WIP: bloom filter in Hash Joins with batches
| From: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> |
|---|---|
| To: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | WIP: bloom filter in Hash Joins with batches |
| Date: | 2015-12-15 22:30:06 |
| Message-ID: | 5670946E.8070705@2ndquadrant.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
Hi,
while working on the Hash Join improvements, I've been repeatedly
running into the idea of bloom filter - various papers on hash joins
mention bloom filters as a way to optimize access to the hash table by
doing fewer lookups, etc.
Sadly, I've been unable to actually see any real benefit of using a
bloom filter, which I believe is mostly due to NTUP_PER_BUCKET=1, which
makes the lookups much more efficient (so the room for bloom filter
improvements is narrow).
The one case where bloom filter might still help, and that's when the
bloom filter fits into L3 cache (a few MBs) while the hash table (or
more accurately the buckets) do not. Then there's a chance that the
bloom filter (which needs to do multiple lookups) might help.
But I think there's another case where bloom filter might be way more
useful in Hash Join - when we do batching. What we do currently is that
we simply
1) build the batches for the hash table (inner relation)
2) read the outer relation (usually the larger one), and split it
into batches just like the hash table
3) while doing (2) we join the first batch, and write the remaining
batches to disk (temporary files)
4) we read the batches one by one (for both tables) and do the join
Now, imagine that only some of the rows in the outer table actually
match a row in the hash table. Currently, we do write those rows into
the temporary file, but with a bloom filter on the whole hash table (all
the batches at once) we can skip that for some types of joins.
For inner join we can immediately discard the outer row, for left join
we can immediately output the row. In both cases we can completely
eliminate the overhead with writing the tuple to the temporary file and
then reading it again.
The attached patch is a PoC of this approach - I'm pretty sure it's not
perfectly correct (e.g. I only tried it with inner join), but it's good
enough for demonstrating the benefits. It's rather incomplete (see the
end of this e-mail), and I'm mostly soliciting some early feedback at
this point.
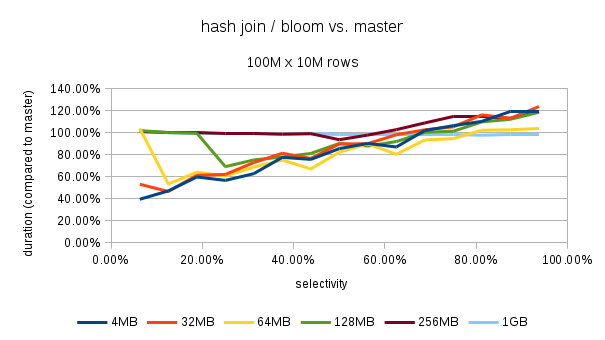
The numbers presented here are for a test case like this:
CREATE TABLE dim (id INT, dval TEXT);
CREATE TABLE fact (id INT, fval TEXT);
INSERT INTO dim SELECT i, md5(i::text)
FROM generate_series(1,10000000) s(i);
-- repeat 10x
INSERT INTO fact SELECT * FROM dim;
and a query like this
SELECT COUNT(fval) FROM fact JOIN dim USING (id) WHERE dval < 'a';
with different values in the WHERE condition to select a fraction of the
inner 'dim' table - this directly affects what portion of the 'fact'
table has a matching row, and also the size of the hash table (and
number of batches).
Now, some numbers from a machine with 8GB of RAM (the 'fact' table has
~6.5GB of data, so there's actually quite a bit of memory pressure,
forcing the temp files to disk etc.).
