Re: [PATCH] Add sortsupport for range types and btree_gist
| From: | Bernd Helmle <mailings(at)oopsware(dot)de> |
|---|---|
| To: | pgsql-hackers(at)lists(dot)postgresql(dot)org |
| Subject: | Re: [PATCH] Add sortsupport for range types and btree_gist |
| Date: | 2022-11-30 17:25:25 |
| Message-ID: | 77f4bacbeb9d223f90b3a0bd55ef7d65407bfddd.camel@oopsware.de |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
Hi,
No deep code review yet, but CF is approaching its end and i didn't
have time to look at this earlier :/
Below are some things i've tested so far.
Am Mittwoch, dem 15.06.2022 um 12:45 +0200 schrieb Christoph Heiss:
> Testing was done using following setup, with about 50 million rows:
>
> CREATE EXTENSION btree_gist;
> CREATE TABLE t (id uuid, block_range int4range);
> CREATE INDEX ON before USING GIST (id, block_range);
> COPY t FROM '..' DELIMITER ',' CSV HEADER;
>
> using
>
> SELECT * FROM t WHERE id = '..' AND block_range && '..'
>
> as test query, using a unpatched instance and one with the patch
> applied.
>
> Some stats for fetching 10,000 random rows using the query above,
> 100 iterations to get good averages.
>
Here are my results with repeating this:
HEAD:
-- token index (buffering=auto)
CREATE INDEX Time: 700213,110 ms (11:40,213)
HEAD patched:
-- token index (buffering=auto)
CREATE INDEX Time: 136229,400 ms (02:16,229)
So index creation speed on the test set (table filled with the tokens
and then creating the index afterwards) gets a lot of speedup with this
patch and default buffering strategy.
> The benchmarking was done on a unpatched instance compiled using the
> > exact same options as with the patch applied.
> > [ Results are noted in a unpatched -> patched fashion. ]
> >
> > First set of results are after the initial CREATE TABLE, CREATE
> INDEX
> > and a COPY to the table, thereby incrementally building the index.
> >
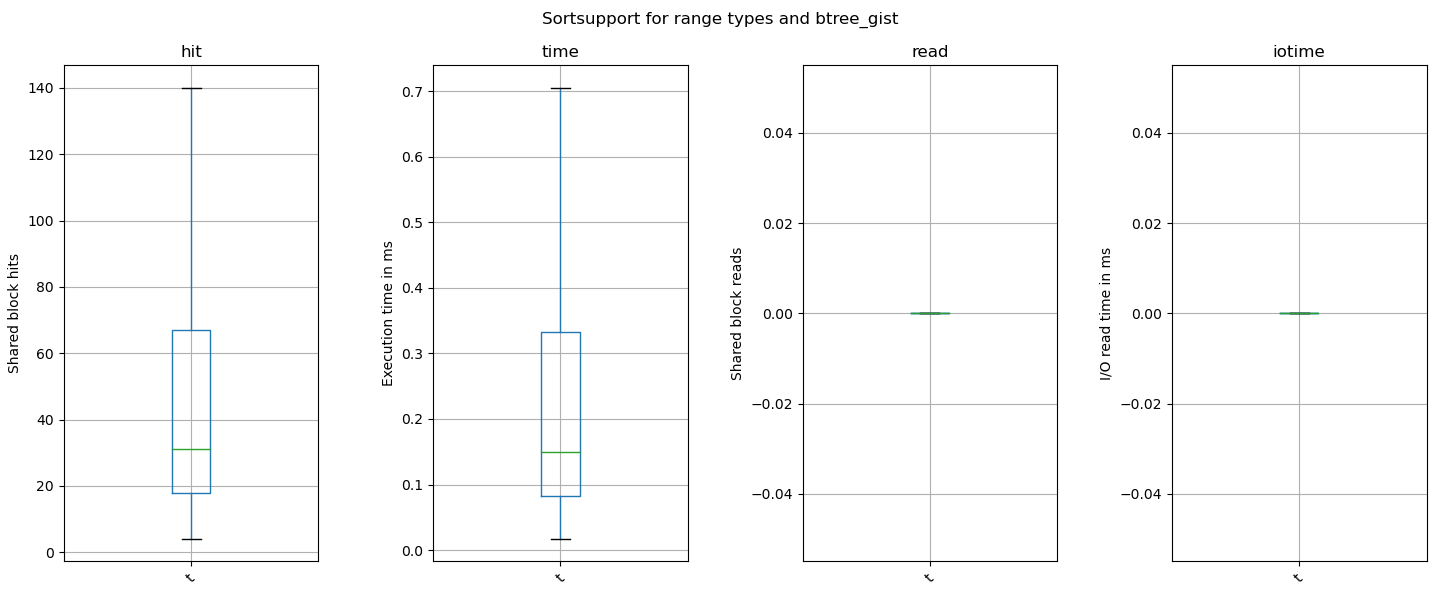
> > Shared Hit Blocks (average): 110.97 -> 78.58
> > Shared Read Blocks (average): 58.90 -> 47.42
> > Execution Time (average): 1.10 -> 0.83 ms
> > I/O Read Time (average): 0.19 -> 0.15 ms
I've changed this a little and did the following:
CREATE EXTENSION btree_gist;
CREATE TABLE t (id uuid, block_range int4range);
COPY t FROM '..' DELIMITER ',' CSV HEADER;
CREATE INDEX ON before USING GIST (id, block_range);
So creating the index _after_ having loaded the tokens.
