Re: BufferAlloc: don't take two simultaneous locks
| From: | Yura Sokolov <y(dot)sokolov(at)postgrespro(dot)ru> |
|---|---|
| To: | Kyotaro Horiguchi <horikyota(dot)ntt(at)gmail(dot)com> |
| Cc: | pgsql-hackers(at)lists(dot)postgresql(dot)org, michail(dot)nikolaev(at)gmail(dot)com, x4mmm(at)yandex-team(dot)ru, andres(at)anarazel(dot)de, simon(dot)riggs(at)enterprisedb(dot)com |
| Subject: | Re: BufferAlloc: don't take two simultaneous locks |
| Date: | 2022-04-06 13:17:28 |
| Message-ID: | 4b4c81ecddd56fa974124c4e6da2f54aed3ddbf2.camel@postgrespro.ru |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
Good day, Kyotaoro-san.
Good day, hackers.
В Вс, 20/03/2022 в 12:38 +0300, Yura Sokolov пишет:
> В Чт, 17/03/2022 в 12:02 +0900, Kyotaro Horiguchi пишет:
> > At Wed, 16 Mar 2022 14:11:58 +0300, Yura Sokolov <y(dot)sokolov(at)postgrespro(dot)ru> wrote in
> > > В Ср, 16/03/2022 в 12:07 +0900, Kyotaro Horiguchi пишет:
> > > > At Tue, 15 Mar 2022 13:47:17 +0300, Yura Sokolov <y(dot)sokolov(at)postgrespro(dot)ru> wrote in
> > > > In v7, HASH_ENTER returns the element stored in DynaHashReuse using
> > > > the freelist_idx of the new key. v8 uses that of the old key (at the
> > > > time of HASH_REUSE). So in the case "REUSE->ENTER(elem exists and
> > > > returns the stashed)" case the stashed element is returned to its
> > > > original partition. But it is not what I mentioned.
> > > >
> > > > On the other hand, once the stahsed element is reused by HASH_ENTER,
> > > > it gives the same resulting state with HASH_REMOVE->HASH_ENTER(borrow
> > > > from old partition) case. I suspect that ththat the frequent freelist
> > > > starvation comes from the latter case.
> > >
> > > Doubtfully. Due to probabilty theory, single partition doubdfully
> > > will be too overflowed. Therefore, freelist.
> >
> > Yeah. I think so generally.
> >
> > > But! With 128kb shared buffers there is just 32 buffers. 32 entry for
> > > 32 freelist partition - certainly some freelist partition will certainly
> > > have 0 entry even if all entries are in freelists.
> >
> > Anyway, it's an extreme condition and the starvation happens only at a
> > neglegible ratio.
> >
> > > > RETURNED: 2
> > > > ALLOCED: 0
> > > > BORROWED: 435
> > > > REUSED: 495444
> > > > ASSIGNED: 495467 (-23)
> > > >
> > > > Now "BORROWED" happens 0.8% of REUSED
> > >
> > > 0.08% actually :)
> >
> > Mmm. Doesn't matter:p
> >
> > > > > > > I lost access to Xeon 8354H, so returned to old Xeon X5675.
> > > > > > ...
> > > > > > > Strange thing: both master and patched version has higher
> > > > > > > peak tps at X5676 at medium connections (17 or 27 clients)
> > > > > > > than in first october version [1]. But lower tps at higher
> > > > > > > connections number (>= 191 clients).
> > > > > > > I'll try to bisect on master this unfortunate change.
> > ...
> > > I've checked. Looks like something had changed on the server, since
> > > old master commit behaves now same to new one (and differently to
> > > how it behaved in October).
> > > I remember maintainance downtime of the server in november/december.
> > > Probably, kernel were upgraded or some system settings were changed.
> >
> > One thing I have a little concern is that numbers shows 1-2% of
> > degradation steadily for connection numbers < 17.
> >
> > I think there are two possible cause of the degradation.
> >
> > 1. Additional branch by consolidating HASH_ASSIGN into HASH_ENTER.
> > This might cause degradation for memory-contended use.
> >
> > 2. nallocs operation might cause degradation on non-shared dynahasyes?
> > I believe doesn't but I'm not sure.
> >
> > On a simple benchmarking with pgbench on a laptop, dynahash
> > allocation (including shared and non-shared) happend about at 50
> > times per second with 10 processes and 200 with 100 processes.
> >
> > > > I don't think nalloced needs to be the same width to long. For the
> > > > platforms with 32-bit long, anyway the possible degradation if any by
> > > > 64-bit atomic there doesn't matter. So don't we always define the
> > > > atomic as 64bit and use the pg_atomic_* functions directly?
