Re: WIP: WAL prefetch (another approach)
| From: | Tomas Vondra <tomas(dot)vondra(at)2ndquadrant(dot)com> |
|---|---|
| To: | Thomas Munro <thomas(dot)munro(at)gmail(dot)com> |
| Cc: | Dmitry Dolgov <9erthalion6(at)gmail(dot)com>, David Steele <david(at)pgmasters(dot)net>, Andres Freund <andres(at)anarazel(dot)de>, Alvaro Herrera <alvherre(at)2ndquadrant(dot)com>, pgsql-hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: WIP: WAL prefetch (another approach) |
| Date: | 2020-06-05 15:20:52 |
| Message-ID: | 20200605152052.pe6ql7nxzrpbrit7@development |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
Hi,
I've spent some time testing this, mostly from the performance point of
view. I've done a very simple thing, in order to have reproducible test:
1) I've initialized pgbench with scale 8000 (so ~120GB on a machine with
only 64GB of RAM)
2) created a physical backup, enabled WAL archiving
3) did 1h pgbench run with 32 clients
4) disabled full-page writes and did another 1h pgbench run
Once I had this, I did a recovery using the physical backup and WAL
archive, measuring how long it took to apply each WAL segment. First
without any prefetching (current master), then twice with prefetching.
First with default values (m_io_c=10, distance=256kB) and then with
higher values (100 + 2MB).
I did this on two storage systems I have in the system - NVME SSD and
SATA RAID (3 x 7.2k drives). So, a fast one and slow one.
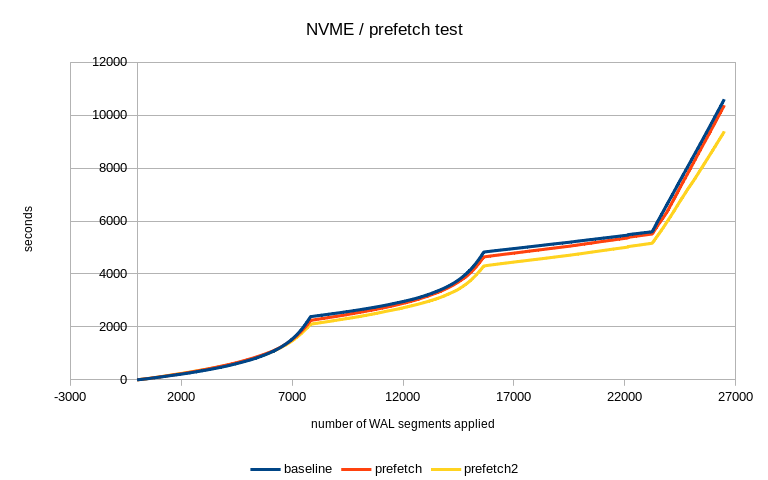
1) NVME
On the NVME, this generates ~26k WAL segments (~400GB), and each of the
pgbench runs generates ~120M transactions (~33k tps). Of course, wast
majority of the WAL segments ~16k comes from the first run, because
there's a lot of FPI due to the random nature of the workload.
I have not expected a significant improvement from the prefetching, as
the NVME is pretty good in handling random I/O. The total duration looks
like this:
no prefetch prefetch prefetch2
10618 10385 9403
So the default is a tiny bit faster, and the more aggressive config
makes it about 10% faster. Not bad, considering the expectations.
Attached is a chart comparing the three runs. There are three clearly
visible parts - first the 1h run with f_p_w=on, with two checkpoints.
That's first ~16k segments. Then there's a bit of a gap before the
second pgbench run was started - I think it's mostly autovacuum etc. And
then at segment ~23k the second pgbench (f_p_w=off) starts.
I think this shows the prefetching starts to help as the number of FPIs
decreases. It's subtle, but it's there.
