Fuzzy substring searching with the pg_trgm extension
| From: | Artur Zakirov <a(dot)zakirov(at)postgrespro(dot)ru> |
|---|---|
| To: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Fuzzy substring searching with the pg_trgm extension |
| Date: | 2015-12-18 19:43:40 |
| Message-ID: | 567461EC.4030803@postgrespro.ru |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
Hello.
PostgreSQL has a contrib module named pg_trgm. It is used to the fuzzy
text search. It provides some functions and operators for determining
the similarity of the given texts using trigram matching.
At the moment, in pg_trgm both the similarity function and the %
operator match two strings expecting that they are similar entirely. But
they give bad results if we want to find documents by a query which is
substring of a document.
For this purpose we need a new operator which enables to find strings
that have a fragment most similar to the given string. This patch adds
some functions and operator:
- function substring_similarity - Returns a number that indicates how
similar the first string to the most similar substring of the second
string. The range of the result is zero (indicating that the two strings
are completely dissimilar) to one (indicating that the first string is
identical to substring of the second substring).
- function show_substring_limit - Returns the current similarity
threshold used by the <% operator. This sets the minimum substring
similarity between two phrases.
- function set_substring_limit - Sets the current substring similarity
threshold that is used by the <% operator. The threshold must be between
0 and 1 (default is 0.6). Returns the same value passed in.
- operator <% - Returns true if its arguments have a substring
similarity that is greater than the current substring similarity
threshold set by set_substring_limit. Has an index support.
Substring similarity algorithm
------------------------------
1 - generate trigram arrays for a query string and for a text.
2 - create an array that contains trigrams from both arrays from the
step 1 and contains position (index) for trigrams from the second array.
The array stores the following structure:
typedef struct
{
trgm t; // Trigram
int i; // -1 for the first array and position (index) in
the second array
} ptrgm;
3 - sort the array from the step 2.
4 - search trigrams from a query string in a given text and store a
search result in the new boolean array using the array from the step 2.
5 - calculate similarity using the array from the step 4. In this step
lower and upper indexes of the second array from the step 1 are used. An
