RE: [PoC] Non-volatile WAL buffer
| From: | Takashi Menjo <takashi(dot)menjou(dot)vg(at)hco(dot)ntt(dot)co(dot)jp> |
|---|---|
| To: | 'PostgreSQL-development' <pgsql-hackers(at)postgresql(dot)org> |
| Cc: | 'Robert Haas' <robertmhaas(at)gmail(dot)com>, 'Heikki Linnakangas' <hlinnaka(at)iki(dot)fi>, 'Amit Langote' <amitlangote09(at)gmail(dot)com> |
| Subject: | RE: [PoC] Non-volatile WAL buffer |
| Date: | 2020-03-18 08:58:45 |
| Message-ID: | 002701d5fd03$6e1d97a0$4a58c6e0$@hco.ntt.co.jp_1 |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
Dear hackers,
I rebased my non-volatile WAL buffer's patchset onto master. A new v2 patchset is attached to this mail.
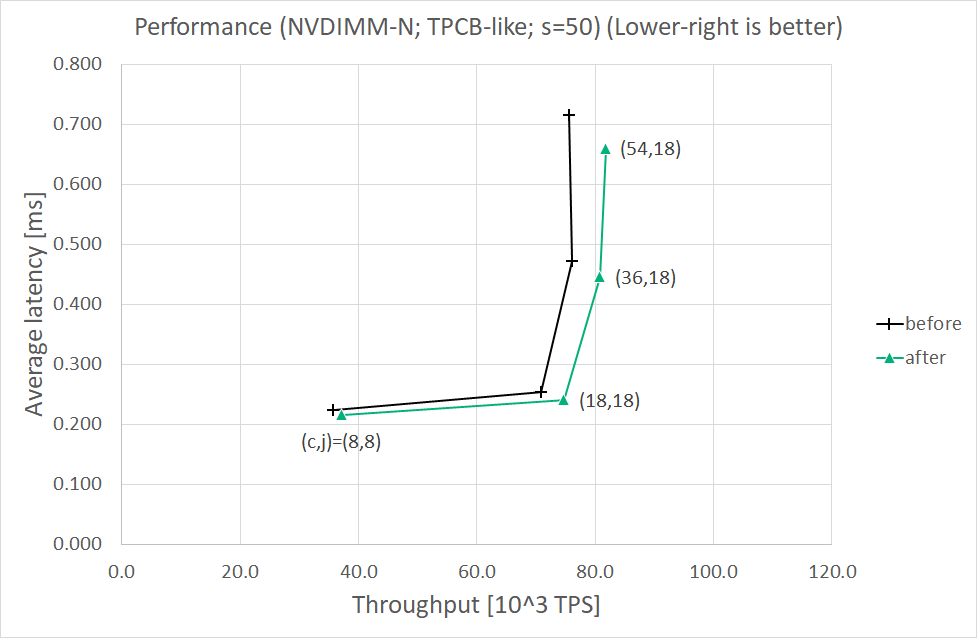
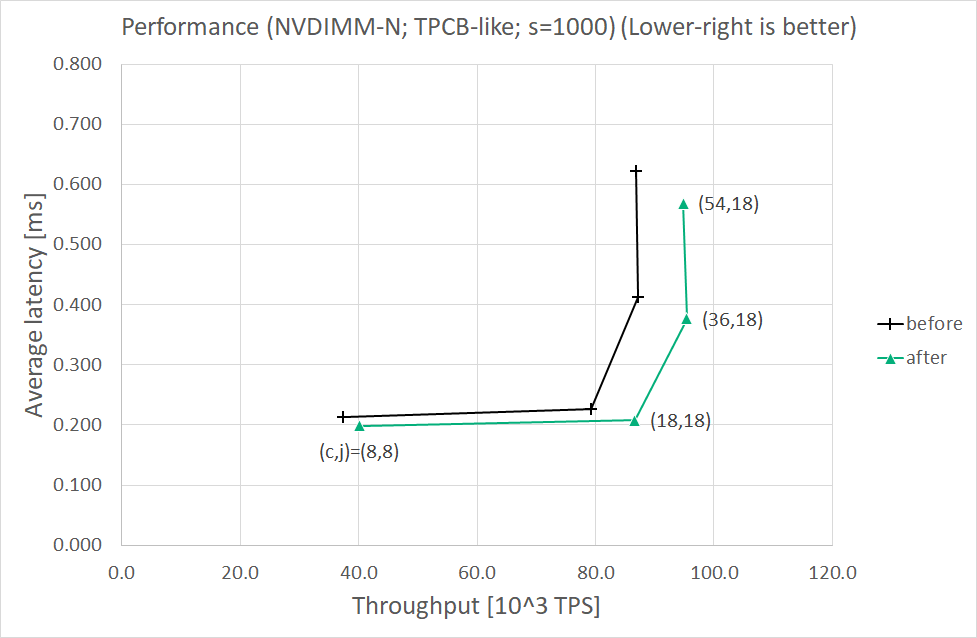
I also measured performance before and after patchset, varying -c/--client and -j/--jobs options of pgbench, for each scaling factor s = 50 or 1000. The results are presented in the following tables and the attached charts. Conditions, steps, and other details will be shown later.