My configuration was:
shared_buffers = 4G
max_wal_size = 6G
effective_cache_size = 4g # (default, index fits)
maintenance_work_mem = 1G
Here are my numbers from the attached benchmark script
HEAD -> HEAD patched:
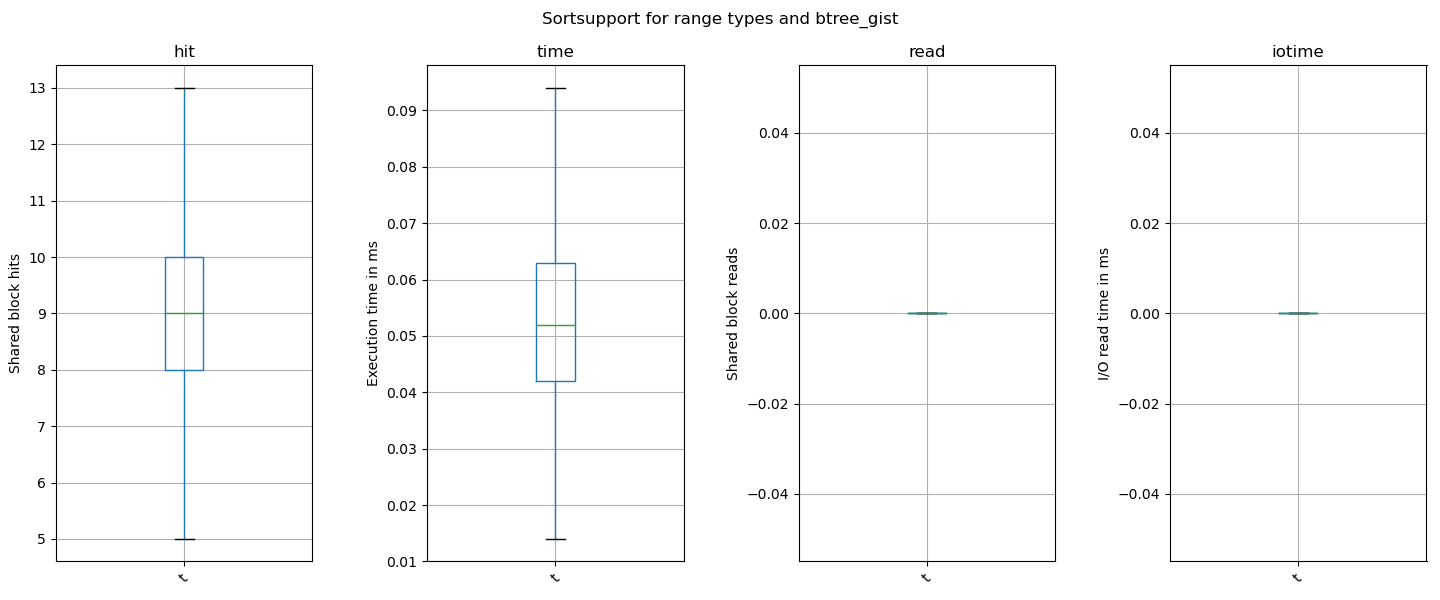
Shared Hit Blocks (avg) : 76.81 -> 9.17
Shared Read Blocks (avg): 0.43 -> 0.11
Execution Time (avg) : 0.40 -> 0.05
IO Read Time (avg) : 0.001 -> 0.0007
So with these settings i see an improvement with the provided test set.
Since this patches adds sortsupport for all other existing opclasses, i
thought to give it a try with another test set. What i did was to adapt
the benchmark script (see attached) to use the "pgbench_accounts" table
which i changed to instead using the primary key to have a btree_gist
index on column "aid".