upper index is moved in each iteration of the calculation. And a lower
index is moved if current similarity is bigger than a maximum similarity
calculated in previous iterations. In a result lower and upper indexes
point to a substring that has a maxumim similarity value.
Changes
-------
Version was increased to 1.3.
Added some functions into trgm_op.c to calculate substring similarity.
Made some fixes into trgm_gin.c in gin_extract_query_trgm,
gin_trgm_consistent and gin_trgm_triconsistent functions to add GIN
index supporing for <% operator.
Made some fixes into trgm_gist.c in gtrgm_consistent and gtrgm_distance
functions to add GIST index support for <% operator.
Added pg_substring_trgm test.
Tests
-----
I have done tests to show performance of the new operator. Tests have
been done using a table that contains 10254520 records. This table
contains texts that have trigram count between 2 and 121. 214 queries
were done to this table using GIN and GIST indexes and same queries were
done without indexes.
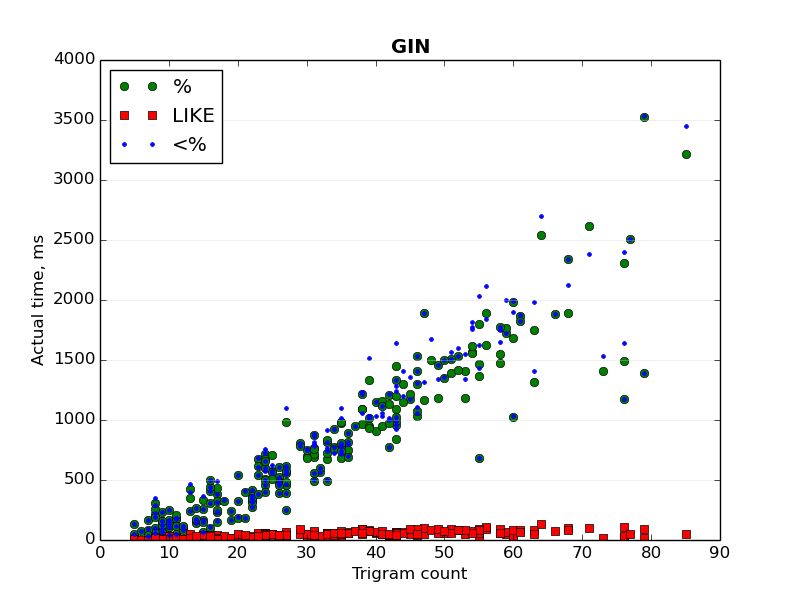
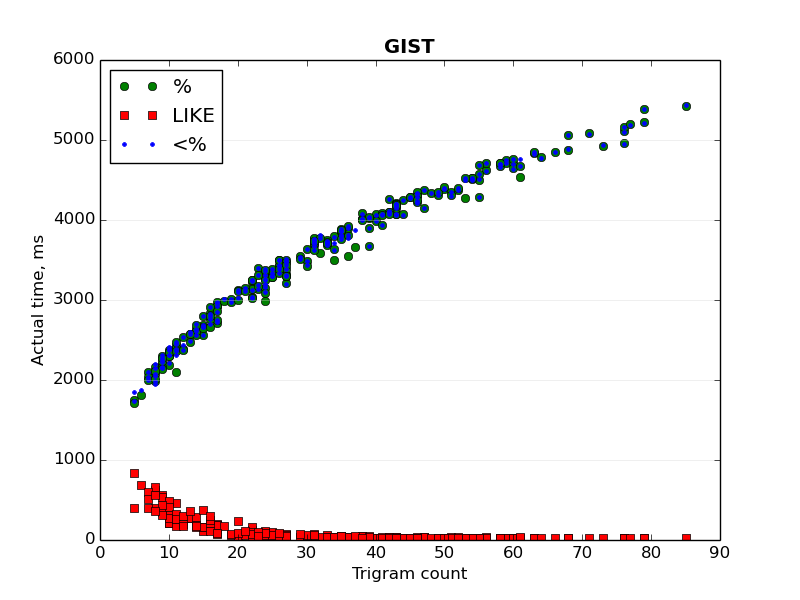
Two graphs ("GIN - index time.png" and "GIST - index time.png") show the
dependence of the actual time of bitmap index scan from the trigram
count of a searched text.
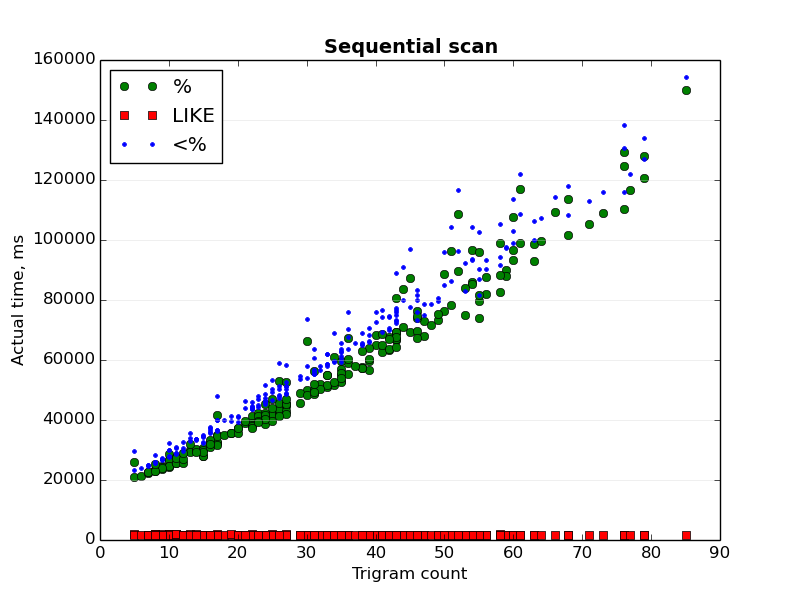
Third graph (Sequential scan.png) shows the dependence of the actual
time of sequential scan from the trigram count of a searched text.
Until now I have not done tests to show performance of the search in
large texts. I can do it if it is interesting.
Alexander Korotkov <a(dot)korotkov(at)postgrespro(dot)ru> is co-author
of the patch. Thank you for review and for help.
--
Artur Zakirov
Postgres Professional: http://www.postgrespro.com
Russian Postgres Company
| Attachment | Content-Type | Size |
|---|---|---|
|
image/png | 45.8 KB |
|
image/png | 41.8 KB |
|
image/png | 49.0 KB |
| substring_similarity.patch | text/x-patch | 40.6 KB |
| substring_similarity_tests.patch | text/x-patch | 151.7 KB |
Responses
- Re: Fuzzy substring searching with the pg_trgm extension at 2015-12-18 19:53:38 from Artur Zakirov
- Re: Fuzzy substring searching with the pg_trgm extension at 2015-12-27 05:12:05 from Jeff Janes
- Re: Fuzzy substring searching with the pg_trgm extension at 2016-01-15 21:07:39 from Jeff Janes
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Artur Zakirov | 2015-12-18 19:53:38 | Re: Fuzzy substring searching with the pg_trgm extension |
| Previous Message | Peter Geoghegan | 2015-12-18 19:22:02 | Re: Re: Reusing abbreviated keys during second pass of ordered [set] aggregates |