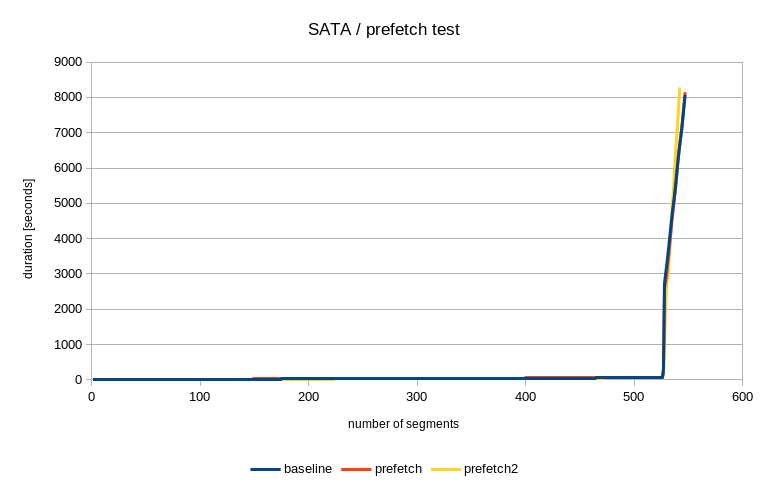
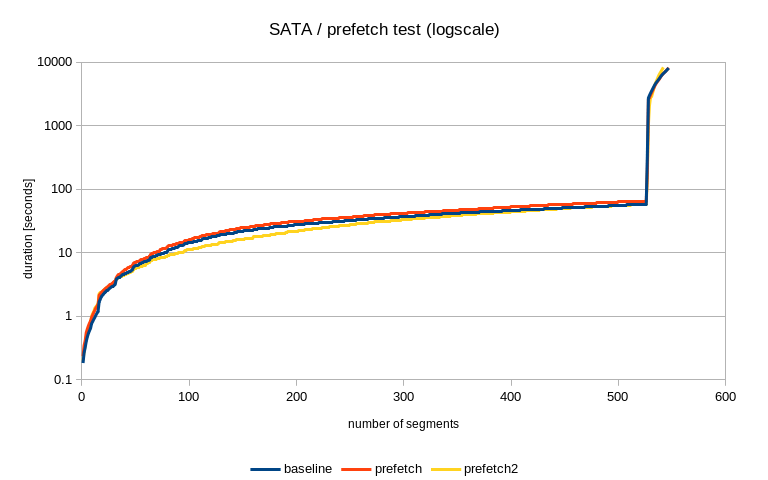
2) SATA
On SATA it's just ~550 segments (~8.5GB), and the pgbench runs generate
only about 1M transactions. Again, vast majority of the segments comes
from the first run, due to FPI.
In this case, I don't have complete results, but after processing 542
segments (out of the ~550) it looks like this:
no prefetch prefetch prefetch2
6644 6635 8282
So the no prefetch and "default" prefetch are roughly on par, but the
"aggressive" prefetch is way slower. I'll get back to this shortly, but
I'd like to point out this is entirely due to the "no FPI" pgbench,
because after the first ~525 initial segments it looks like this:
no prefetch prefetch prefetch2
58 65 57
So it goes very fast by the initial segments with plenty of FPIs, and
then we get to the "no FPI" segments and the prefetch either does not
help or makes it slower.
Looking at how long it takes to apply the last few segments, it looks
like this:
no prefetch prefetch prefetch2
280 298 478
which is not particularly great, I guess. There however seems to be
something wrong, because with the prefetching I see this in the log:
prefetch:
2020-06-05 02:47:25.970 CEST 1591318045.970 [22961] LOG: recovery no
longer prefetching: unexpected pageaddr 108/E8000000 in log segment
0000000100000108000000FF, offset 0
prefetch2:
2020-06-05 15:29:23.895 CEST 1591363763.895 [26676] LOG: recovery no
longer prefetching: unexpected pageaddr 108/E8000000 in log segment
000000010000010900000001, offset 0
Which seems pretty suspicious, but I have no idea what's wrong. I admit
the archive/restore commands are a bit hacky, but I've only seen this
with prefetching on the SATA storage, while all other cases seem to be
just fine. I haven't seen in on NVME (which processes much more WAL).
And the SATA baseline (no prefetching) also worked fine.
Moreover, the pageaddr value is the same in both cases, but the WAL
segments are different (but just one segment apart). Seems strange.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
| Attachment | Content-Type | Size |
|---|---|---|
|
image/png | 29.3 KB |
|
image/png | 20.4 KB |
|
image/png | 22.7 KB |
In response to
- Re: WIP: WAL prefetch (another approach) at 2020-05-28 11:12:29 from Thomas Munro
Responses
- Re: WIP: WAL prefetch (another approach) at 2020-06-05 20:04:14 from Tomas Vondra
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Tomas Vondra | 2020-06-05 15:38:11 | Re: minor doc fix - garbage in example of result of unnest |
| Previous Message | Antonin Houska | 2020-06-05 15:16:43 | Re: More efficient RI checks - take 2 |