> > >
> > > Some 32bit platforms has no native 64bit atomics. Then they are
> > > emulated with locks.
> > >
> > > Well, and for 32bit platform long is just enough. Why spend other
> > > 4 bytes per each dynahash?
> >
> > I don't think additional bytes doesn't matter, but emulated atomic
> > operations can matter. However I'm not sure which platform uses that
> > fallback implementations. (x86 seems to have __sync_fetch_and_add()
> > since P4).
> >
> > My opinion in the previous mail is that if that level of degradation
> > caued by emulated atomic operations matters, we shouldn't use atomic
> > there at all since atomic operations on the modern platforms are not
> > also free.
> >
> > In relation to 2 above, if we observe that the degradation disappears
> > by (tentatively) use non-atomic operations for nalloced, we should go
> > back to the previous per-freelist nalloced.
>
> Here is version with nalloced being union of appropriate atomic and
> long.
>
Ok, I got access to stronger server, did the benchmark, found weird
things, and so here is new version :-)
First I found if table size is strictly limited to NBuffers and FIXED,
then under high concurrency get_hash_entry may not find free entry
despite it must be there. It seems while process scans free lists, other
concurrent processes "moves entry around", ie one concurrent process
fetched it from one free list, other process put new entry in other
freelist, and unfortunate process missed it since it tests freelists
only once.
Second, I confirm there is problem with freelist spreading.
If I keep entry's freelist_idx, then one freelist is crowded.
If I use new entry's freelist_idx, then one freelist is emptified
constantly.
Third, I found increased concurrency could harm. When popular block is
evicted for some reason, then thundering herd effect occures: many
backends wants to read same block, they evict many other buffers, but
only one is inserted. Other goes to freelist. Evicted buffers by itself
reduce cache hit ratio and provocates more work. Old version resists
this effect by not removing old buffer before new entry is successfully
inserted.
To fix this issues I made following:
# Concurrency
First, I limit concurrency by introducing other lwlocks tranche -
BufferEvict. It is 8 times larger than BufferMapping tranche (1024 vs
128).
If backend doesn't find buffer in buffer table and wants to introduce
it, it first calls
LWLockAcquireOrWait(newEvictPartitionLock, LW_EXCLUSIVE)
If lock were acquired, then it goes to eviction and replace process.
Otherwise, it waits lock to be released and repeats search.
This greately improve performance for > 400 clients in pgbench.
I tried other variant as well:
- first insert entry with dummy buffer index into buffer table.
- if such entry were already here, then wait it to be filled.
- otherwise find victim buffer and replace dummy index with new one.
Wait were done with shared lock on EvictPartitionLock as well.
This variant performed quite same.
Logically I like that variant more, but there is one gotcha:
FlushBuffer could fail with elog(ERROR). Therefore then there is
a need to reliable remove entry with dummy index.
And after all, I still need to hold EvictPartitionLock to notice
waiters.
I've tried to use ConditionalVariable, but its performance were much
worse.
# Dynahash capacity and freelists.
I returned back buffer table initialization:
- removed FIXES_SIZE restriction introduced in previous version
- returned `NBuffers + NUM_BUFFER_PARTITIONS`.
I really think, there should be more spare items, since almost always
entry_alloc is called at least once (on 128MB shared_buffers). But
let keep it as is for now.
`get_hash_entry` were changed to probe NUM_FREELISTS/4 (==8) freelists
before falling back to `entry_alloc`, and probing is changed from
linear to quadratic. This greately reduces number of calls to
`entry_alloc`, so more shared memory left intact. And I didn't notice
large performance hit from. Probably there is some, but I think it is
adequate trade-off.
`free_reused_entry` now returns entry to random position. It flattens
free entry's spread. Although it is not enough without other changes
(thundering herd mitigation and probing more lists in get_hash_entry).
