Re: Initial 9.2 pgbench write results
| From: | Greg Smith <greg(at)2ndQuadrant(dot)com> |
|---|---|
| To: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Re: Initial 9.2 pgbench write results |
| Date: | 2012-02-23 11:17:32 |
| Message-ID: | 4F46204C.1000501@2ndQuadrant.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
I've updated http://highperfpostgres.com/results-write-9.2-cf4/index.htm
with more data including two alternate background writer configurations.
Since the sensitive part of the original results was scales of 500 and
1000, I've also gone back and added scale=750 runs to all results.
Quick summary is that I'm not worried about 9.2 performance now, I'm
increasingly confident that the earlier problems I reported on are just
bad interactions between the reinvigorated background writer and
workloads that are tough to write to disk. I'm satisfied I understand
these test results well enough to start evaluating the pending 9.2
changes in the CF queue I wanted to benchmark.
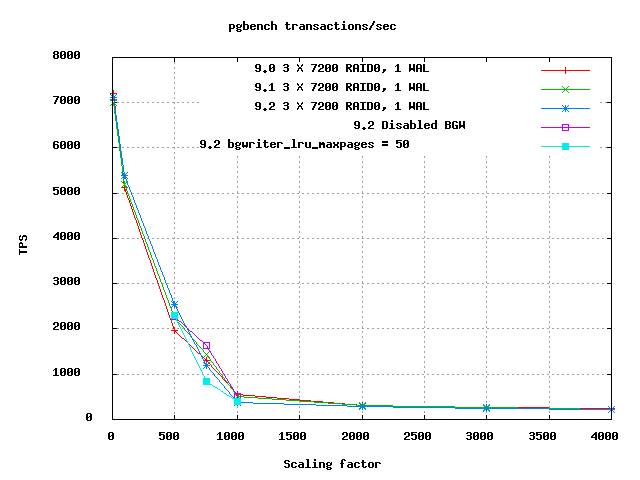
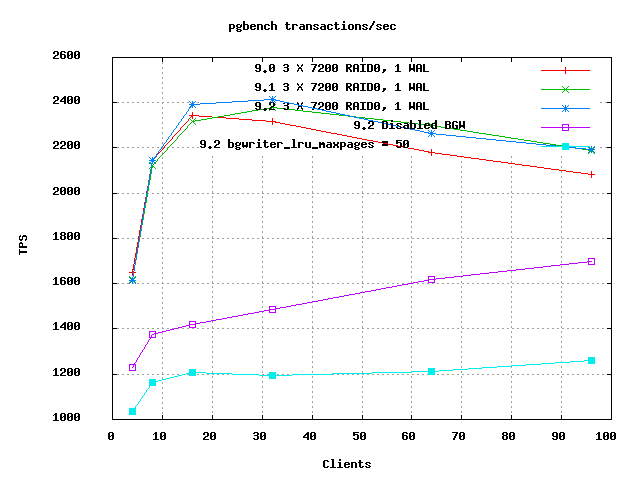
Attached are now useful client and scale graphs. All of 9.0, 9.1, and
9.2 have been run now with exactly the same scales and clients loads, so
the graphs of all three versions can be compared. The two 9.2
variations with alternate parameters were only run at some scales, which
means you can't compare them usefully on the clients graph; only on the
scaling one. They are very obviously in a whole different range of that
graph, just ignore the two that are way below the rest.
Here's a repeat of the interesting parts of the data set with new
points. Here "9.2N" is without no background writer, while "9.2H" has a
background writer set to half strength: bgwriter_lru_maxpages = 50 I
picked one middle client level out of the result=750 results just to
focus better, relative results are not sensitive to that:
scale=500, db is 46% of RAM
Version Avg TPS
9.0 1961
9.1 2255
9.2 2525
9.2N 2267
9.2H 2300
scale=750, db is 69% of RAM; clients=16
Version Avg TPS
9.0 1298
9.1 1387
9.2 1477
9.2N 1489
9.2H 943
scale=1000, db is 94% of RAM; clients=4
Version TPS
9.0 535
9.1 491 (-8.4% relative to 9.0)
9.2 338 (-31.2% relative to 9.1)
9.2N 516
9.2H 400
The fact that almost all the performance regression against 9.2 goes
away if the background writer is disabled is an interesting point. That
results actually get worse at scale=500 without the background writer is
another. That pair of observations makes me feel better that there's a
tuning trade-off here being implicitly made by having a more active
background writer in 9.2; it helps on some cases, hurts others. That I
can deal with. Everything lines up perfectly at scale=500: if I
reorder on TPS:
scale=500, db is 46% of RAM
Version Avg TPS
9.2 2525
9.2H 2300
9.2N 2267
9.1 2255
9.0 1961
That makes you want to say "the more background writer the better", right?
