Re: index prefetching
| From: | Tomas Vondra <tomas(at)vondra(dot)me> |
|---|---|
| To: | Peter Geoghegan <pg(at)bowt(dot)ie> |
| Cc: | Andres Freund <andres(at)anarazel(dot)de>, Thomas Munro <thomas(dot)munro(at)gmail(dot)com>, Nazir Bilal Yavuz <byavuz81(at)gmail(dot)com>, Robert Haas <robertmhaas(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com>, PostgreSQL Hackers <pgsql-hackers(at)lists(dot)postgresql(dot)org>, Georgios <gkokolatos(at)protonmail(dot)com>, Konstantin Knizhnik <knizhnik(at)garret(dot)ru>, Dilip Kumar <dilipbalaut(at)gmail(dot)com> |
| Subject: | Re: index prefetching |
| Date: | 2025-09-15 13:00:42 |
| Message-ID: | fc587bd2-fd63-4cc7-a36b-f0d7a095fe60@vondra.me |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
On 9/11/25 00:24, Peter Geoghegan wrote:
> On Thu, Sep 4, 2025 at 2:55 PM Tomas Vondra <tomas(at)vondra(dot)me> wrote:
>> Aren't plenty of real-world data sets correlated, but not perfectly?
>
> Attached is the latest revision of the prefetching patch, taken from
> the shared branch that Tomas and I have been working on for some
> weeks.
>
> This revision is the first "official revision" that uses the complex
> approach, which we agreed was the best approach right before we
> started collaborating through this shared branch. While Tomas and I
> have posted versions of this "complex" approach at various times,
> those were "unofficial" previews of different approaches. Whereas this
> is the latest official patch revision of record, that should be tested
> by CFTester for the prefetch patch's CF entry, etc.
>
> We haven't done a good job of maintaining an unambiguous, easy to test
> "official" CF entry patch before now. That's why I'm being explicit
> about what this patch revision represents. It's the shared work of
> Tomas and I; it isn't some short-term experimental fork. Future
> revisions will be incremental improvements on what I'm posting now.
>
Indeed, the thread is very confusing as it mixes up different
approaches, various experimental patches etc. Thank you for cleaning
this up, and doing various other fixes.
> Our focus has been on fixing a variety of regressions that came to
> light following testing by Tomas. There are a few bigger changes that
> are intended to fix these regressions, plus lots of small changes.
>
> There's too many small changes to list. But the bigger changes are:
>
> * We're now carrying Andres' patch [1] that deals with inefficiencies
> on the read stream side [2]. We need this to get decent performance
> with certain kinds of index scans where the same heap page buffer
> needs to be read multiple times in close succession.
>
> * We now delay prefetching/creating a new read stream until after
> we've already read one index batch, with the goal of avoiding
> regressions on cheap, selective queries (e.g., pgbench SELECT). This
> optimization has been referred to as the "priorbatch" optimization
> earlier in this thread.
>
> * The third patch is a new one, authored by Tomas. It aims to
> ameliorate nestloop join regressions by caching memory used to store
> batches across rescans.
>
> This is still experimental.
>
Yeah. I realize the commit message does not explain the motivation, so
let me fix that - the batches are pretty much the same thing as
~BTScanPosData, which means it's ~30KB struct. That means it's not
cached in memory contexts, but each palloc/pfree is malloc/free.
That's already a known problem (e.g. for scans on partitioned tables),
but batches make it worse - we now need more instances of the struct. So
it's even more important to not do far more malloc/free calls.
It's not perfect, but it was good enough to eliminate the overhead.
> * The regression that we were concerned about most recently [3][4] is
> fixed by a new mechanism that sometimes disables prefetching/the read
> stream some time prefetching begins, having already read a small
> number of batches with prefetching -- the
> INDEX_SCAN_MIN_TUPLE_DISTANCE optimization.
>
> This is also experimental. But it does fully fix the problem at hand,
> without any read stream changes. (This is part of the main prefetching
> patch.)
>
> This works like the "priorbatch" optimization, but in reverse. We
> *unset* the scan's read stream when our INDEX_SCAN_MIN_TUPLE_DISTANCE
> test shows that prefetching hasn't worked out (as opposed to delaying
> starting it up until it starts to look like prefetching might help).
> Like the "priorbatch" optimization, this optimization is concerned
> with fixed prefetching costs that cannot possibly pay for themselves.
>
> Note that we originally believed that the regression in question
> [3][4] necessitated more work on the read stream side, to directly
> account for the way that we saw prefetch distance collapse to 2.0 for
> the entire scan. But our current thinking is that the regression in
> question occurs with scans where wholly avoiding prefetching is the
> right goal. Which is why, tentatively, we're addressing the problem
> within indexam.c itself (not in the read stream), by adding this new
> INDEX_SCAN_MIN_TUPLE_DISTANCE test to the read stream callback. This
> means that various experimental read stream distance patches [3][5]
> that initially seemed relevant no longer appear necessary (and so
> aren't included in this new revision at all).
>
Yeah, this heuristics seems very effective in eliminating the regression
(at least judging by the test results I've seen so far). Two or three
question bother me about it, though:
1) I'm not sure I fully understand how the heuristics works, i.e. how
tracking "tuple distance" in index AM identifies queries where
prefetching can't pay for itself. It's hard to say if the tuple distance
is a good predictor of that. It seems to be in case of the regressed
query, I don't dispute that. AFAICS the reasoning is:
We're prefetching too close ahead, so close the I/O can't possibly
complete, and the overhead of submitting the I/O using AIO is higher
than what what async "saves".
