Re: client_connection_check_interval default value
| From: | Jeremy Schneider <schneider(at)ardentperf(dot)com> |
|---|---|
| To: | Jacob Champion <jacob(dot)champion(at)enterprisedb(dot)com> |
| Cc: | "pgsql-hackers(at)lists(dot)postgresql(dot)org" <pgsql-hackers(at)lists(dot)postgresql(dot)org>, Marat Buharov <marat(dot)buharov(at)gmail(dot)com>, Greg Sabino Mullane <htamfids(at)gmail(dot)com>, Thomas Munro <thomas(dot)munro(at)gmail(dot)com> |
| Subject: | Re: client_connection_check_interval default value |
| Date: | 2026-02-05 23:04:52 |
| Message-ID: | 20260205150452.00006167@ardentperf.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
One interesting thing to me - it seems like all of the past mail
threads were focused on a situation different from mine. Lots of
discussion about freeing resources like CPU.
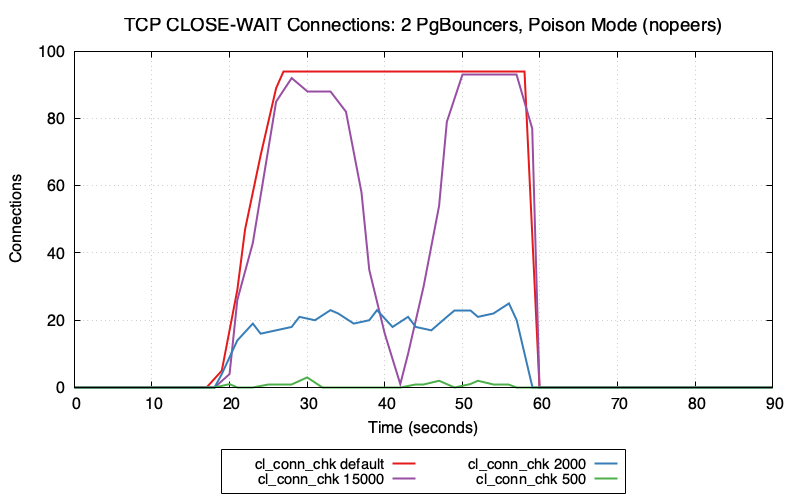
In the outage I saw, the system was idle and we completely ran out of
max_connections because all sessions were waiting on a row lock.
Importantly, the app was closing these conns but we had sockets stacking
up on the server in CLOSE-WAIT state - and postgres simply never
cleaned them up until we had an outage. The processes were completely
idle waiting for a row lock that was not going to be released.
Impact could have been isolated to sessions hitting that row (with this
GUC), but it escalated to a system outage. It's pretty simple to
reproduce this:
https://github.com/ardentperf/pg-idle-test/tree/main/conn_exhaustion
On Thu, 5 Feb 2026 09:26:34 -0800
Jacob Champion <jacob(dot)champion(at)enterprisedb(dot)com> wrote:
> On Wed, Feb 4, 2026 at 9:30 PM Jeremy Schneider
> <schneider(at)ardentperf(dot)com> wrote:
> > While a fix has been merged in pgx for the most direct root cause of
> > the incident I saw, this setting just seems like a good behavior to
> > make Postgres more robust in general.
>
> At the risk of making perfect the enemy of better, the protocol-level
> heartbeat mentioned in the original thread [1] would cover more use
> cases, which might give it a better chance of eventually becoming
> default behavior. It might also be a lot of work, though.
It seems like a fair bit of discussion is around OS coverage - even
Thomas' message there references keepalive working as expected on
Linux. Tom objects in 2023 that "the default behavior would then be
platform-dependent and that's a documentation problem we could do
without."
But it's been five years - has there been further work on implementing
a postgres-level heartbeat? And I see other places in the docs where we
note platform differences, is it really such a big problem to change
the default here?
On Thu, 5 Feb 2026 10:00:29 -0500
Greg Sabino Mullane <htamfids(at)gmail(dot)com> wrote:
> I'm a weak -1 on this. Certainly not 2s! That's a lot of context
> switching for a busy system for no real reason. Also see this past
> discussion:
In the other thread I see larger perf concerns with some early
implementations before they refactored the patch? Konstantin's message
on 2019-08-02 said he didn't see much difference, and the value of the
timeout didn't seem to matter, and if anything the marginal effect was
simply from the presence of any timer (same effect as setting
statement_timeout) - and later on the thread it seems like Thomas also
saw minimal performance concern here.
I did see a real system outage that could have been prevented by an
appropriate default value here, since I didn't yet know to change it.
-Jeremy
| Attachment | Content-Type | Size |
|---|---|---|
|
image/png | 45.7 KB |
In response to
- Re: client_connection_check_interval default value at 2026-02-05 17:26:34 from Jacob Champion
Responses
- Re: client_connection_check_interval default value at 2026-02-05 23:42:42 from Fujii Masao
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Tomas Vondra | 2026-02-05 23:15:27 | Re: Changing the state of data checksums in a running cluster |
| Previous Message | Peter Smith | 2026-02-05 22:58:02 | Re: Warn when creating or enabling a subscription with max_logical_replication_workers = 0 |