WIP: expression evaluation improvements
| From: | Andres Freund <andres(at)anarazel(dot)de> |
|---|---|
| To: | pgsql-hackers(at)postgresql(dot)org |
| Subject: | WIP: expression evaluation improvements |
| Date: | 2019-10-23 16:38:49 |
| Message-ID: | 20191023163849.sosqbfs5yenocez3@alap3.anarazel.de |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
Hi,
TL;DR: Some performance figures at the end. Lots of details before.
For a while I've been on and off (unfortunately more the latter), been
hacking on improving expression evaluation further.
This is motivated by mainly two factors:
a) Expression evaluation is still often a very significant fraction of
query execution time. Both with and without jit enabled.
b) Currently caching for JITed queries is not possible, as the generated
queries contain pointers that change from query to query
but there are others too (e.g. using less memory, reducing
initialization time).
The main reason why the JITed code is not faster, and why it cannot
really be cached, is that ExprEvalStep's point to memory that's
"outside" of LLVMs view, e.g. via ExprEvalStep->resvalue and the various
FunctionCallInfos. That's currently done by just embedding the raw
pointer value in the generated program (which effectively prevents
caching). LLVM will not really optimize through these memory references,
having difficulty determining aliasing and lifetimes. The fix for that
is to move for on-stack allocations for actually temporary stuff, llvm
can convert that into SSA form, and optimize properly.
In the attached *prototype* patch series there's a lot of incremental
improvements (and some cleanups) (in time, not importance order):
1) A GUC that enables iterating in reverse order over items on a page
during sequential scans. This is mainly to make profiles easier to
read, as the cache misses are otherwise swamping out other effects.
2) A number of optimizations of specific expression evaluation steps:
- reducing the number of aggregate transition steps by "merging"
EEOP_AGG_INIT_TRANS, EEOP_AGG_STRICT_TRANS_CHECK with EEOP_AGG_PLAIN_TRANS{_BYVAL,}
into special case versions for each combination.
- introducing special-case expression steps for common combinations
of steps (EEOP_FUNCEXPR_STRICT_1, EEOP_FUNCEXPR_STRICT_2,
EEOP_AGG_STRICT_INPUT_CHECK_ARGS_1, EEOP_DONE_NO_RETURN).
3) Use NullableDatum for slots and expression evaluation.
This is a small performance win for expression evaluation, and
reduces the number of pointers for each step. The latter is important
for later steps.
4) out-of-line int/float error functions
Right now we have numerous copies of float/int/... error handling
elog()s. That's unnecessary. Instead add functions that issue the
error, not allowing them to be inlined. This is a small win without
jit, and a bigger win with.
5) During expression initialization, compute allocations to be in a
"relative" manner. Each allocation is tracked separately, and
primarily consists out of an 'offset' that initially starts out at
zero, and is increased by the size of each allocation.
For interpreted evaluation, all the memory for these different
allocations is allocated as part of the allocation of the ExprState
itself, following the steps[] array (which now is also
inline). During interpretation it is accessed by basically adding the
offset to a base pointer.
For JIT compiled interpetation the memory is allocated using LLVM's
alloca instruction, which llvm can optimize into SSA form (using the
Mem2Reg or SROA passes). In combination with operator inlining that
enables LLVM to optimize PG function calls away entirely, even
performing common subexpression elimination in some cases.
There's also a few changes that are mainly done as prerequisites:
A) expression eval: Decouple PARAM_CALLBACK interface more strongly from execExpr.c
otherwise too many implementation details are exposed
B) expression eval: Improve ArrayCoerce evaluation implementation.
the recursive evaluation with memory from both the outer and inner
expression step being referenced at the same time makes improvements
harder. And it's not particularly fast either.
C) executor: Move per-call information for aggregates out of AggState.
Right now AggState has elements that we set for each transition
function invocation. That's not particularly fast, requires more
bookkeeping, and is harder for compilers to optimize. Instead
introduce a new AggStatePerCallContext that's passed for each
transition invocation via FunctionCallInfo->context.
