Re: BufferAlloc: don't take two simultaneous locks
| From: | Yura Sokolov <y(dot)sokolov(at)postgrespro(dot)ru> |
|---|---|
| To: | Kyotaro Horiguchi <horikyota(dot)ntt(at)gmail(dot)com> |
| Cc: | pgsql-hackers(at)lists(dot)postgresql(dot)org, michail(dot)nikolaev(at)gmail(dot)com, x4mmm(at)yandex-team(dot)ru, andres(at)anarazel(dot)de, simon(dot)riggs(at)enterprisedb(dot)com |
| Subject: | Re: BufferAlloc: don't take two simultaneous locks |
| Date: | 2022-03-15 05:07:39 |
| Message-ID: | 91d6d0f9eae224d690833bc859753f79e36f2f3a.camel@postgrespro.ru |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
В Пн, 14/03/2022 в 14:57 +0300, Yura Sokolov пишет:
> В Пн, 14/03/2022 в 17:12 +0900, Kyotaro Horiguchi пишет:
> > At Mon, 14 Mar 2022 09:15:11 +0300, Yura Sokolov <y(dot)sokolov(at)postgrespro(dot)ru> wrote in
> > > В Пн, 14/03/2022 в 14:31 +0900, Kyotaro Horiguchi пишет:
> > > > I'd like to ask you to remove nalloced from partitions then add a
> > > > global atomic for the same use?
> > >
> > > I really believe it should be global. I made it per-partition to
> > > not overcomplicate first versions. Glad you tell it.
> > >
> > > I thought to protect it with freeList[0].mutex, but probably atomic
> > > is better idea here. But which atomic to chose: uint64 or uint32?
> > > Based on sizeof(long)?
> > > Ok, I'll do in next version.
> >
> > Current nentries is a long (= int64 on CentOS). And uint32 can support
> > roughly 2^32 * 8192 = 32TB shared buffers, which doesn't seem safe
> > enough. So it would be uint64.
> >
> > > Whole get_hash_entry look strange.
> > > Doesn't it better to cycle through partitions and only then go to
> > > get_hash_entry?
> > > May be there should be bitmap for non-empty free lists? 32bit for
> > > 32 partitions. But wouldn't bitmap became contention point itself?
> >
> > The code puts significance on avoiding contention caused by visiting
> > freelists of other partitions. And perhaps thinks that freelist
> > shortage rarely happen.
> >
> > I tried pgbench runs with scale 100 (with 10 threads, 10 clients) on
> > 128kB shared buffers and I saw that get_hash_entry never takes the
> > !element_alloc() path and always allocate a fresh entry, then
> > saturates at 30 new elements allocated at the medium of a 100 seconds
> > run.
> >
> > Then, I tried the same with the patch, and I am surprized to see that
> > the rise of the number of newly allocated elements didn't stop and
> > went up to 511 elements after the 100 seconds run. So I found that my
> > concern was valid. The change in dynahash actually
> > continuously/repeatedly causes lack of free list entries. I'm not
> > sure how much the impact given on performance if we change
> > get_hash_entry to prefer other freelists, though.
>
> Well, it is quite strange SharedBufHash is not allocated as
> HASH_FIXED_SIZE. Could you check what happens with this flag set?
> I'll try as well.
>
> Other way to reduce observed case is to remember freelist_idx for
> reused entry. I didn't believe it matters much since entries migrated
> netherless, but probably due to some hot buffers there are tention to
> crowd particular freelist.
Well, I did both. Everything looks ok.
> > By the way, there's the following comment in StrategyInitalize.
> >
> > > * Initialize the shared buffer lookup hashtable.
> > > *
> > > * Since we can't tolerate running out of lookup table entries, we must be
> > > * sure to specify an adequate table size here. The maximum steady-state
> > > * usage is of course NBuffers entries, but BufferAlloc() tries to insert
> > > * a new entry before deleting the old. In principle this could be
> > > * happening in each partition concurrently, so we could need as many as
> > > * NBuffers + NUM_BUFFER_PARTITIONS entries.
