Re: [patch] BUG #15005: ANALYZE can make pg_class.reltuples inaccurate.
| From: | Alexander Kuzmenkov <a(dot)kuzmenkov(at)postgrespro(dot)ru> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | David Gould <daveg(at)sonic(dot)net>, pgsql-hackers(at)lists(dot)postgresql(dot)org, Alina Alexeeva <alexeeva(at)adobe(dot)com>, Ullas Lakkur Raghavendra <lakkurra(at)adobe(dot)com> |
| Subject: | Re: [patch] BUG #15005: ANALYZE can make pg_class.reltuples inaccurate. |
| Date: | 2018-03-02 15:47:44 |
| Message-ID: | 101dd073-1cb7-b471-7eeb-aa9ee928a1c9@postgrespro.ru |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
On 02.03.2018 02:49, Tom Lane wrote:
> I looked at this and don't think it really answers the question. What
> happens is that, precisely because we only slowly adapt our estimate of
> density towards the new measurement, we will have an overestimate of
> density if the true density is decreasing (even if the new measurement is
> spot-on), and that corresponds exactly to an overestimate of reltuples.
> No surprise there. The question is why it fails to converge to reality
> over time.
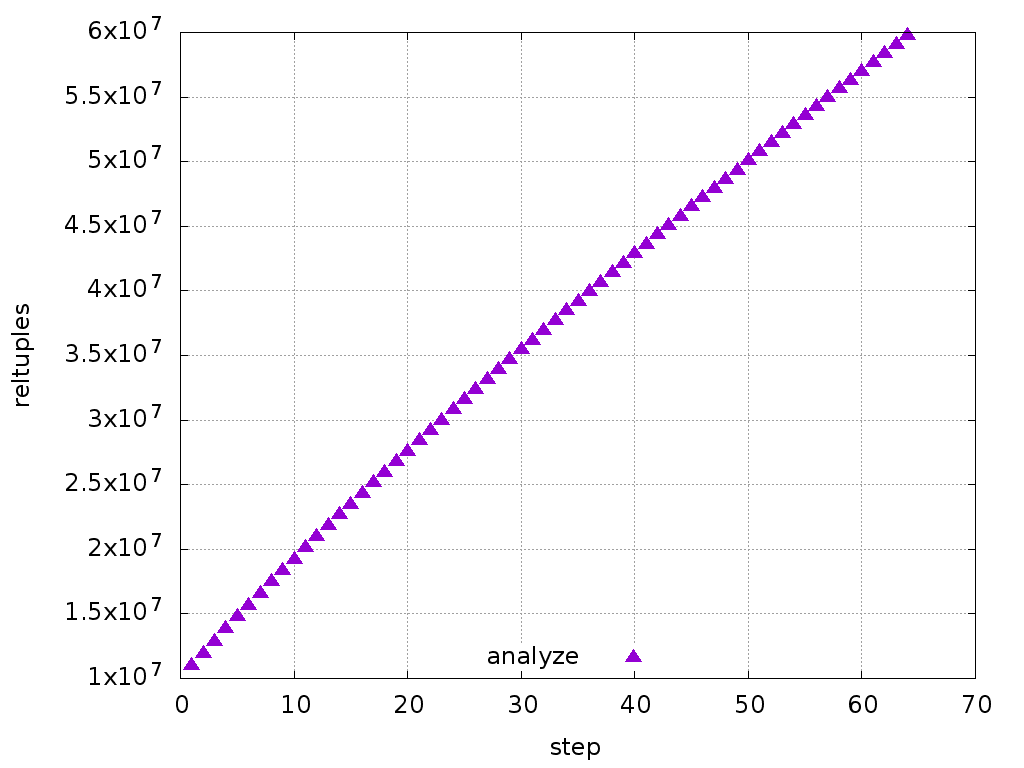
The calculation I made for the first step applies to the next steps too,
with minor differences. So, the estimate increases at each step. Just
out of interest, I plotted the reltuples for 60 steps, and it doesn't
look like it's going to converge anytime soon (see attached).
Looking at the formula, this overshoot term is created when we multiply
the old density by the new number of pages. I'm not sure how to fix
this. I think we could average the number of tuples, not the densities.
The attached patch demonstrates what I mean.
--
Alexander Kuzmenkov
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
| Attachment | Content-Type | Size |
|---|---|---|
|
image/png | 14.1 KB |
| reltuples-avg.patch | text/x-patch | 3.5 KB |
In response to
- Re: [patch] BUG #15005: ANALYZE can make pg_class.reltuples inaccurate. at 2018-03-01 23:49:20 from Tom Lane
Responses
- Re: [patch] BUG #15005: ANALYZE can make pg_class.reltuples inaccurate. at 2018-03-02 22:00:37 from David Gould
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Robert Haas | 2018-03-02 15:47:58 | Re: [HACKERS] path toward faster partition pruning |
| Previous Message | Alvaro Herrera | 2018-03-02 15:36:10 | Re: ON CONFLICT DO UPDATE for partitioned tables |