# Benchmarks
Benchmarked on two socket Xeon(R) Gold 5220 CPU @2.20GHz
18 cores per socket + hyper-threading - upto 72 virtual core total.
turbo-boost disabled
Linux 5.10.103-1 Debian.
pgbench scale 100 simple_select + simple select with 3 keys (sql file
attached).
shared buffers 128MB & 1GB
huge_pages=on
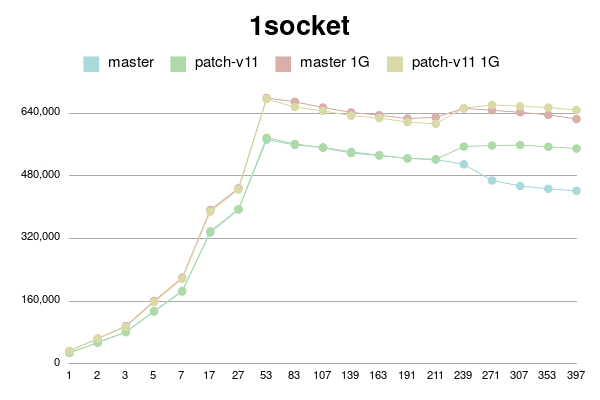
1 socket
conns | master | patch-v11 | master 1G | patch-v11 1G
--------+------------+------------+------------+------------
1 | 27882 | 27738 | 32735 | 32439
2 | 54082 | 54336 | 64387 | 63846
3 | 80724 | 81079 | 96387 | 94439
5 | 134404 | 133429 | 160085 | 157399
7 | 185977 | 184502 | 219916 | 217142
17 | 335345 | 338214 | 393112 | 388796
27 | 393686 | 394948 | 447945 | 444915
53 | 572234 | 577092 | 678884 | 676493
83 | 558875 | 561689 | 669212 | 655697
107 | 553054 | 551896 | 654550 | 646010
139 | 541263 | 538354 | 641937 | 633840
163 | 532932 | 531829 | 635127 | 627600
191 | 524647 | 524442 | 626228 | 617347
211 | 521624 | 522197 | 629740 | 613143
239 | 509448 | 554894 | 652353 | 652972
271 | 468190 | 557467 | 647403 | 661348
307 | 454139 | 558694 | 642229 | 657649
353 | 446853 | 554301 | 635991 | 654571
397 | 441909 | 549822 | 625194 | 647973
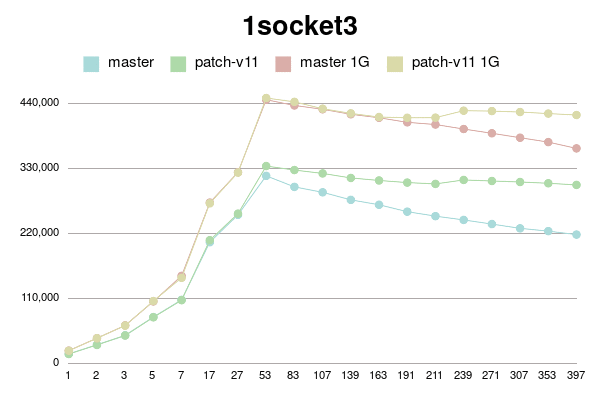
1 socket 3 keys
conns | master | patch-v11 | master 1G | patch-v11 1G
--------+------------+------------+------------+------------
1 | 16677 | 16477 | 22219 | 22030
2 | 32056 | 31874 | 43298 | 43153
3 | 48091 | 47766 | 64877 | 64600
5 | 78999 | 78609 | 105433 | 106101
7 | 108122 | 107529 | 148713 | 145343
17 | 205656 | 209010 | 272676 | 271449
27 | 252015 | 254000 | 323983 | 323499
53 | 317928 | 334493 | 446740 | 449641
83 | 299234 | 327738 | 437035 | 443113
107 | 290089 | 322025 | 430535 | 431530
139 | 277294 | 314384 | 422076 | 423606
163 | 269029 | 310114 | 416229 | 417412
191 | 257315 | 306530 | 408487 | 416170
211 | 249743 | 304278 | 404766 | 416393
239 | 243333 | 310974 | 397139 | 428167
271 | 236356 | 309215 | 389972 | 427498
307 | 229094 | 307519 | 382444 | 425891
353 | 224385 | 305366 | 375020 | 423284
397 | 218549 | 302577 | 364373 | 420846
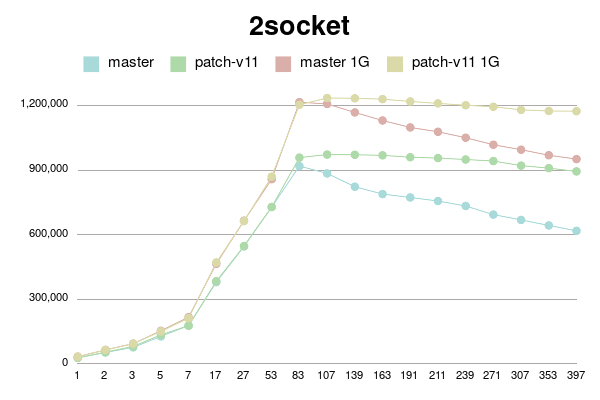
2 sockets
conns | master | patch-v11 | master 1G | patch-v11 1G
--------+------------+------------+------------+------------
1 | 27287 | 27631 | 32943 | 32493
2 | 52397 | 54011 | 64572 | 63596
3 | 76157 | 80473 | 93363 | 93528
5 | 127075 | 134310 | 153176 | 149984
7 | 177100 | 176939 | 216356 | 211599
