Fix performance degradation of contended LWLock on NUMA
| From: | Sokolov Yura <funny(dot)falcon(at)postgrespro(dot)ru> |
|---|---|
| To: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | Fix performance degradation of contended LWLock on NUMA |
| Date: | 2017-06-05 13:22:58 |
| Message-ID: | 2968c0be065baab8865c4c95de3f435c@postgrespro.ru |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
Good day, everyone.
This patch improves performance of contended LWLock.
It was tested on 4 socket 72 core x86 server (144 HT) Centos 7.1
gcc 4.8.5
Results:
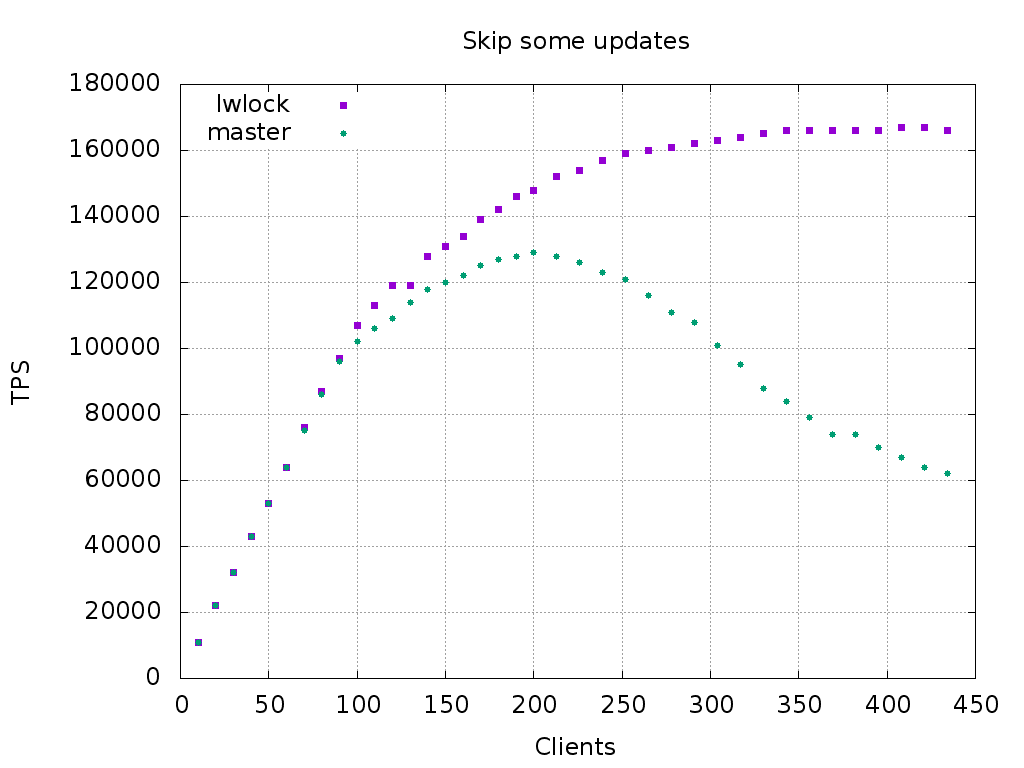
pgbench -i -s 300 + pgbench --skip-some-updates
Clients | master | patched
========+=========+=======
30 | 32k | 32k
50 | 53k | 53k
100 | 102k | 107k
150 | 120k | 131k
200 | 129k | 148k
252 | 121k | 159k
304 | 101k | 163k
356 | 79k | 166k
395 | 70k | 166k
434 | 62k | 166k
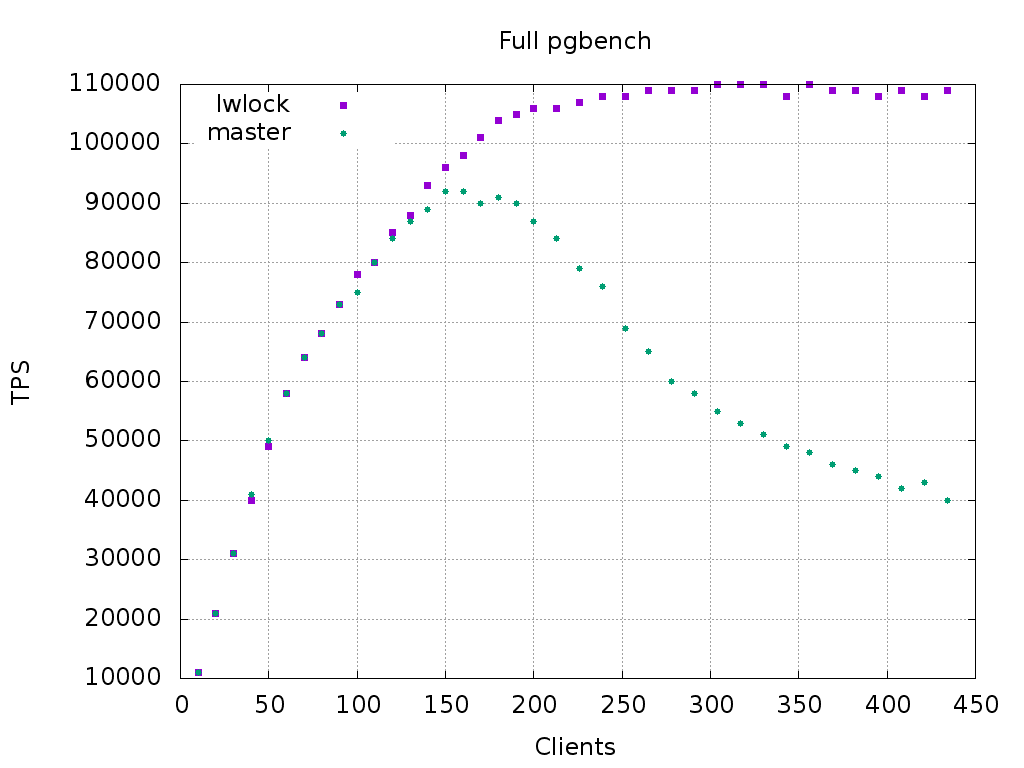
pgbench -i -s 900 + pgbench
Clients | master | patched
========+=========+=======
30 | 31k | 31k
50 | 50k | 49k
100 | 75k | 78k
150 | 92k | 96k
200 | 87k | 106k
252 | 69k | 108k
304 | 55k | 110k
356 | 48k | 110k
395 | 44k | 108k
434 | 40k | 109k
I could not claim read-only benchmarks are affected in any way: results
are unstable between postgresql restarts and varies in a same interval
for both versions. Although some micro-optimization were made to ensure
this parity.
Since investigations exist on changing shared buffers structure (by
removing LWLock from a buffer hash partition lock [1]), I stopped
attempts to gather more reliable statistic for readonly benchmarks.
[1] Takashi Horikawa "Don't stop the world"
https://www.pgcon.org/2017/schedule/events/1078.en.html
