Re: Free Space Map data structure
| From: | Heikki Linnakangas <heikki(at)enterprisedb(dot)com> |
|---|---|
| To: | Hannu Krosing <hannu(at)krosing(dot)net> |
| Cc: | PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Free Space Map data structure |
| Date: | 2008-04-11 08:07:32 |
| Message-ID: | 47FF1C44.2070301@enterprisedb.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
Hannu Krosing wrote:
>> BTW, I'm pretty sure I have figured out the method for storing minimal
>> required binary tree as an array, where adding each page adds exactly
>> one upper node. The node added is often not the immediate parent, but is
>> always the one needed for covering all nodes.
>>
>> I just have to write it up in an understandable way and then you all can
>> look at it and tell if it is something well-known from Knuth or Date ;)
>
> Find sample code attached:
>
> not optimal at all, meant as proof-of-concept.
>
> just run the file to see how it works, some comments in the beginning.
>
> currently it interleaves leaf and internal nodes, but it may be better
> for some uses (like seqscanning leaf nodes when searching for clustered
> pos) to separate them, for example having 1st 4k for lef nodes and 2nd
> for internal nodes.
>
> also, I think that having a fan-out factor above 2 (making it more like
> b-tree instead of binary tree) would be more efficient due to CPU
> caches, but it takes some more work to figure it out.
At least it would be more storage efficient, as you wouldn't need as
many non-leaf nodes. You would need more comparisons when traversing or
updating the tree, but as you pointed out that might be very cheap
because of cache effects.
Within a page, the traditional array representation, where root is at
position 0, it's children are at 1, 2 and so forth, is actually OK. When
the depth of the tree changes, you'll need to memcpy data around and
rebuild parent nodes, but that's acceptable. Or we can fix the depth of
the tree to the max. that fits on a page, and fill it with zeros when
it's not full; all but the rightmost pages are always full anyway.
Scaling into multiple pages, we don't want to move nodes across page
boundaries when extending the relation, so we do need something like
your scheme for that. Taking the upper nodes into account, one FSM page
can hold free space information of ~4k heap (or lower level FSM) pages.
IOW, we have a fan out of 4k across pages. With a fanout like that, we
only need 3-4 levels to address over 500 TB of data.
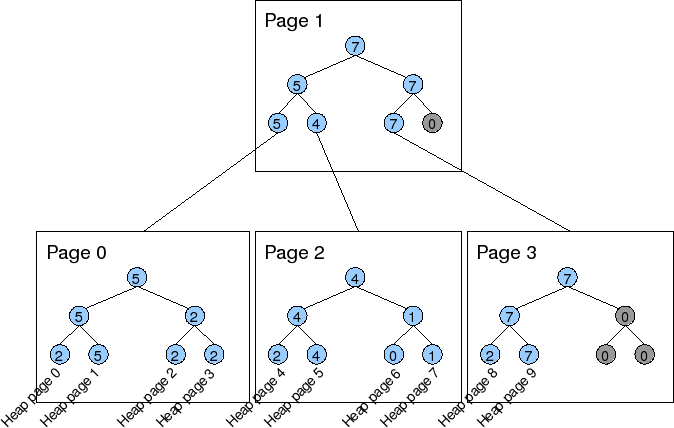
I've attached a diagram illustrating what I have in mind. In the
diagram, each page can hold only 7 nodes, but in reality that would be ~
BLCKSZ/2, or the 4k with default block size. The heap consists of 10
pages, the bottom leaf nodes correspond the heap pages. The leaf nodes
of the upper FSM page store the max the lower FSM pages; they should
match the top nodes of the lower FSM pages. The rightmost nodes in the
tree, colored grey, are unused.
I'm pretty happy with this structure. The concurrency seems reasonably
good, though will need to figure out how exactly the locking should work.
--
Heikki Linnakangas
EnterpriseDB http://www.enterprisedb.com
| Attachment | Content-Type | Size |
|---|---|---|
|
image/png | 17.6 KB |
In response to
- Re: Free Space Map data structure at 2008-04-10 20:04:45 from Hannu Krosing
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Tom Dunstan | 2008-04-11 08:56:53 | Re: Commit fest queue |
| Previous Message | Magnus Hagander | 2008-04-11 08:02:47 | Re: Commit fest queue |