The new scale=750 numbers are weird though, and they keep this from
being so clear. I ran the parts that were most weird twice just because
they seemed so odd, and it was repeatable. Just like scale=500, with
scale=750 the 9.2/no background writer has the best performance of any
run. But the half-intensity one has the worst! It would be nice if it
fell between the 9.2 and 9.2N results, instead it's at the other edge.
The only lesson I can think to draw here is that once we're in the area
where performance is dominated by the trivia around exactly how writes
are scheduled, the optimal ordering of writes is just too complicated to
model that easily. The rest of this is all speculation on how to fit
some ideas to this data.
Going back to 8.3 development, one of the design trade-offs I was very
concerned about was not wasting resources by having the BGW run too
often. Even then it was clear that for these simple pgbench tests,
there were situations where letting backends do their own writes was
better than speculative writes from the background writer. The BGW
constantly risks writing a page that will be re-dirtied before it goes
to disk. That can't be too common though in the current design, since
it avoids things with high usage counts. (The original BGW wrote things
that were used recently, and that was a measurable problem by 8.3)
I think an even bigger factor now is that the BGW writes can disturb
write ordering/combining done at the kernel and storage levels. It's
painfully obvious now how much PostgreSQL relies on that to get good
performance. All sorts of things break badly if we aren't getting
random writes scheduled to optimize seek times, in as many contexts as
possible. It doesn't seem unreasonable that background writer writes
can introduce some delay into the checkpoint writes, just by adding more
random components to what is already a difficult to handle write/sync
series. That's what I think what these results are showing is that
background writer writes can deoptimize other forms of write.
A second fact that's visible from the TPS graphs over the test run, and
obvious if you think about it, is that BGW writes force data to physical
disk earlier than they otherwise might go there. That's a subtle
pattern in the graphs. I expect that though, given one element to "do I
write this?" in Linux is how old the write is. Wondering about this
really emphasises that I need to either add graphing of vmstat/iostat
data to these graphs or switch to a benchmark that does that already. I
think I've got just enough people using pgbench-tools to justify the
feature even if I plan to use the program less.
I also have a good answer to "why does this only happen at these
scales?" now. At scales below here, the database is so small relative
to RAM that it just all fits all the time. That includes the indexes
being very small, so not many writes generated by their dirty blocks.
At higher scales, the write volume becomes seek bound, and the result is
so low that checkpoints become timeout based. So there are
significantly less of them. At the largest scales and client counts
here, there isn't a single checkpoint actually finished at some of these
10 minute long runs. One doesn't even start until 5 minutes have gone
by, and the checkpoint writes are so slow they take longer than 5
minutes to trickle out and sync, with all the competing I/O from
backends mixed in. Note that the "clients-sets" graph still shows a
strong jump from 9.0 to 9.1 at high client counts; I'm pretty sure
that's the fsync compaction at work.
--
Greg Smith 2ndQuadrant US greg(at)2ndQuadrant(dot)com Baltimore, MD
PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
| Attachment | Content-Type | Size |
|---|---|---|
|
image/png | 5.6 KB |
|
image/png | 6.0 KB |
In response to
- Initial 9.2 pgbench write results at 2012-02-14 18:45:52 from Greg Smith
Responses
- Re: Initial 9.2 pgbench write results at 2012-02-23 12:36:15 from Simon Riggs
- Re: Initial 9.2 pgbench write results at 2012-02-28 16:36:41 from Jeff Janes
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Hitoshi Harada | 2012-02-23 11:35:53 | Re: Finer Extension dependencies |
| Previous Message | Kohei KaiGai | 2012-02-23 11:17:14 | Re: [v9.2] Add GUC sepgsql.client_label |