Also, looks like patch doesn't affect single NUMA node performance
significantly.
postgresql.conf is tuned with following parameters:
shared_buffers = 32GB
max_connections = 500
fsync = on
synchronous_commit = on
full_page_writes = off
wal_buffers = 16MB
wal_writer_flush_after = 16MB
commit_delay = 2
max_wal_size = 16GB
Patch changes the way LWLock is acquired.
Before patch, lock is acquired using following procedure:
1. first LWLock->state is checked for ability to take a lock, and CAS
performed (either lock could be acquired or not). And it is retried if
status were changed.
2. if lock is not acquired at first 1, Proc is put into wait list, using
LW_FLAG_LOCKED bit of LWLock->state as a spin-lock for wait list.
In fact, profile shows that LWLockWaitListLock spends a lot of CPU on
contendend LWLock (upto 20%).
Additional CAS loop is inside pg_atomic_fetch_or_u32 for setting
LW_FLAG_HAS_WAITERS. And releasing wait list lock is another CAS loop
on the same LWLock->state.
3. after that state is checked again, because lock could be released
before Proc were queued into wait list.
4. if lock were acquired at step 3, Proc should be dequeued from wait
list (another spin lock and CAS loop). And this operation could be
quite heavy, because whole list should be traversed.
Patch makes lock acquiring in single CAS loop:
1. LWLock->state is read, and ability for lock acquiring is detected.
If there is possibility to take a lock, CAS tried.
If CAS were successful, lock is aquired (same to original version).
2. but if lock is currently held by other backend, we check ability for
taking WaitList lock. If wait list lock is not help by anyone, CAS
perfomed for taking WaitList lock and set LW_FLAG_HAS_WAITERS at once.