> > > */
> > > InitBufTable(NBuffers + NUM_BUFFER_PARTITIONS);
> >
> > "but BufferAlloc() tries to insert a new entry before deleting the
> > old." gets false by this patch but still need that additional room for
> > stashed entries. It seems like needing a fix.
Removed whole paragraph because fixed table without extra entries works
just fine.
I lost access to Xeon 8354H, so returned to old Xeon X5675.
128MB and 1GB shared buffers
pgbench with scale 100
select_only benchmark, unix sockets.
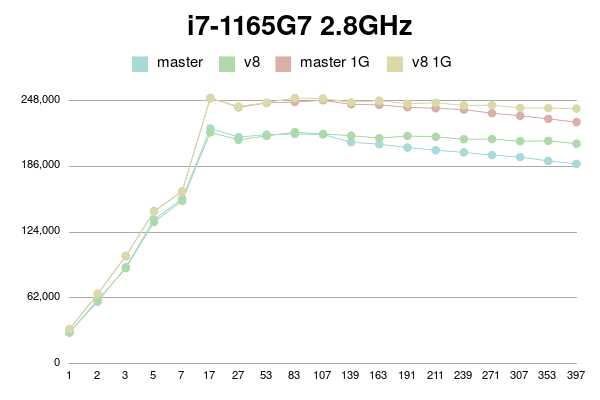
Notebook i7-1165G7:
conns | master | v8 | master 1G | v8 1G
--------+------------+------------+------------+------------
1 | 29614 | 29285 | 32413 | 32784
2 | 58541 | 60052 | 65851 | 65938
3 | 91126 | 90185 | 101404 | 101956
5 | 135809 | 133670 | 143783 | 143471
7 | 155547 | 153568 | 162566 | 162361
17 | 221794 | 218143 | 250562 | 250136
27 | 213742 | 211226 | 241806 | 242594
53 | 216067 | 214792 | 245868 | 246269
83 | 216610 | 218261 | 246798 | 250515
107 | 216169 | 216656 | 248424 | 250105
139 | 208892 | 215054 | 244630 | 246439
163 | 206988 | 212751 | 244061 | 248051
191 | 203842 | 214764 | 241793 | 245081
211 | 201304 | 213997 | 240863 | 246076
239 | 199313 | 211713 | 239639 | 243586
271 | 196712 | 211849 | 236231 | 243831
307 | 194879 | 209813 | 233811 | 241303
353 | 191279 | 210145 | 230896 | 241039
397 | 188509 | 207480 | 227812 | 240637
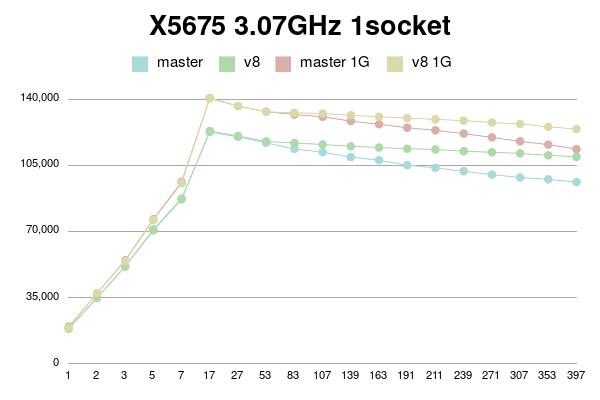
X5675 1 socket:
conns | master | v8 | master 1G | v8 1G
--------+------------+------------+------------+------------
1 | 18590 | 18473 | 19652 | 19051
2 | 34899 | 34799 | 37242 | 37432
3 | 51484 | 51393 | 54750 | 54398
5 | 71037 | 70564 | 76482 | 75985
7 | 87391 | 86937 | 96185 | 95433
17 | 122609 | 123087 | 140578 | 140325
27 | 120051 | 120508 | 136318 | 136343
53 | 116851 | 117601 | 133338 | 133265
83 | 113682 | 116755 | 131841 | 132736
107 | 111925 | 116003 | 130661 | 132386
139 | 109338 | 115011 | 128319 | 131453
163 | 107661 | 114398 | 126684 | 130677
191 | 105000 | 113745 | 124850 | 129909
211 | 103607 | 113347 | 123469 | 129302
239 | 101820 | 112428 | 121752 | 128621
271 | 100060 | 111863 | 119743 | 127624
307 | 98554 | 111270 | 117650 | 126877
353 | 97530 | 110231 | 115904 | 125351