D) Add "builder" state objects for ExecInitExpr() and
llvm_compile_expr(). That makes it easier to pass more state around,
and have different representations for the expression currently being
built, and once ready. Also makes it more realistic to break up
llvm_compile_expr() into smaller functions.
E) Improving the naming of JITed basic blocks, including the textual
ExprEvalOp value. Makes it a lot easier to understand the generated
code. Should be used to add a function for some minimal printing of
ExprStates.
F) Add minimal (and very hacky) DWARF output for the JITed
programs. That's useful for debugging, but more importantly makes it
a lot easier to interpret perf profiles.
The patchset leaves a lot of further optimization potential for better
code generation on the floor, but this seems a good enough intermediate
point. The generated code is not *quite* cachable yet,
FunctionCallInfo->{flinfo, context} still point to a pointer constant. I
think this can be solved in the same way as the rest, I just didn't get
to it yet.
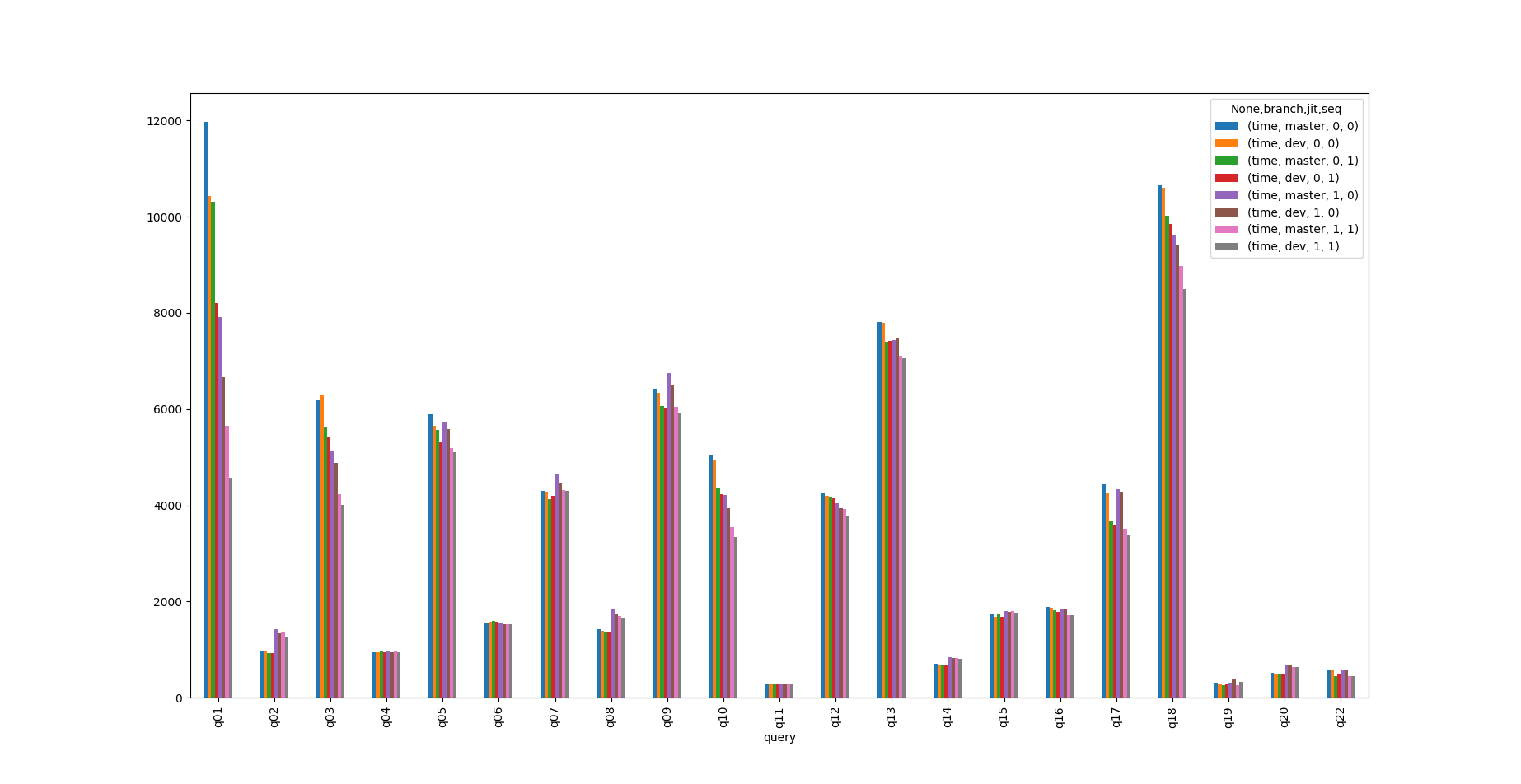
Attached is a graph of tpch query times. branch=master/dev is master
(with just the seqscan patch applied), jit=0/1 is jit enabled or not,
seq=0/1 is whether faster seqscan ordering is enabled or not.
