RE: [PoC] Non-volatile WAL buffer
| From: | Takashi Menjo <takashi(dot)menjou(dot)vg(at)hco(dot)ntt(dot)co(dot)jp> |
|---|---|
| To: | 'Andres Freund' <andres(at)anarazel(dot)de> |
| Cc: | 'Robert Haas' <robertmhaas(at)gmail(dot)com>, 'Heikki Linnakangas' <hlinnaka(at)iki(dot)fi>, pgsql-hackers(at)postgresql(dot)org |
| Subject: | RE: [PoC] Non-volatile WAL buffer |
| Date: | 2020-03-19 06:11:10 |
| Message-ID: | 000c01d5fdb5$2f9db430$8ed91c90$@hco.ntt.co.jp_1 |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
Dear Andres,
Thank you for your advice about MAP_POPULATE flag. I rebased my msync patchset onto master and added a commit to append that flag
when mmap. A new v2 patchset is attached to this mail. Note that this patchset is NOT non-volatile WAL buffer's one.
I also measured performance of the following three versions, varying -c/--client and -j/--jobs options of pgbench, for each scaling
factor s = 50 or 1000.
- Before patchset (say "before")
- After patchset except patch 0005 not to use MAP_POPULATE ("after (no populate)")
- After full patchset to use MAP_POPULATE ("after (populate)")
The results are presented in the following tables and the attached charts. Conditions, steps, and other details will be shown
later. Note that, unlike the measurement of non-volatile WAL buffer I sent recently [1], I used an NVMe SSD for pg_wal to evaluate
this patchset with traditional mmap-ed files, that is, direct access (DAX) is not supported and there are page caches.
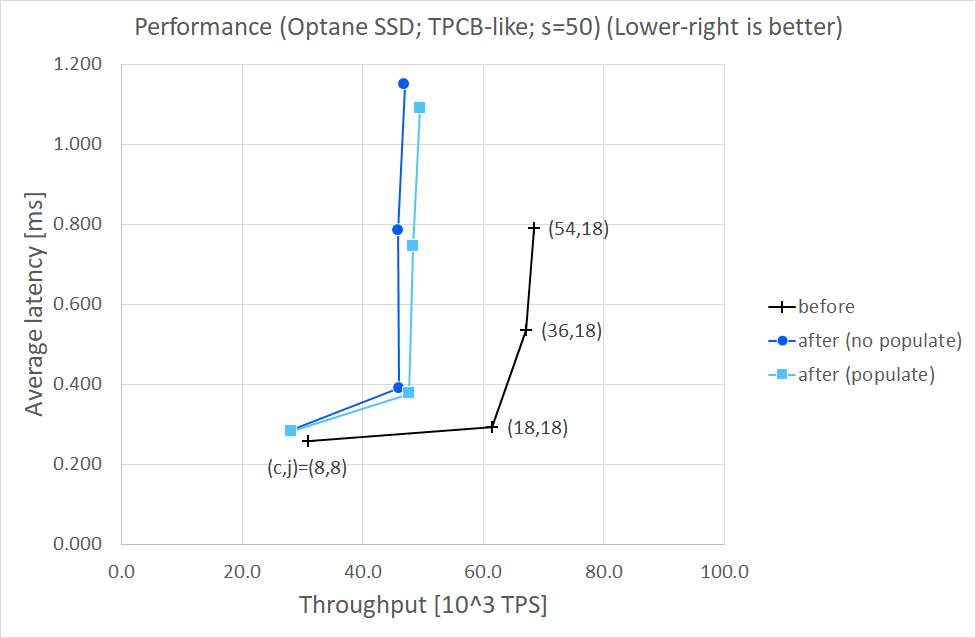
Results (s=50)
==============
Throughput [10^3 TPS]
( c, j) before after after
(no populate) (populate)
------- -------------------------------------
( 8, 8) 30.9 28.1 (- 9.2%) 28.3 (- 8.6%)
(18,18) 61.5 46.1 (-25.0%) 47.7 (-22.3%)
(36,18) 67.0 45.9 (-31.5%) 48.4 (-27.8%)
(54,18) 68.3 47.0 (-31.3%) 49.6 (-27.5%)
Average Latency [ms]
( c, j) before after after
(no populate) (populate)
------- --------------------------------------
( 8, 8) 0.259 0.285 (+10.0%) 0.283 (+ 9.3%)
(18,18) 0.293 0.391 (+33.4%) 0.377 (+28.7%)
(36,18) 0.537 0.784 (+46.0%) 0.744 (+38.5%)
(54,18) 0.790 1.149 (+45.4%) 1.090 (+38.0%)