Results (s=50)
==============
Throughput [10^3 TPS] Average latency [ms]
( c, j) before after before after
------- --------------------- ---------------------
( 8, 8) 35.7 37.1 (+3.9%) 0.224 0.216 (-3.6%)
(18,18) 70.9 74.7 (+5.3%) 0.254 0.241 (-5.1%)
(36,18) 76.0 80.8 (+6.3%) 0.473 0.446 (-5.7%)
(54,18) 75.5 81.8 (+8.3%) 0.715 0.660 (-7.7%)
Results (s=1000)
================
Throughput [10^3 TPS] Average latency [ms]
( c, j) before after before after
------- --------------------- ---------------------
( 8, 8) 37.4 40.1 (+7.3%) 0.214 0.199 (-7.0%)
(18,18) 79.3 86.7 (+9.3%) 0.227 0.208 (-8.4%)
(36,18) 87.2 95.5 (+9.5%) 0.413 0.377 (-8.7%)
(54,18) 86.8 94.8 (+9.3%) 0.622 0.569 (-8.5%)
Both throughput and average latency are improved for each scaling factor. Throughput seemed to almost reach the upper limit when (c,j)=(36,18).
The percentage in s=1000 case looks larger than in s=50 case. I think larger scaling factor leads to less contentions on the same tables and/or indexes, that is, less lock and unlock operations. In such a situation, write-ahead logging appears to be more significant for performance.
Conditions
==========
- Use one physical server having 2 NUMA nodes (node 0 and 1)
- Pin postgres (server processes) to node 0 and pgbench to node 1
- 18 cores and 192GiB DRAM per node
- Use an NVMe SSD for PGDATA and an interleaved 6-in-1 NVDIMM-N set for pg_wal
- Both are installed on the server-side node, that is, node 0
- Both are formatted with ext4
- NVDIMM-N is mounted with "-o dax" option to enable Direct Access (DAX)
- Use the attached postgresql.conf
- Two new items nvwal_path and nvwal_size are used only after patch
Steps
=====
For each (c,j) pair, I did the following steps three times then I found the median of the three as a final result shown in the tables above.
(1) Run initdb with proper -D and -X options; and also give --nvwal-path and --nvwal-size options after patch
(2) Start postgres and create a database for pgbench tables
(3) Run "pgbench -i -s ___" to create tables (s = 50 or 1000)
(4) Stop postgres, remount filesystems, and start postgres again
(5) Execute pg_prewarm extension for all the four pgbench tables
(6) Run pgbench during 30 minutes
pgbench command line
====================
$ pgbench -h /tmp -p 5432 -U username -r -M prepared -T 1800 -c ___ -j ___ dbname
I gave no -b option to use the built-in "TPC-B (sort-of)" query.
Software
========
- Distro: Ubuntu 18.04
- Kernel: Linux 5.4 (vanilla kernel)
- C Compiler: gcc 7.4.0
- PMDK: 1.7
- PostgreSQL: d677550 (master on Mar 3, 2020)
Hardware
========
- System: HPE ProLiant DL380 Gen10
- CPU: Intel Xeon Gold 6154 (Skylake) x 2sockets
- DRAM: DDR4 2666MHz {32GiB/ch x 6ch}/socket x 2sockets
- NVDIMM-N: DDR4 2666MHz {16GiB/ch x 6ch}/socket x 2sockets
- NVMe SSD: Intel Optane DC P4800X Series SSDPED1K750GA
Best regards,
Takashi
--
Takashi Menjo <takashi(dot)menjou(dot)vg(at)hco(dot)ntt(dot)co(dot)jp>
NTT Software Innovation Center
> -----Original Message-----
> From: Takashi Menjo <takashi(dot)menjou(dot)vg(at)hco(dot)ntt(dot)co(dot)jp>
> Sent: Thursday, February 20, 2020 6:30 PM
> To: 'Amit Langote' <amitlangote09(at)gmail(dot)com>
> Cc: 'Robert Haas' <robertmhaas(at)gmail(dot)com>; 'Heikki Linnakangas' <hlinnaka(at)iki(dot)fi>; 'PostgreSQL-development'
> <pgsql-hackers(at)postgresql(dot)org>
> Subject: RE: [PoC] Non-volatile WAL buffer
>
> Dear Amit,
>
> Thank you for your advice. Exactly, it's so to speak "do as the hackers do when in pgsql"...