With work_mem=16MB, it looks like this:
batches filter select. bloom master bloom/master
-----------------------------------------------------------
4 1 6.25% 23871 48631 49.09%
8 2 12.50% 25752 56692 45.42%
8 3 18.75% 31273 57455 54.43%
16 4 25.01% 37430 62325 60.06%
16 5 31.25% 39005 61143 63.79%
16 6 37.50% 46157 63533 72.65%
16 7 43.75% 53500 65483 81.70%
32 8 49.99% 53952 65730 82.08%
32 9 56.23% 55187 67521 81.73%
32 a 62.49% 64454 69448 92.81%
32 b 68.73% 66937 71692 93.37%
32 c 74.97% 73323 72060 101.75%
32 d 81.23% 76703 73513 104.34%
32 e 87.48% 81970 74890 109.45%
32 f 93.74% 86102 76257 112.91%
The 'batches' means how many batches were used for the join, 'filter' is
the value used in the WHERE condition, selectivity is the fraction of
the 'dim' table that matches the condition (and also the 'fact'). Bloom
and master are timings of the query in miliseconds, and bloom/master is
comparison of the runtimes - so for example 49% means the hash join with
bloom filter was running ~2x as fast.
Admittedly, work_mem=16MB is quite low, but that's just a way to force
batching. What really matters is the number of batches and selectivity
(how many tuples we can eliminate using the bloom filter).
For work_mem=64MB it looks like this:
batches filter select. bloom master bloom/master
-----------------------------------------------------------
1 1 6.25% 24846 23854 104.16%
2 2 12.50% 24369 45672 53.36%
2 3 18.75% 30432 47454 64.13%
4 4 25.01% 36175 59741 60.55%
4 5 31.25% 43103 62631 68.82%
4 6 37.50% 48179 64079 75.19%
So initially it's a bit slower (it's not doing any batching in this
case, but the code is a bit silly and while not building the bloom
filter it still does some checks). But once we start batching, it gets
2x as fast again, and then slowly degrades as the selectivity increases.
Attached is a spreadsheet with results for various work_mem values, and
also with a smaller data set (just 30M rows in the fact table), which
easily fits into memory. Yet it shows similar gains, shaving off ~40% in
the best case, suggesting that this is not just thanks to reduction of
I/O when forcing the temp files to disk.
As I mentioned, the patch is incomplete in several ways:
1) It does not count the bloom filter (which may be quite big) into
work_mem properly.
2) It probably does not work for outer joins at this point.
3) Currently the bloom filter is used whenever we do batching, but it
should really be driven by selectivity too - it'd be good to (a)
estimate the fraction of 'fact' tuples having a match in the hash
table, and not to do bloom if it's over ~60% or so. Also, maybe
the could should count the matches at runtime, and disable the
bloom filter if we reach some threshold.
But overall, this seems like a nice optimization opportunity for hash
joins on large data sets, where batching is necessary.
Ideas?
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
| Attachment | Content-Type | Size |
|---|---|---|
| hashjoin-bloom.sql | application/sql | 398 bytes |
| bloom-hashjoin-v1.patch | text/x-diff | 18.6 KB |
|
image/png | 30.0 KB |
| hashjoin-bloom-results.ods | application/vnd.oasis.opendocument.spreadsheet | 79.3 KB |
Responses
- Re: WIP: bloom filter in Hash Joins with batches at 2015-12-17 09:50:46 from Shulgin, Oleksandr
- Re: WIP: bloom filter in Hash Joins with batches at 2015-12-17 10:44:56 from Simon Riggs
- Re: WIP: bloom filter in Hash Joins with batches at 2015-12-20 04:46:56 from Oleg Bartunov
- Re: WIP: bloom filter in Hash Joins with batches at 2015-12-24 11:43:37 from Aleksander Alekseev
- Re: WIP: bloom filter in Hash Joins with batches at 2015-12-31 20:38:35 from Tomas Vondra
- Re: WIP: bloom filter in Hash Joins with batches at 2016-02-08 20:02:36 from Alvaro Herrera
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Robert Haas | 2015-12-15 23:24:50 | Re: [PoC] Asynchronous execution again (which is not parallel) |
| Previous Message | Tomas Vondra | 2015-12-15 21:19:21 | Re: pg_hba_lookup function to get all matching pg_hba.conf entries |