This is just tpch, with scale factor 5, on my laptop. I.e. not to be
taken too serious. I've started a scale 10, but I'm not going to wait
for the results.
Obviously the results are nice for some queries, and meh for others.
For Q01 we get:
time time time time time time time time
branch master dev master dev master dev master dev
jit 0 0 0 0 1 1 1 1
seq 0 0 1 1 0 0 1 1
query
q01 11965.224 10434.316 10309.404 8205.922 7918.81 6661.359 5653.64 4573.794
Which imo is pretty nice. And that's with quite some pessimizations in
the code, without those (which can be removed with just a bit of elbow
grease), the benefit is noticably bigger.
FWIW, for q01 the profile after these changes is:
- 94.29% 2.16% postgres postgres [.] ExecAgg
- 98.97% ExecAgg
- 35.61% lookup_hash_entries
- 95.08% LookupTupleHashEntry
- 60.44% TupleHashTableHash.isra.0
- 99.91% FunctionCall1Coll
+ hashchar
+ 23.34% evalexpr_0_4
+ 11.67% ExecStoreMinimalTuple
+ 4.49% MemoryContextReset
3.64% tts_minimal_clear
1.22% ExecStoreVirtualTuple
+ 34.17% evalexpr_0_7
- 29.38% fetch_input_tuple
- 99.98% ExecSeqScanQual
- 58.15% heap_getnextslot
- 72.70% heapgettup_pagemode
- 99.25% heapgetpage
+ 79.08% ReadBufferExtended
+ 7.08% LockBuffer
+ 6.78% CheckForSerializableConflictOut
+ 3.26% UnpinBuffer.constprop.0
+ 1.94% heap_page_prune_opt
1.80% ReleaseBuffer
+ 0.66% ss_report_location
+ 27.22% ExecStoreBufferHeapTuple
+ 33.00% evalexpr_0_0
+ 5.16% ExecRunCompiledExpr
+ 3.65% MemoryContextReset
+ 0.84% MemoryContextReset
I.e. we spend a significant fraction of the time doing hash computations
(TupleHashTableHash, which is implemented very inefficiently), hash
equality checks (evalexpr_0_4, which is inefficiently done because we do
not cary NOT NULL upwards), the aggregate transition (evalexpr_0_7, now most
bottlenecked by float8_combine()), and fetching/filtering the tuple
(with buffer lookups taking the majority of the time, followed by qual
evaluation (evalexpr_0_0)).
Greetings,
Andres Freund
Responses
- Re: WIP: expression evaluation improvements at 2019-10-24 21:59:21 from Soumyadeep Chakraborty
- Re: WIP: expression evaluation improvements at 2019-10-24 22:43:37 from Andreas Karlsson
- Re: WIP: expression evaluation improvements at 2021-11-04 16:30:00 from Robert Haas
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Peter J. Holzer | 2019-10-23 18:33:06 | Re: jsonb_set() strictness considered harmful to data |
| Previous Message | Maciek Sakrejda | 2019-10-23 16:13:08 | Re: EXPLAIN BUFFERS and I/O timing accounting questions |