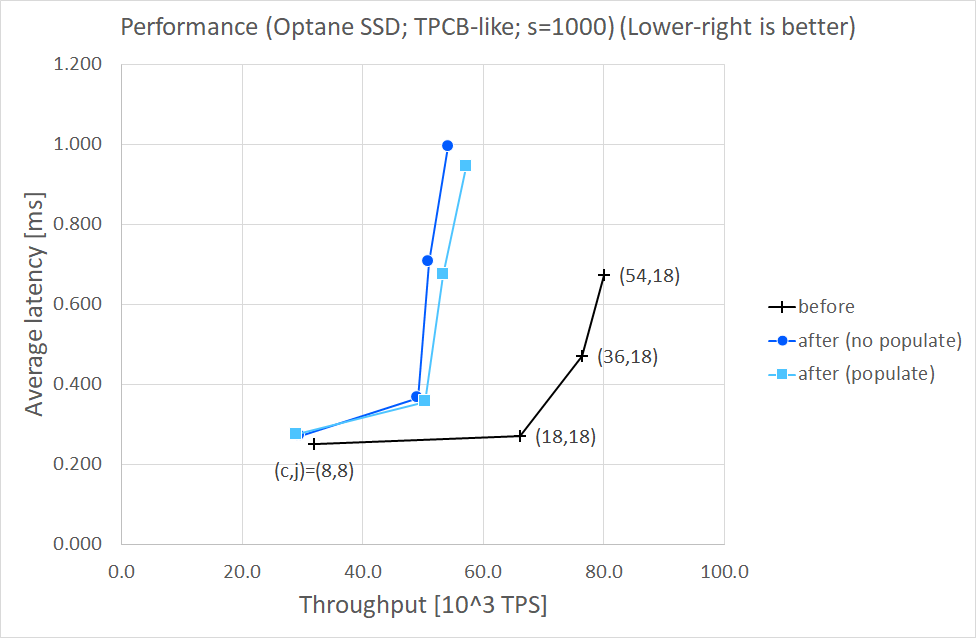
Results (s=1000)
================
Throghput [10^3 TPS]
( c, j) before after after
(no populate) (populate)
------- ------------------------------------
( 8, 8) 32.0 29.6 (- 7.6%) 29.1 (- 9.0%)
(18,18) 66.1 49.2 (-25.6%) 50.4 (-23.7%)
(36,18) 76.4 51.0 (-33.3%) 53.4 (-30.1%)
(54,18) 80.1 54.3 (-32.2%) 57.2 (-28.6%)
Average latency [10^3 TPS]
( c, j) before after after
(no populate) (populate)
------- --------------------------------------
( 8, 8) 0.250 0.271 (+ 8.4%) 0.275 (+10.0%)
(18,18) 0.272 0.366 (+34.6%) 0.357 (+31.3%)
(36,18) 0.471 0.706 (+49.9%) 0.674 (+43.1%)
(54,18) 0.674 0.995 (+47.6%) 0.944 (+40.1%)
I'd say MAP_POPULATE made performance a little better in large #clients cases, comparing "populate" with "no populate". However,
comparing "after" with "before", I found both throughput and average latency degraded. VTune told me that "after (populate)" still
spent larger CPU time for memcpy-ing WAL records into mmap-ed segments than "before".
I also made a microbenchmark to see the behavior of mmap and msync. I found that:
- A major fault occured at mmap with MAP_POPULATE, instead at first access to the mmap-ed space.
- Some minor faults also occured at mmap with MAP_POPULATE, and no additional fault occured when I loaded from the mmap-ed space.
But once I stored to that space, a minor fault occured.
- When I stored to the page that had been msync-ed, a minor fault occurred.
So I think one of the remaining causes of performance degrade is minor faults when mmap-ed pages get dirtied. And it seems not to
be solved by MAP_POPULATE only, as far as I see.
Conditions
==========
- Use one physical server having 2 NUMA nodes (node 0 and 1)
- Pin postgres (server processes) to node 0 and pgbench to node 1
- 18 cores and 192GiB DRAM per node
- Use two NVMe SSDs; one for PGDATA, another for pg_wal
- Both are installed on the server-side node, that is, node 0
- Both are formatted with ext4
- Use the attached postgresql.conf
Steps
=====
For each (c,j) pair, I did the following steps three times then I found the median of the three as a final result shown in the
tables above.
