Re: [HACKERS] Proposal for CSN based snapshots
| From: | Alexander Kuzmenkov <a(dot)kuzmenkov(at)postgrespro(dot)ru> |
|---|---|
| To: | Alexander Korotkov <a(dot)korotkov(at)postgrespro(dot)ru> |
| Cc: | Robert Haas <robertmhaas(at)gmail(dot)com>, Amit Kapila <amit(dot)kapila16(at)gmail(dot)com>, Michael Paquier <michael(dot)paquier(at)gmail(dot)com>, Heikki Linnakangas <hlinnaka(at)iki(dot)fi>, Andres Freund <andres(at)anarazel(dot)de>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Dilip Kumar <dilipbalaut(at)gmail(dot)com>, Jeff Davis <pgsql(at)j-davis(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com>, Greg Stark <stark(at)mit(dot)edu>, Andres Freund <andres(at)2ndquadrant(dot)com>, Rajeev rastogi <rajeev(dot)rastogi(at)huawei(dot)com>, Markus Wanner <markus(at)bluegap(dot)ch>, Ants Aasma <ants(at)cybertec(dot)at>, Bruce Momjian <bruce(at)momjian(dot)us>, obartunov <obartunov(at)postgrespro(dot)ru>, Teodor Sigaev <teodor(at)postgrespro(dot)ru>, Borodin Vladimir <root(at)simply(dot)name> |
| Subject: | Re: [HACKERS] Proposal for CSN based snapshots |
| Date: | 2017-12-14 18:55:09 |
| Message-ID: | 81b33c6b-86db-9eb6-5f37-5cd517a4b0f4@postgrespro.ru |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
El 08/12/17 a las 14:59, Alexander Korotkov escribió:
> These results look promising for me. Could you try benchmarking using
> more workloads including read-only and mixed mostly-read workloads?
> You can try same benchmarks I used in my talk about CSN in pgconf.eu
> <http://pgconf.eu> [1] slides 19-25 (and you're welcome to invent more
> benchmakrs yourself)
>
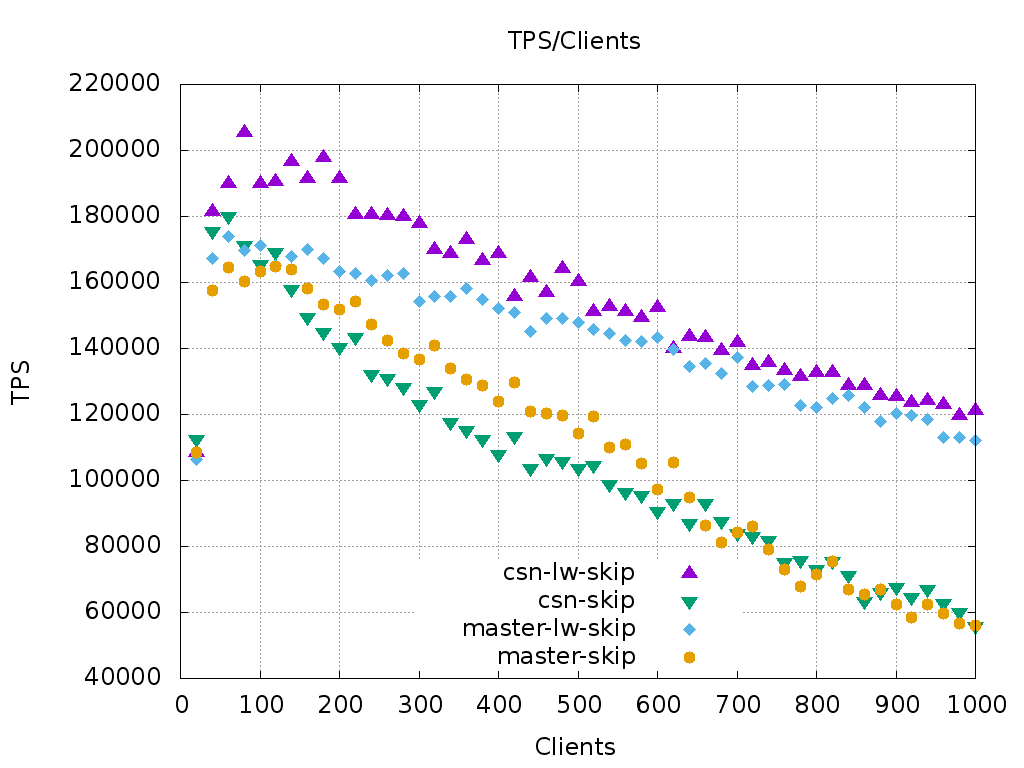
Sure, here are some more benchmarks.
