| From: | Ildar Musin <i(dot)musin(at)postgrespro(dot)ru> |
|---|---|
| To: | Fabien COELHO <coelho(at)cri(dot)ensmp(dot)fr> |
| Cc: | pgsql-hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: General purpose hashing func in pgbench |
| Date: | 2017-12-21 11:38:14 |
| Message-ID: | 699225ee-c30c-b22e-4028-415e9eab26b2@postgrespro.ru |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
Hello Fabien,
20/12/2017 10:36, Fabien COELHO пишет:
> As there may be several hash functions included in the long run. I'd
> suggest that the hash function should be named more precisely, eg
> "hash_fnv1a".
Done. Added "hash_murmur2" too, see below.
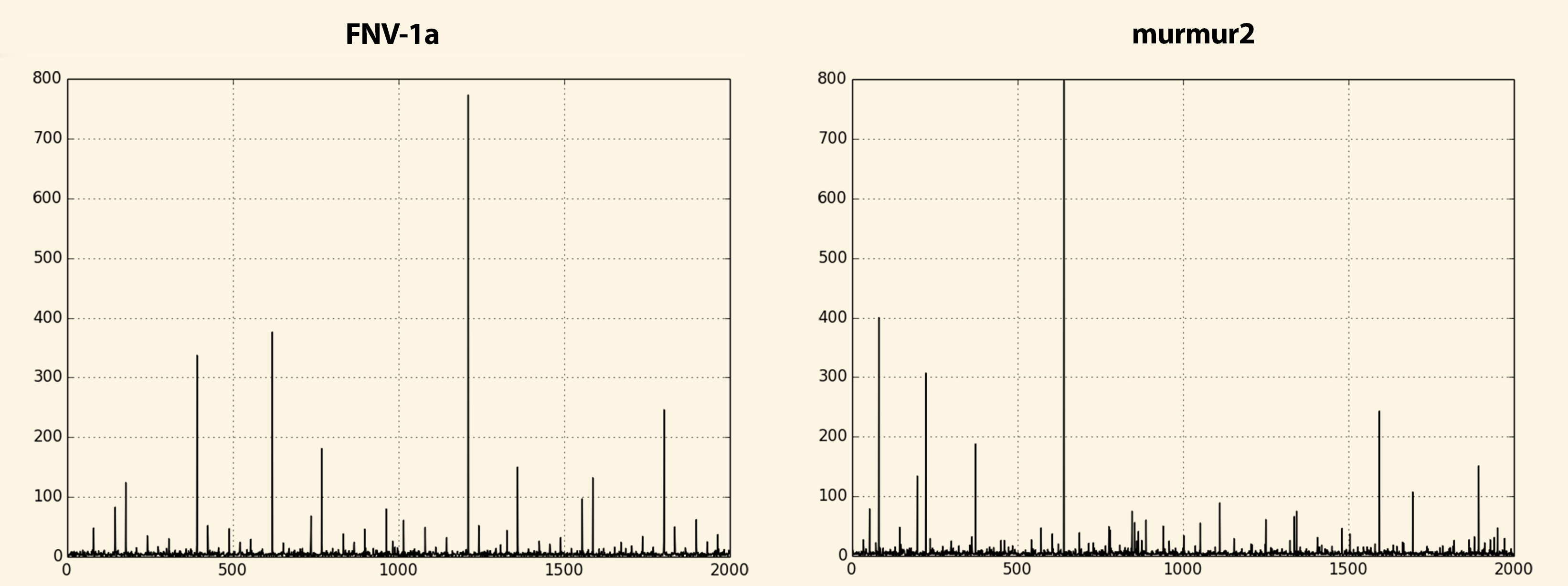
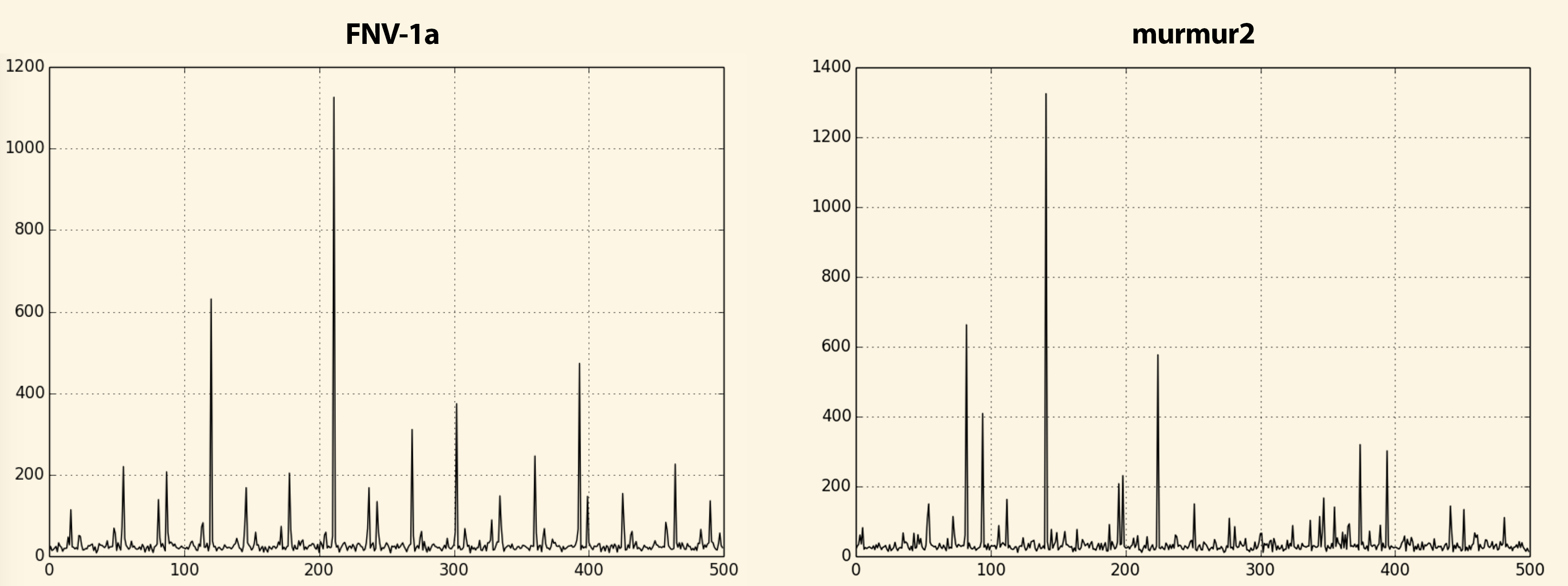
> The image looks like the distribution is more regularly scattered than
> actually randomized... Maybe this is because the first highest 256
> values are really scattered by the process multiply/modulo process. Or
> maybe this is an optical effect?
>
After your comment I searched the internet for different hashing
algorithms comparison wrt randomness and found an interesting post at
stackexchange [1]. According to author's research the murmur2 algorithm
has the best randomness rate (among those he tested). So I implemented
it (using original code by Austin Appleby as a reference [2]) and