I let pgbench fill its tables with scale = 1000, dropped the primary
key, create the btree_gist on "aid" with default buffering strategy:
pgbench -s 1000 -i bernd
ALTER TABLE pgbench_accounts DROP CONSTRAINT pgbench_accounts_pkey ;
CREATE INDEX ON pgbench_accounts USING gist(aid);
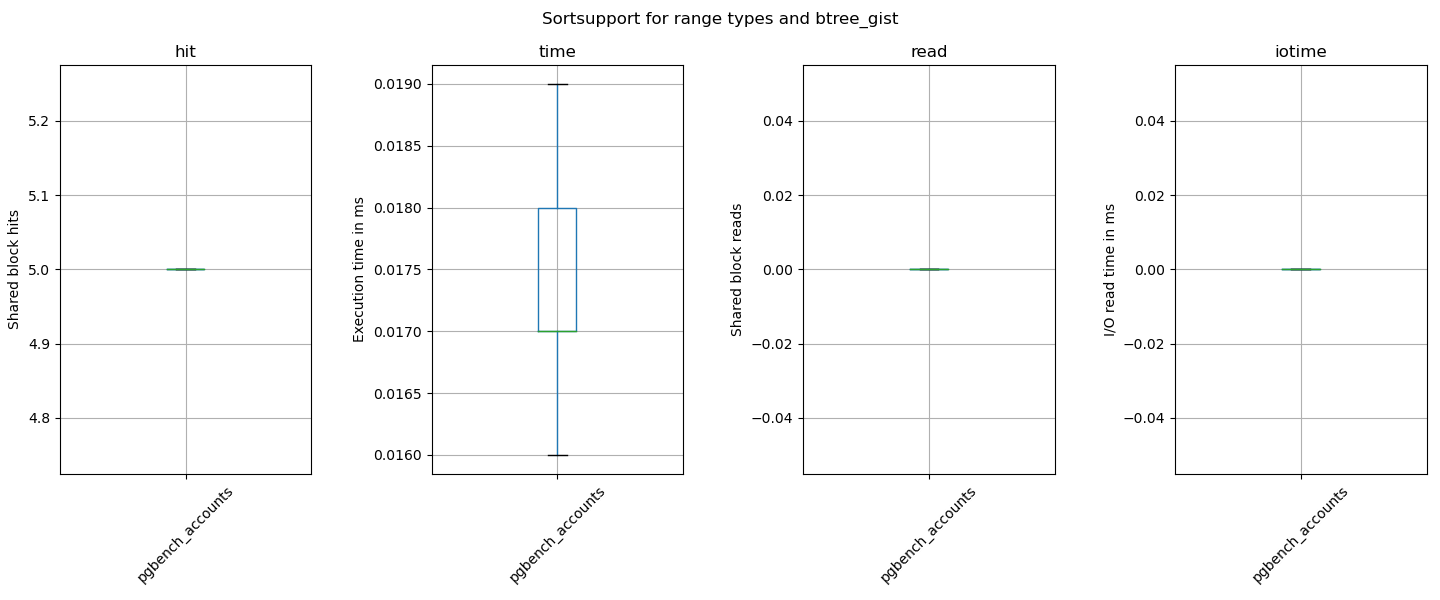
Ran the benchmark script bench-gist-pgbench_accounts.py:
The numbers are:
HEAD -> HEAD patched
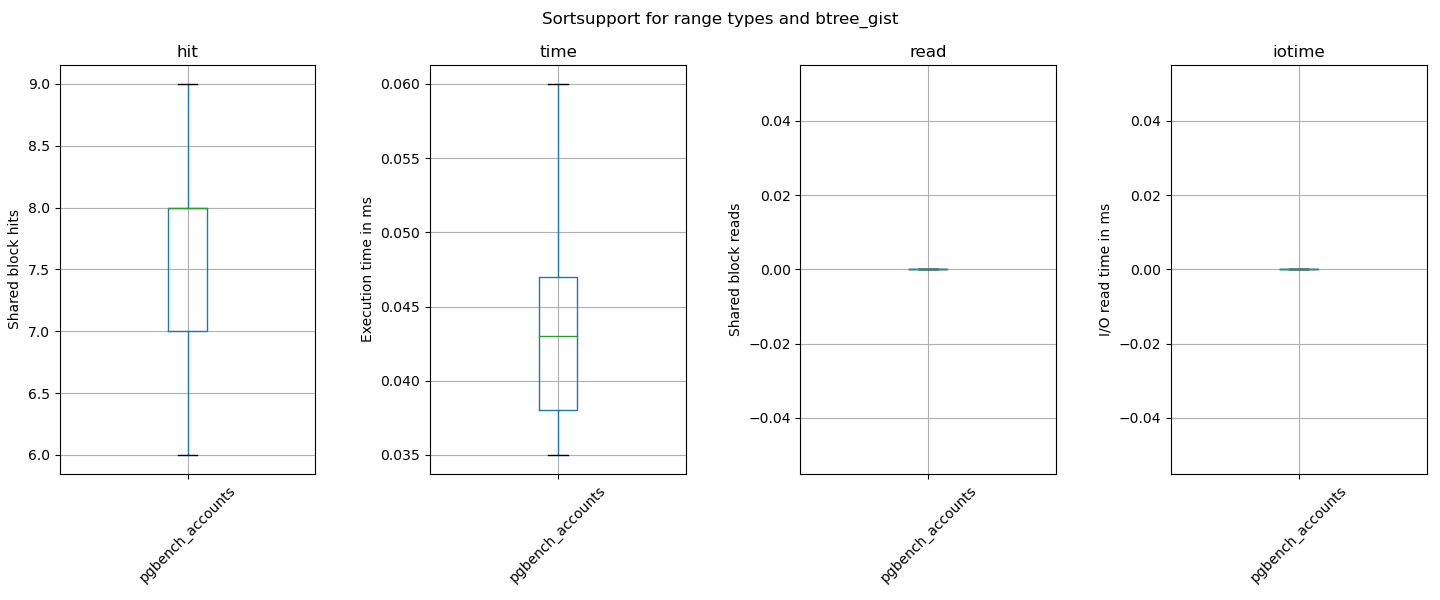
Shared Hit Blocks (avg) : 4.85 -> 8.75
Shared Read Blocks (avg): 0.14 -> 0.17
Execution Time (avg) : 0.01 -> 0.05
IO Read Time (avg) : 0.0003 -> 0.0009
So numbers got worse here. You can uncover this when using pgbench
against that modified table in a much more worse outcome.
Running
pgbench -s 1000 -c 16 -j 16 -S -Mprepared -T 300
on my workstation at least 3 times gives me the following numbers:
HEAD:
tps = 215338.784398 (without initial connection time)
tps = 212826.513727 (without initial connection time)
tps = 212102.857891 (without initial connection time)
HEAD patched:
tps = 126487.796716 (without initial connection time)
tps = 125076.391528 (without initial connection time)
tps = 124538.946388 (without initial connection time)
So this doesn't look good. While this patch gets a real improvement for
the provided tokens, it makes performance for at least int4 on this
test worse. Though the picture changes again if you build the index
buffered:
tps = 198409.248911 (without initial connection time)
tps = 194431.827394 (without initial connection time)
tps = 195657.532281 (without initial connection time)
which is again close to current HEAD (i have no idea why it is even
*that* slower, since "buffered=on" shouldn't employ sortsupport, no?).