397 | 96122 | 109471 | 113609 | 124150
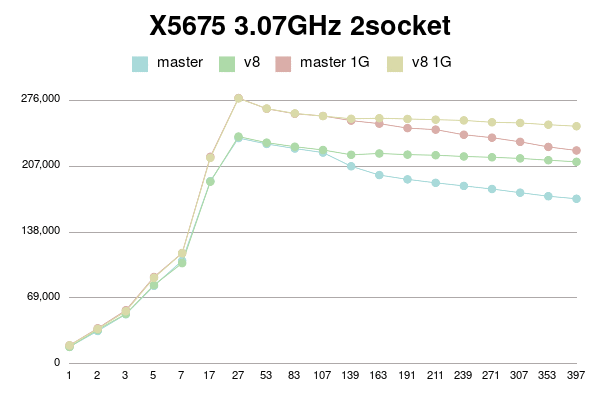
X5675 2 socket:
conns | master | v8 | master 1G | v8 1G
--------+------------+------------+------------+------------
1 | 17815 | 17577 | 19321 | 19187
2 | 34312 | 35655 | 37121 | 36479
3 | 51868 | 52165 | 56048 | 54984
5 | 81704 | 82477 | 90945 | 90109
7 | 107937 | 105411 | 116015 | 115810
17 | 191339 | 190813 | 216899 | 215775
27 | 236541 | 238078 | 278507 | 278073
53 | 230323 | 231709 | 267226 | 267449
83 | 225560 | 227455 | 261996 | 262344
107 | 221317 | 224030 | 259694 | 259553
139 | 206945 | 219005 | 254817 | 256736
163 | 197723 | 220353 | 251631 | 257305
191 | 193243 | 219149 | 246960 | 256528
211 | 189603 | 218545 | 245362 | 255785
239 | 186382 | 217229 | 240006 | 255024
271 | 183141 | 216359 | 236927 | 253069
307 | 179275 | 215218 | 232571 | 252375
353 | 175559 | 213298 | 227244 | 250534
397 | 172916 | 211627 | 223513 | 248919
Strange thing: both master and patched version has higher
peak tps at X5676 at medium connections (17 or 27 clients)
than in first october version [1]. But lower tps at higher
connections number (>= 191 clients).
I'll try to bisect on master this unfortunate change.
October master was 2d44dee0281a1abf and today's is 7e12256b478b895
(There is small possibility that I tested with TCP sockets
in october and with UNIX sockets today and that gave difference.)
[1] https://postgr.esq/m/1edbb61981fe1d99c3f20e3d56d6c88999f4227c.camel%40postgrespro.ru
-------
regards
Yura Sokolov
Postgres Professional
y(dot)sokolov(at)postgrespro(dot)ru
| Attachment | Content-Type | Size |
|---|---|---|
| v8-bufmgr-lock-improvements.patch | text/x-patch | 30.6 KB |
|
image/gif | 12.8 KB |
|
image/gif | 12.9 KB |
|
image/gif | 12.3 KB |
In response to
- Re: BufferAlloc: don't take two simultaneous locks at 2022-03-14 11:57:38 from Yura Sokolov
Responses
- Re: BufferAlloc: don't take two simultaneous locks at 2022-03-15 07:25:45 from Kyotaro Horiguchi
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Kyotaro Horiguchi | 2022-03-15 06:09:26 | Re: standby recovery fails (tablespace related) (tentative patch and discussion) |
| Previous Message | Amit Kapila | 2022-03-15 04:46:19 | Re: Column Filtering in Logical Replication |