17 | 379047 | 383179 | 464249 | 470351
27 | 545219 | 546706 | 664779 | 662488
53 | 728142 | 728123 | 857454 | 869407
83 | 918276 | 957722 | 1215252 | 1203443
107 | 884112 | 971797 | 1206930 | 1234606
139 | 822564 | 970920 | 1167518 | 1233230
163 | 788287 | 968248 | 1130021 | 1229250
191 | 772406 | 959344 | 1097842 | 1218541
211 | 756085 | 955563 | 1077747 | 1209489
239 | 732926 | 948855 | 1050096 | 1200878
271 | 692999 | 941722 | 1017489 | 1194012
307 | 668241 | 920478 | 994420 | 1179507
353 | 642478 | 908645 | 968648 | 1174265
397 | 617673 | 893568 | 950736 | 1173411
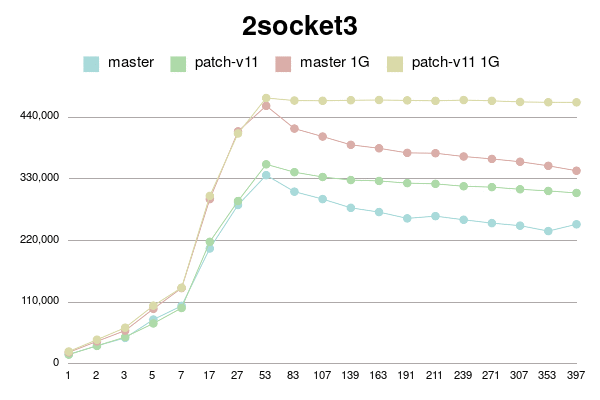
2 sockets 3 keys
conns | master | patch-v11 | master 1G | patch-v11 1G
--------+------------+------------+------------+------------
1 | 16722 | 16393 | 20340 | 21813
2 | 32057 | 32009 | 39993 | 42959
3 | 46202 | 47678 | 59216 | 64374
5 | 78882 | 72002 | 98054 | 103731
7 | 103398 | 99538 | 135098 | 135828
17 | 205863 | 217781 | 293958 | 299690
27 | 283526 | 290539 | 414968 | 411219
53 | 336717 | 356130 | 460596 | 474563
83 | 307310 | 342125 | 419941 | 469989
107 | 294059 | 333494 | 405706 | 469593
139 | 278453 | 328031 | 390984 | 470553
163 | 270833 | 326457 | 384747 | 470977
191 | 259591 | 322590 | 376582 | 470335
211 | 263584 | 321263 | 375969 | 469443
239 | 257135 | 316959 | 370108 | 470904
271 | 251107 | 315393 | 365794 | 469517
307 | 246605 | 311585 | 360742 | 467566
353 | 236899 | 308581 | 353464 | 466936
397 | 249036 | 305042 | 344673 | 466842
I skipped v10 since I used it internally for variant
"insert entry with dummy index then search victim".
------
regards
Yura Sokolov
y(dot)sokolov(at)postgrespro(dot)ru
funny(dot)falcon(at)gmail(dot)com
| Attachment | Content-Type | Size |
|---|---|---|
| v11-bufmgr-lock-improvements.patch | text/x-patch | 39.9 KB |
|
image/gif | 12.1 KB |
|
image/gif | 12.3 KB |
|
image/gif | 12.2 KB |
|
image/gif | 12.9 KB |
| simple_select3.sql | application/sql | 235 bytes |
In response to
- Re: BufferAlloc: don't take two simultaneous locks at 2022-03-20 09:38:06 from Yura Sokolov
Responses
- Re: BufferAlloc: don't take two simultaneous locks at 2022-04-07 07:55:16 from Kyotaro Horiguchi
- Re: BufferAlloc: don't take two simultaneous locks at 2022-04-14 13:46:03 from Robert Haas
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Andrew Dunstan | 2022-04-06 13:20:54 | Re: SQL/JSON: JSON_TABLE |
| Previous Message | Peter Eisentraut | 2022-04-06 13:07:48 | logical replication of identity sequences |