If CAS were successful, then LWLock were still held at the moment wait
list lock were held - this proves correctness of new algorithm. And
Proc is queued to wait list then.
3. Otherwise spin_delay is performed, and loop returns to step 1.
So invariant is preserved:
- either we grab the lock,
- or we set HAS_WAITERS while lock were held by someone, and queue self
into wait list.
Algorithm for LWLockWaitForVar is also refactored. New version is:
1. If lock is not held by anyone, it immediately exit.
2. Otherwise it is checked for ability to take WaitList lock, because
variable is protected with it. If so, CAS is performed, and if it is
successful, loop breaked to step 4.
3. Otherwise spin_delay perfomed, and loop returns to step 1.
4. var is checked for change.
If it were changed, we unlock wait list lock and exit.
Note: it could not change in following steps because we are holding
wait list lock.
5. Otherwise CAS on setting necessary flags is performed. If it succeed,
then queue Proc to wait list and exit.
6. If Case failed, then there is possibility for LWLock to be already
released - if so then we should unlock wait list and exit.
7. Otherwise loop returns to step 5.
So invariant is preserved:
- either we found LWLock free,
- or we found changed variable,
- or we set flags and queue self while LWLock were held.
Spin_delay is not performed at step 7, because we should release wait
list lock as soon as possible.
Additionally, taking wait list lock is skipped in both algorithms if
SpinDelayStatus.spins is less than part of spins_per_delay loop
iterations (so, it is initial iterations, and some iterations after
pg_usleep, because SpinDelayStatus.spins is reset after sleep). It
effectively turns LWLock into spinlock on low contended case. It was
made because unpatched behaviour (test-queue-retest-unqueue) is already
looks like cutted spin, and shows on "contended but not much" load
sometimes better performance against patch without "spin". Also, before
adding "spin" top performance of patched were equal to top performance
of unpatched, it just didn't degrade.
(Thanks to Teodor Sigaev for suggestion).
Patch consists of 6 commits:
1. Change LWLockWaitListLock to have function-wide delayStatus instead
of local to atomic_read loop. It is already gives some improvement,
but not too much.
2. Refactor acquiring LWLock.
3. Refactor LWLockWaitForVar. Also, LWLockQueueSelf and
LWLockDeququeSelf are removed because they are not referenced since
this commit.
4. Make LWLock to look more like spin lock.
5. Fix comment about algorithm.
6. Make initialization of SpinDelayStatus lighter, because it is on a
fast path of LWLock.
As I couild understand, main benefit cames from XLogInsertLock,
XLogFlushLock and CLogControlLock. XLogInsertLock became spin-lock on
most cases, and it was remarkable boost to add "spin" behaviour to
LWLockWaitForVar because it is used in checking that xlog already
flushed till desired position. Other locks just stop to degrade on high
load.
Patch conflicts with LWLock optimization for Power processors
https://commitfest.postgresql.org/14/984/
Alexandr Korotkov (my chief) doesn't mind if this patch will be
accepted first, and Power will be readdressed after.
PS.
For SHARED lock `skip_wait_list = spins_per_delay / 2;` . Probably it is
better to set it to more conservative `spins_per_delay / 4`, but I have
no enough evidence in favor of either decision.
Though it is certainly better to have it larger, than
`spins_per_delay / 8` that is set for EXCLUSIVE lock.
With regards,
--
Sokolov Yura aka funny_falcon
Postgres Professional: https://postgrespro.ru
The Russian Postgres Company
| Attachment | Content-Type | Size |
|---|---|---|
|
image/png | 11.8 KB |
|
image/png | 12.1 KB |
| lwlock.patch | text/x-diff | 32.9 KB |
Responses
- Re: Fix performance degradation of contended LWLock on NUMA at 2017-06-06 19:33:48 from Robert Haas
- Re: Fix performance degradation of contended LWLock on NUMA at 2017-07-18 17:20:43 from Sokolov Yura
- Re: Fix performance degradation of contended LWLock on NUMA at 2017-10-18 23:28:01 from Andres Freund
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Tom Lane | 2017-06-05 13:49:24 | Re: make check false success |
| Previous Message | Ashutosh Bapat | 2017-06-05 12:24:08 | Re: Fix a typo in README.dependencies |