(1) Run initdb with proper -D and -X options
(2) Start postgres and create a database for pgbench tables
(3) Run "pgbench -i -s ___" to create tables (s = 50 or 1000)
(4) Stop postgres, remount filesystems, and start postgres again
(5) Execute pg_prewarm extension for all the four pgbench tables
(6) Run pgbench during 30 minutes
pgbench command line
====================
$ pgbench -h /tmp -p 5432 -U username -r -M prepared -T 1800 -c ___ -j ___ dbname
I gave no -b option to use the built-in "TPC-B (sort-of)" query.
Software
========
- Distro: Ubuntu 18.04
- Kernel: Linux 5.4 (vanilla kernel)
- C Compiler: gcc 7.4.0
- PMDK: 1.7
- PostgreSQL: d677550 (master on Mar 3, 2020)
Hardware
========
- System: HPE ProLiant DL380 Gen10
- CPU: Intel Xeon Gold 6154 (Skylake) x 2sockets
- DRAM: DDR4 2666MHz {32GiB/ch x 6ch}/socket x 2sockets
- NVMe SSD: Intel Optane DC P4800X Series SSDPED1K750GA x2
Best regards,
Takashi
[1] https://www.postgresql.org/message-id/002701d5fd03$6e1d97a0$4a58c6e0$@hco.ntt.co.jp_1
--
Takashi Menjo <takashi(dot)menjou(dot)vg(at)hco(dot)ntt(dot)co(dot)jp>
NTT Software Innovation Center
> -----Original Message-----
> From: Andres Freund <andres(at)anarazel(dot)de>
> Sent: Thursday, February 20, 2020 2:04 PM
> To: Takashi Menjo <takashi(dot)menjou(dot)vg(at)hco(dot)ntt(dot)co(dot)jp>
> Cc: 'Robert Haas' <robertmhaas(at)gmail(dot)com>; 'Heikki Linnakangas' <hlinnaka(at)iki(dot)fi>;
> pgsql-hackers(at)postgresql(dot)org
> Subject: Re: [PoC] Non-volatile WAL buffer
>
> Hi,
>
> On 2020-02-17 13:12:37 +0900, Takashi Menjo wrote:
> > I applied my patchset that mmap()-s WAL segments as WAL buffers to
> > refs/tags/REL_12_0, and measured and analyzed its performance with
> > pgbench. Roughly speaking, When I used *SSD and ext4* to store WAL,
> > it was "obviously worse" than the original REL_12_0. VTune told me
> > that the CPU time of memcpy() called by CopyXLogRecordToWAL() got
> > larger than before.
>
> FWIW, this might largely be because of page faults. In contrast to before we wouldn't reuse the same pages
> (because they've been munmap()/mmap()ed), so the first time they're touched, we'll incur page faults. Did you
> try mmap()ing with MAP_POPULATE? It's probably also worthwhile to try to use MAP_HUGETLB.
>
> Still doubtful it's the right direction, but I'd rather have good numbers to back me up :)
>
> Greetings,
>
> Andres Freund
| Attachment | Content-Type | Size |
|---|---|---|
| v2-0001-Preallocate-more-WAL-segments.patch | application/octet-stream | 3.2 KB |
| v2-0002-Use-WAL-segments-as-WAL-buffers.patch | application/octet-stream | 37.9 KB |
| v2-0003-Lazy-unmap-WAL-segments.patch | application/octet-stream | 2.0 KB |
| v2-0004-Speculative-map-WAL-segments.patch | application/octet-stream | 1.6 KB |
| v2-0005-Map-WAL-segments-with-MAP_POPULATE-if-non-DAX.patch | application/octet-stream | 811 bytes |
|
image/png | 32.1 KB |
|
image/png | 32.1 KB |
| postgresql.conf | application/octet-stream | 970 bytes |
In response to
- Re: [PoC] Non-volatile WAL buffer at 2020-02-20 05:04:16 from Andres Freund
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Fujii Masao | 2020-03-19 06:34:49 | Re: RecoveryWalAll and RecoveryWalStream wait events |
| Previous Message | Justin Pryzby | 2020-03-19 06:06:58 | Re: Berserk Autovacuum (let's save next Mandrill) |