Of course, built time for the index in this case is much slower again:
-- pgbench_accounts index (buffered)
CREATE INDEX Time: 900912,924 ms (15:00,913)
So while providing a huge improvement on index creation speed it's
sometimes still required to carefully check the index quality.
[...]
> Most of the sortsupport for btree_gist was implemented by re-using
> already existing infrastructure. For the few remaining types (bit,
> bool,
> cash, enum, interval, macaddress8 and time) I manually implemented
> them
> directly in btree_gist.
> It might make sense to move them into the backend for uniformity, but
> I
> wanted to get other opinions on that first.
Hmm i'd say we leave them in the contrib module until they are required
somewhere else, too or make a separate patch for them? Do we have plans
to have such requirement in the backend already?
Attached is a rebased patch against current HEAD.
Thanks
Bernd
| Attachment | Content-Type | Size |
|---|---|---|
| bench-gist-pgbench_accounts.py | text/x-python3 | 1.6 KB |
|
image/png | 42.6 KB |
|
image/png | 46.1 KB |
|
image/png | 40.2 KB |
|
image/png | 46.2 KB |
| benchmark.pgsql.config | text/plain | 170 bytes |
In response to
- [PATCH] Add sortsupport for range types and btree_gist at 2022-06-15 10:45:07 from Christoph Heiss
Responses
- Re: [PATCH] Add sortsupport for range types and btree_gist at 2024-01-10 00:00:00 from jian he
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Tom Lane | 2022-11-30 17:31:55 | Re: New docs chapter on Transaction Management and related changes |
| Previous Message | Alvaro Herrera | 2022-11-30 17:20:22 | Re: New docs chapter on Transaction Management and related changes |