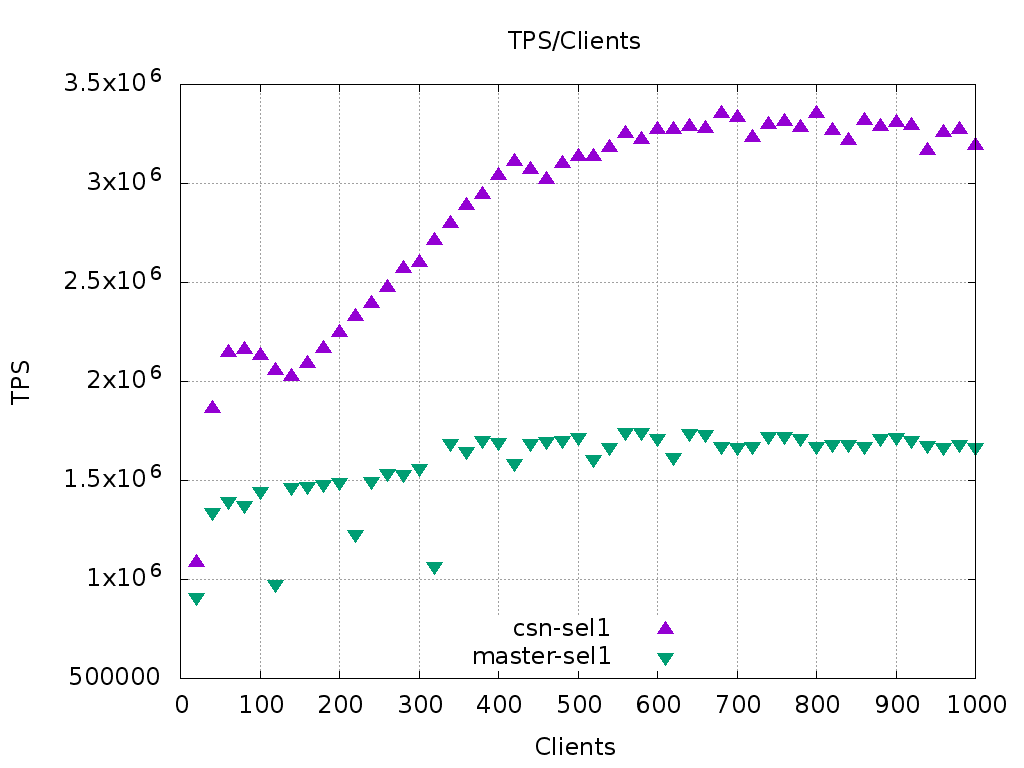
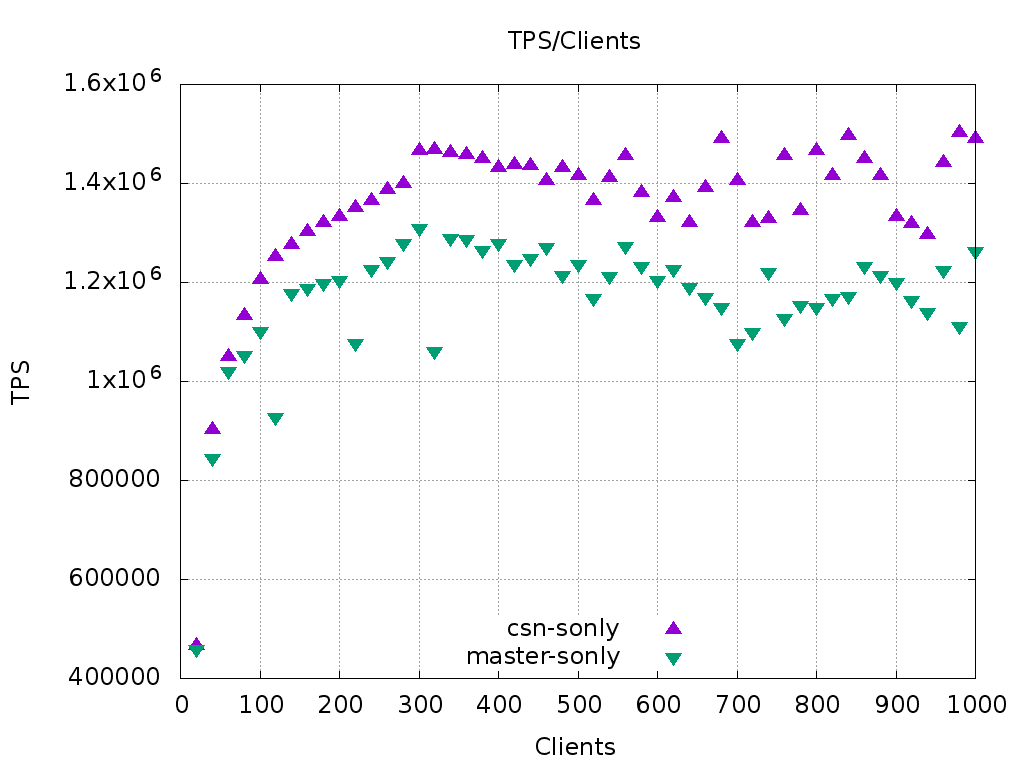
I've already had measured the "skip some updates" and "select-only"
pgbench variants, and also a simple "select 1" query. These are for
scale 1500 and for 20 to 1000 connections. The graphs are attached.
