Re: A tidyup of pathkeys.c
| From: | David Rowley <dgrowleyml(at)gmail(dot)com> |
|---|---|
| To: | Chao Li <li(dot)evan(dot)chao(at)gmail(dot)com> |
| Cc: | PostgreSQL Developers <pgsql-hackers(at)lists(dot)postgresql(dot)org> |
| Subject: | Re: A tidyup of pathkeys.c |
| Date: | 2025-10-14 11:22:46 |
| Message-ID: | CAApHDvoidbqv5=WfmxRLP4_B3pV-eW7kJYw0xzYjTr7SMspJxQ@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
Thanks for having a look.
On Tue, 14 Oct 2025 at 21:15, Chao Li <li(dot)evan(dot)chao(at)gmail(dot)com> wrote:
> I have only a trivial comment. As you pull out the shared code into count_common_leading_pathkeys_ordered()/unordered(), it’s reasonable to make them inline, which ensures the new code has the same performance as before. However, I realized that truncate_useless_pathkeys() is not on a critical execution path, not making them inline won’t hurt very much. So, it’s up to you whether or not add “inline” to the two new functions.
What makes you think making them inline would make the performance the
same as before? The previous functions were not inlined, and I've not
made any changes that should affect the compiler's ability to choose
to inline these functions or not. These are static functions, so I'd
prefer to leave it up to the compiler to choose what it thinks is best
here. I expect the compiler probably inlines
count_common_leading_pathkeys_ordered() since it basically amounts to
just calling another function.
FWIW, I did try the performance using the schema generated with:
select 'create table t1 (' || string_agg('c'||n||' int',',') || ');'
from generate_Series(1,32)n;
select 'create index on t1 (' || string_agg('c'|| ((x+n)%32+1), ',')
|| ');' from generate_series(0,31)n, generate_Series(0,31) x group by
n;
and the query generated with:
select 'explain (costs off) select distinct * from t1 order by ' ||
string_agg(n::text,',') || ';' from generate_Series(1,32)n;
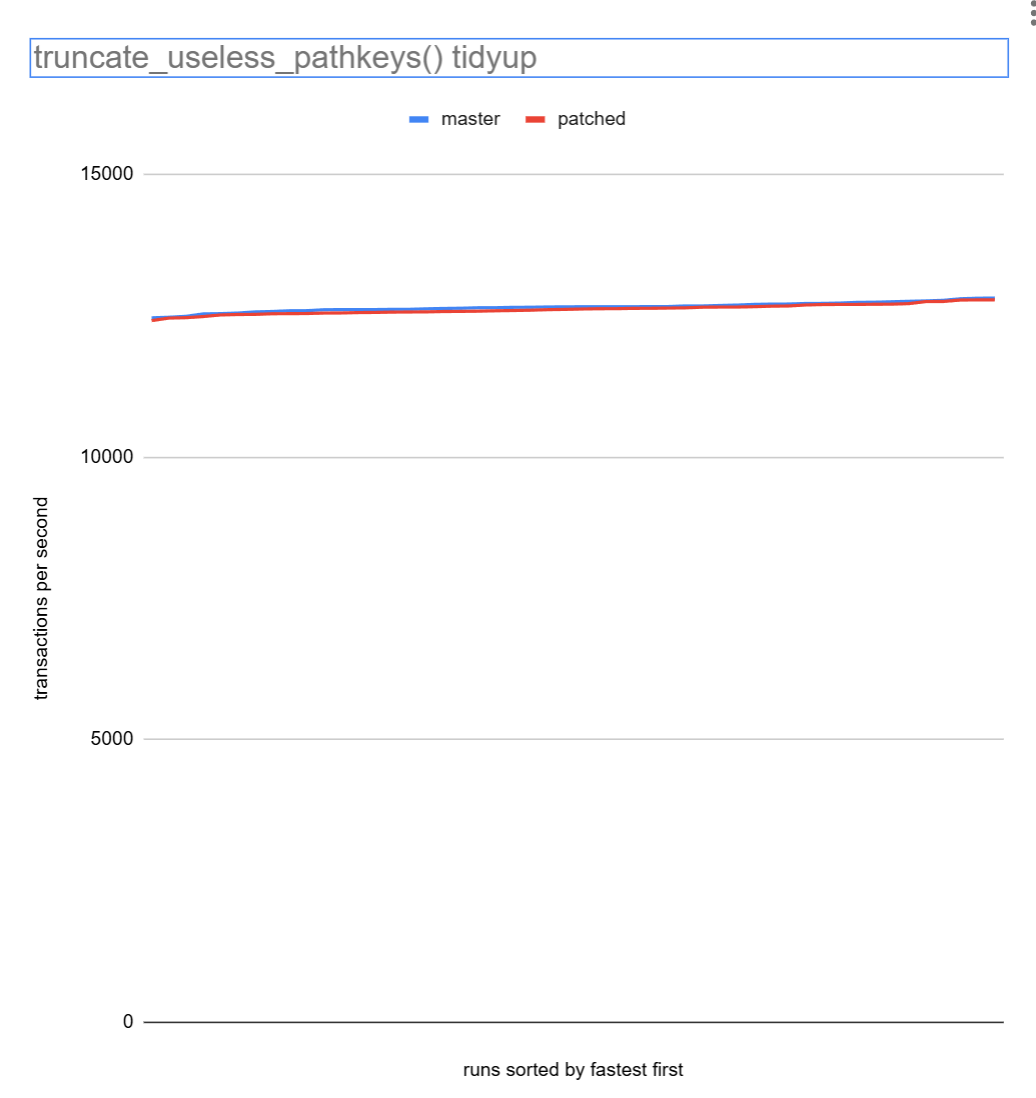
I ran it under pgbench -T 10 -c 20 -j 20 for 50 times, both patched
and unpatched. Patched *maybe* comes out a tiny bit faster, about
0.31% on average. The attached graph shows the results sorted by
fastest time first. So, at least not slower.
David
| Attachment | Content-Type | Size |
|---|---|---|
|
image/png | 39.7 KB |
In response to
- Re: A tidyup of pathkeys.c at 2025-10-14 08:14:51 from Chao Li
Responses
- Re: A tidyup of pathkeys.c at 2025-10-14 23:49:08 from Chao Li
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Álvaro Herrera | 2025-10-14 11:24:22 | Re: [PATCH] Add pg_get_trigger_ddl() to retrieve the CREATE TRIGGER statement |
| Previous Message | Matěj Klonfar | 2025-10-14 11:13:38 | [PROPOSAL] comments in repl_scanner |