
(--enable-debug?))
* Kunpeng: regression observed.
--------------
Should we enable lse?
Based on the comment from [1] I see pgsql aligns with decision made by
compiler/distribution vendors. If the compiler/distribution vendors
has not made something default then there could be reason for it.
-------------
Without lse as we have seen patch continue to score.
Effect of LSE needs to be wide studied. Scaling on some arch and regressing
on some needs to be understood may be at CPU vendor level.
------------------------------------------------------------------------------------------------------------------------------------------
Links:
[1]
https://www.postgresql.org/message-id/flat/099F69EE-51D3-4214-934A-1F28C0A1A7A7%40amazon.com
>
> Links
> 1.
> https://www.postgresql.org/message-id/CAPpHfdsGqVd6EJ4mr_RZVE5xSiCNBy4MuSvdTrKmTpM0eyWGpg%40mail.gmail.com
>
> ------
> Regards,
> Alexander Korotkov
>
--
Regards,
Krunal Bauskar
| Attachment | Content-Type | Size |
|---|---|---|
|
image/png | 62.0 KB |
In response to
- Re: Improving spin-lock implementation on ARM. at 2020-11-30 20:46:44 from Alexander Korotkov
Responses
- Re: Improving spin-lock implementation on ARM. at 2020-12-01 14:54:58 from Alexander Korotkov
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Tomas Vondra | 2020-12-01 12:50:59 | Re: Additional improvements to extended statistics |
| Previous Message | Bharath Rupireddy | 2020-12-01 12:04:04 | Consider Parallelism While Planning For REFRESH MATERIALIZED VIEW |