conducted few experiments. Results are in attachement. Indeed, comparing
to murmur2 the FNV distribution seems pretty regular.
> ISTM that there are undesired utf8 chars in a comment. Should be kept
> ASCII.
Oops, I copy-pasted the algorithm name from wikipedia, didn't notice
there were some fancy unicode hyphens.
> I would put the actual hash computation in a separate function rather
> than inlined in the evaluator.
Done.
> Add the submission to the next CF?
I think it is not commitfest ready yet -- I need to add some
documentation and tests first.
[1]
https://softwareengineering.stackexchange.com/questions/49550/which-hashing-algorithm-is-best-for-uniqueness-and-speed
[2] https://github.com/aappleby/smhasher/blob/master/src/MurmurHash2.cpp
--
Ildar Musin
Postgres Professional:
http://www.postgrespro.com
Russian Postgres Company
| Attachment | Content-Type | Size |
|---|---|---|
| pgbench_hash_v2.patch | text/plain | 2.5 KB |
| fnv_vs_murmur2_2K.png | image/png | 473.1 KB |
| fnv_vs_murmur2_500.png | image/png | 627.9 KB |
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Craig Ringer | 2017-12-21 11:42:09 | Re: The pg_indent on on ftp is outdated |
| Previous Message | David Rowley | 2017-12-21 11:17:50 | Re: [HACKERS] path toward faster partition pruning |
{kind=link}
{kind=link}