"select 1", which basically benchmarks snapshot taking, shows an
impressive twofold increase in TPS over master, but this is to be
expected. "select-only" stabilizes at 20% higher than master.
Interesting to note is that these select-only scenarios almost do not
degrade with growing client count.
For the "skip some updates" scenario, CSN is slightly slower than
master, but this is improved by the LWLock patch I mentioned upthread.
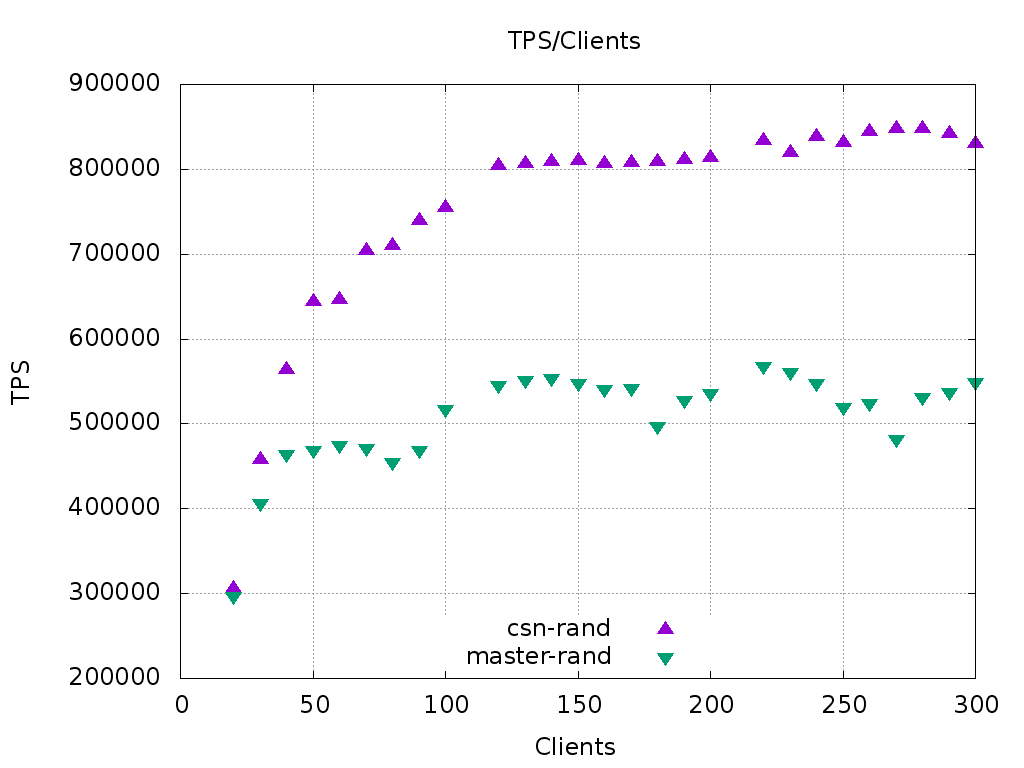
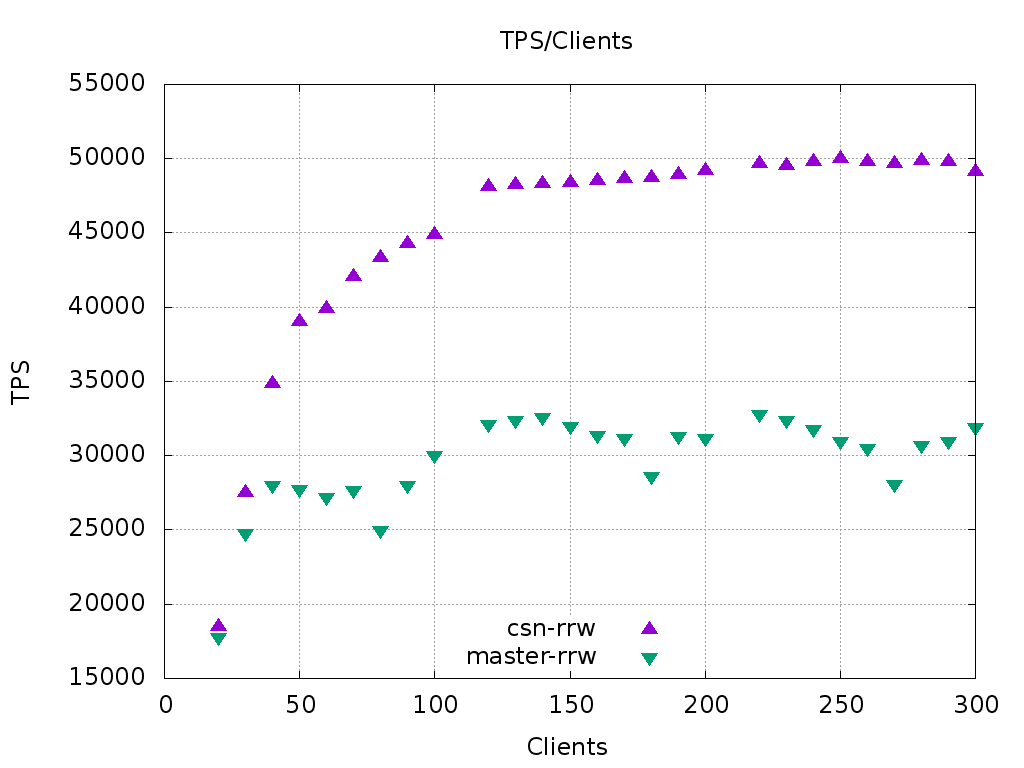
I also replicated the setup from your slides 23 and 25. I used scale 500
and client counts 20-300, and probably the same 72-core Xeon.
Slide 23 shows 22% write and 78% read queries, that is "-b select-only(at)9
-b tpcb-like(at)1". The corresponding picture is called "random.png". The
absolute numbers are somewhat lower for my run, but CSN is about 40%
faster than master, like the CSN-rewrite variant.
Slide 25 is a custom script called "rrw" with extra 20 read queries. We
can see that since your run the master has improved much, and the
current CSN shows the same general behaviour as CSN-rewrite, although
being slower in absolute numbers.
> Also, I wonder how current version of CSN patch behaves in worst case
> when we have to scan the table with a lot of unique xid (and
> correspondingly have to do a lot of csnlog lookups)? See [1] slide
> 18. This worst case was significant part of my motivation to try
> "rewrite xid with csn" approach. Please, find simple extension I used
> to fill table with random xmins in the attachment.
>
OK, let's summarize how the worst case in question works. It happens
when the tuples have a wide range of xmins and no hint bits. All
visibility checks have to go to clog then. Fortunately, on master we
also set hint bits during these checks, and the subsequent scans can
determine visibility using just the hint bits and the current snapshot.
This makes the subsequent scans run much faster. With CSN, this is not
