| From: | David Rowley <dgrowleyml(at)gmail(dot)com> |
|---|---|
| To: | Thomas Munro <thomas(dot)munro(at)gmail(dot)com> |
| Cc: | Andres Freund <andres(at)anarazel(dot)de>, Justin Pryzby <pryzby(at)telsasoft(dot)com>, John Naylor <john(dot)naylor(at)enterprisedb(dot)com>, Peter Geoghegan <pg(at)bowt(dot)ie>, pgsql-hackers <pgsql-hackers(at)postgresql(dot)org>, Robert Haas <rhaas(at)postgresql(dot)org> |
| Subject: | Re: A qsort template |
| Date: | 2022-04-10 22:34:27 |
| Message-ID: | CAApHDvokMee00Ca71znFW4=9B1Z7ZG2kBTUZsuewZ24cp74zOw@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
On Mon, 11 Apr 2022 at 09:44, Thomas Munro <thomas(dot)munro(at)gmail(dot)com> wrote:
> David Rowley privately reported a performance regression when sorting
> single ints with a lot of duplicates, in a case that previously hit
> qsort_ssup() but now hits qsort_tuple_int32() and then has to call the
> tiebreaker comparator. Note that this comes up only for sorts in a
> query, not for eg index builds which always have to tiebreak on item
> ptr. I don't have data right now but that'd likely be due to:
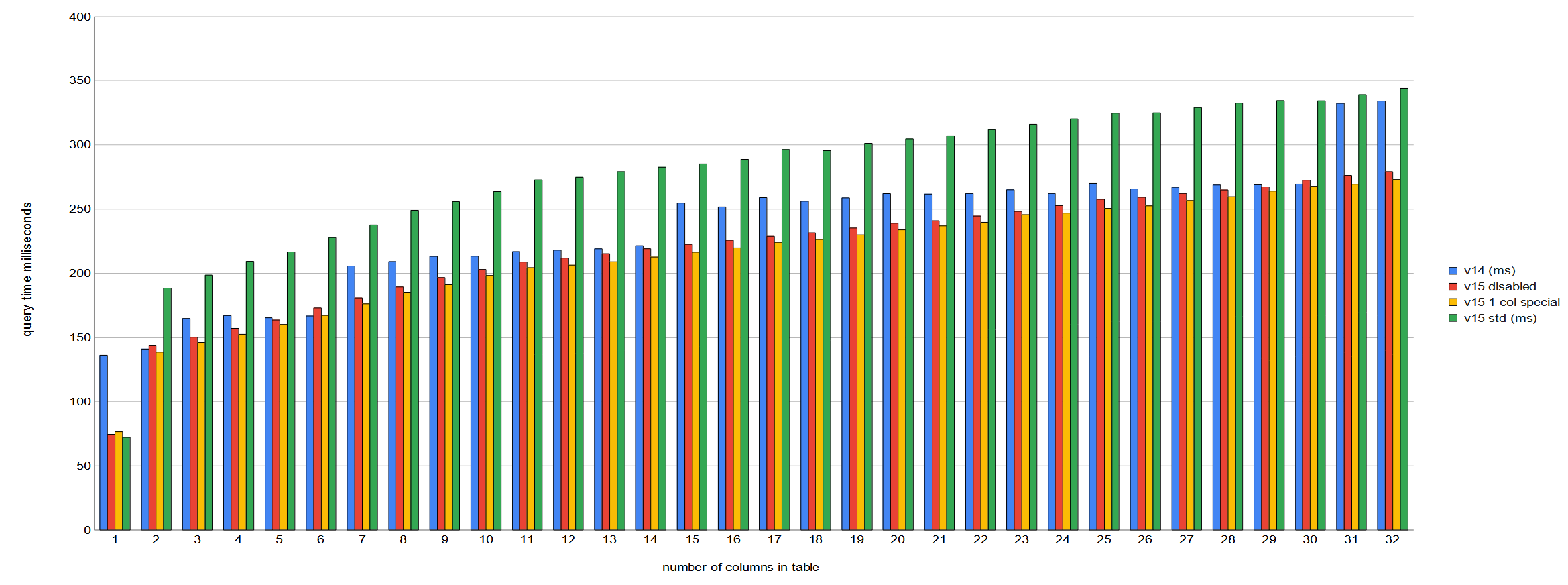
Yeah, I noticed this when running some sort benchmarks to compare v14
with master (as of Thursday last week).
The biggest slowdown I saw was the test that sorted 1 million tuples
on a BIGINT column with 100 distinct values. The test in question
does sorts on the same column each time, but continually adds columns,
which I was doing to check how wider tuples changed the performance
(this was for the exercise of 40af10b57 rather than this work).
With this particular test, v15 is about 15% *slower* than v14. I
didn't know what to blame at first, so I tried commenting out the sort
specialisations and got the results in the red bars in the graph. This
made it about 7.5% *faster* than v14. So looks like this patch is to
blame. I then hacked the comparator function that's used in the
specialisations for BIGINT to comment out the tiebreak to remove the
indirect function call, which happens to do nothing in this 1 column
sort case. The aim here was to get an idea what the performance would
be if there was a specialisation for single column sorts. That's the
yellow bars, which show about 10% *faster* than master.
| Attachment | Content-Type | Size |
|---|---|---|
| sorting_v14_vs_v15.ods | application/vnd.oasis.opendocument.spreadsheet | 79.1 KB |
| 1m_tup_mod_100.png | image/png | 93.4 KB |
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Matthias van de Meent | 2022-04-10 23:07:46 | Re: Improving btree performance through specializing by key shape, take 2 |
| Previous Message | Peter Geoghegan | 2022-04-10 22:03:36 | Re: Improving btree performance through specializing by key shape, take 2 |
{kind=link}