>
> I'm rebasing my branch onto master. I'll submit an updated patchset and performance report later.
>
> Best regards,
> Takashi
>
> --
> Takashi Menjo <takashi(dot)menjou(dot)vg(at)hco(dot)ntt(dot)co(dot)jp> NTT Software Innovation Center
>
> > -----Original Message-----
> > From: Amit Langote <amitlangote09(at)gmail(dot)com>
> > Sent: Monday, February 17, 2020 5:21 PM
> > To: Takashi Menjo <takashi(dot)menjou(dot)vg(at)hco(dot)ntt(dot)co(dot)jp>
> > Cc: Robert Haas <robertmhaas(at)gmail(dot)com>; Heikki Linnakangas
> > <hlinnaka(at)iki(dot)fi>; PostgreSQL-development
> > <pgsql-hackers(at)postgresql(dot)org>
> > Subject: Re: [PoC] Non-volatile WAL buffer
> >
> > Hello,
> >
> > On Mon, Feb 17, 2020 at 4:16 PM Takashi Menjo <takashi(dot)menjou(dot)vg(at)hco(dot)ntt(dot)co(dot)jp> wrote:
> > > Hello Amit,
> > >
> > > > I apologize for not having any opinion on the patches themselves,
> > > > but let me point out that it's better to base these patches on
> > > > HEAD (master branch) than REL_12_0, because all new code is
> > > > committed to the master branch, whereas stable branches such as
> > > > REL_12_0 only receive bug fixes. Do you have any
> > specific reason to be working on REL_12_0?
> > >
> > > Yes, because I think it's human-friendly to reproduce and discuss
> > > performance measurement. Of course I know
> > all new accepted patches are merged into master's HEAD, not stable
> > branches and not even release tags, so I'm aware of rebasing my
> > patchset onto master sooner or later. However, if someone, including
> > me, says that s/he applies my patchset to "master" and measures its
> > performance, we have to pay attention to which commit the "master"
> > really points to. Although we have sha1 hashes to specify which
> > commit, we should check whether the specific commit on master has patches affecting performance or not
> because master's HEAD gets new patches day by day. On the other hand, a release tag clearly points the commit
> all we probably know. Also we can check more easily the features and improvements by using release notes and
> user manuals.
> >
> > Thanks for clarifying. I see where you're coming from.
> >
> > While I do sometimes see people reporting numbers with the latest
> > stable release' branch, that's normally just one of the baselines.
> > The more important baseline for ongoing development is the master
> > branch's HEAD, which is also what people volunteering to test your
> > patches would use. Anyone who reports would have to give at least two
> > numbers -- performance with a branch's HEAD without patch applied and
> > that with patch applied -- which can be enough in most cases to see
> > the difference the patch makes. Sure, the numbers might change on
> > each report, but that's fine I'd think. If you continue to develop against the stable branch, you might miss to
> notice impact from any relevant developments in the master branch, even developments which possibly require
> rethinking the architecture of your own changes, although maybe that rarely occurs.
> >
> > Thanks,
> > Amit
| Attachment | Content-Type | Size |
|---|---|---|
| v2-0001-Support-GUCs-for-external-WAL-buffer.patch | application/octet-stream | 30.9 KB |
| v2-0002-Non-volatile-WAL-buffer.patch | application/octet-stream | 45.5 KB |
| v2-0003-README-for-non-volatile-WAL-buffer.patch | application/octet-stream | 6.6 KB |
|
image/png | 28.9 KB |
|
image/png | 29.3 KB |
| postgresql.conf | application/octet-stream | 1.0 KB |
In response to
- Re: [PoC] Non-volatile WAL buffer at 2020-02-17 08:21:08 from Amit Langote
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Fujii Masao | 2020-03-18 09:31:08 | Re: add types to index storage params on doc |
| Previous Message | Atsushi Torikoshi | 2020-03-18 08:56:38 | Re: RecoveryWalAll and RecoveryWalStream wait events |