enough, and the visibility checks always go to CSN log for all the
transactions newer than global xmin. This can become very slow if there
is a long-running transaction that holds back the global xmin.
I made a simple test to see these effects. The procedure is as follows.
I start a transaction in psql; that will be our long-running
transaction. Next, I run pgbench for a minute, and randomize the tuple
xmins in "pgbench_accounts" using your extension. Then I run "select
sum(abalance) from pgbench_accounts" twice, and record the durations.
Here is a table with the results (50M tuples, 1M transactions for master
and 400k for CSN):
Branch scan 1, s scan 2, s
--------------------------------
CSN 80 80
master 13 3.5
So, we are indeed seeing the expected results. Significant slowdown with
long-running transaction is an important problem for this patch. Even
the first scan is much slower, because a CSN log page contains 16 times
less transactions than a clog page, and we have the same number of
buffers (max 128) for them. When the range of xids is wide, we spend
most of the time loading and unloading the pages. I believe it can be
improved by using more buffers for CSN log. I did some work in this
direction, namely, made SLRUs use a dynahash table instead of linear
search for page->buffer lookups. This is included in the v8 I posted
earlier, but it should probably be done as a separate patch.
--
Alexander Kuzmenkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
| Attachment | Content-Type | Size |
|---|---|---|
|
image/png | 12.4 KB |
|
image/png | 12.4 KB |
|
image/png | 14.4 KB |
|
image/png | 14.4 KB |
|
image/png | 17.8 KB |
In response to
- Re: [HACKERS] Proposal for CSN based snapshots at 2017-12-08 11:59:42 from Alexander Korotkov
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Robert Haas | 2017-12-14 19:26:40 | Re: [HACKERS] Surjective functional indexes |
| Previous Message | Merlin Moncure | 2017-12-14 18:53:42 | Re: procedures and plpgsql PERFORM |