That's great, but is the distance a good measure of that? It has no
concept of what happens prefetching and reading a block, during the
"distance". In the test queries it's virtually nothing, because the
query doesn't do anything with the rows. For more complex queries there
could be plenty of time for the I/O to complete.
Of course, if the query is complex, and the I/O complete n time even for
short distances, it's likely not a huge relative difference ...
2) It's a one-time decision, not adaptive. We start prefetching, and
then at some point (not too long after the scan starts) we make a
decision whether to continue with prefetching or not. And if we disable
it, it's disabled forever. That's fine for the synthetic data sets we
use for testing, because those are synthetic. I'm not sure it'll work
this well for real-world data sets where different parts of the file may
be very different.
This is perfectly fine for a WIP patch, but I believe we should try to
make this adaptive. Which probably means we need to invent a "light"
version of read_stream that initially does sync I/O, and only switches
to async (with all the expensive initialization) later. And then can
switch back to sync, but is ready to maybe start prefetching again if
the data pattern changes.
3) Now that I look at the code in index_scan_stream_read_next, it feels
a bit weird we do the decision based on the "immediate" distance only. I
suspect this may make it quite fragile, in the sense that even a small
local irregularity in the data may result in different "step" changes.
Wouldn't it be better to base this on some "average" distance?
In other words, I'm afraid (2) and (3) are pretty much a "performance
cliff", where a tiny difference in the input can result in wildly
different behavior.
> Much cleanup work remains to get the changes I just described in
> proper shape (to say nothing about open items that we haven't made a
> start on yet, like moving the read stream out of indexam.c and into
> heapam). But it has been too long since the last revision. I'd like to
> establish a regular cadence for posting new revisions of the patch
> set.
>
Thank you! I appreciate the collaboration, it's a huge help.
I kept running the stress test, trying to find cases that regress, and
also to better understand the behavior. The script/charts are available
here: https://github.com/tvondra/prefetch-tests
So far I haven't found any massive regressions (relative to master).
There are data sets where we regress by a couple percent (and it's not
noise). I haven't looked into the details, but I believe most of this
can be attributed to the "AIO costs" we discussed recently (with
signals), and similar things.
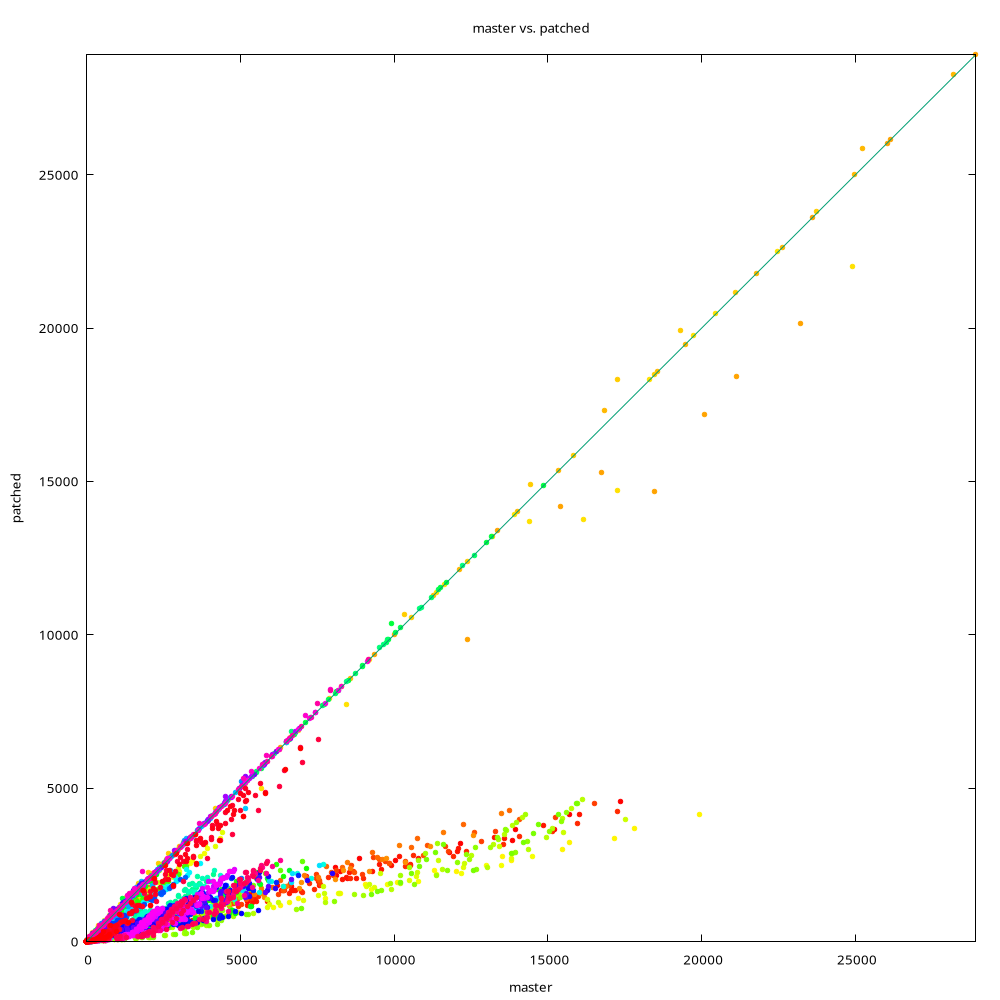
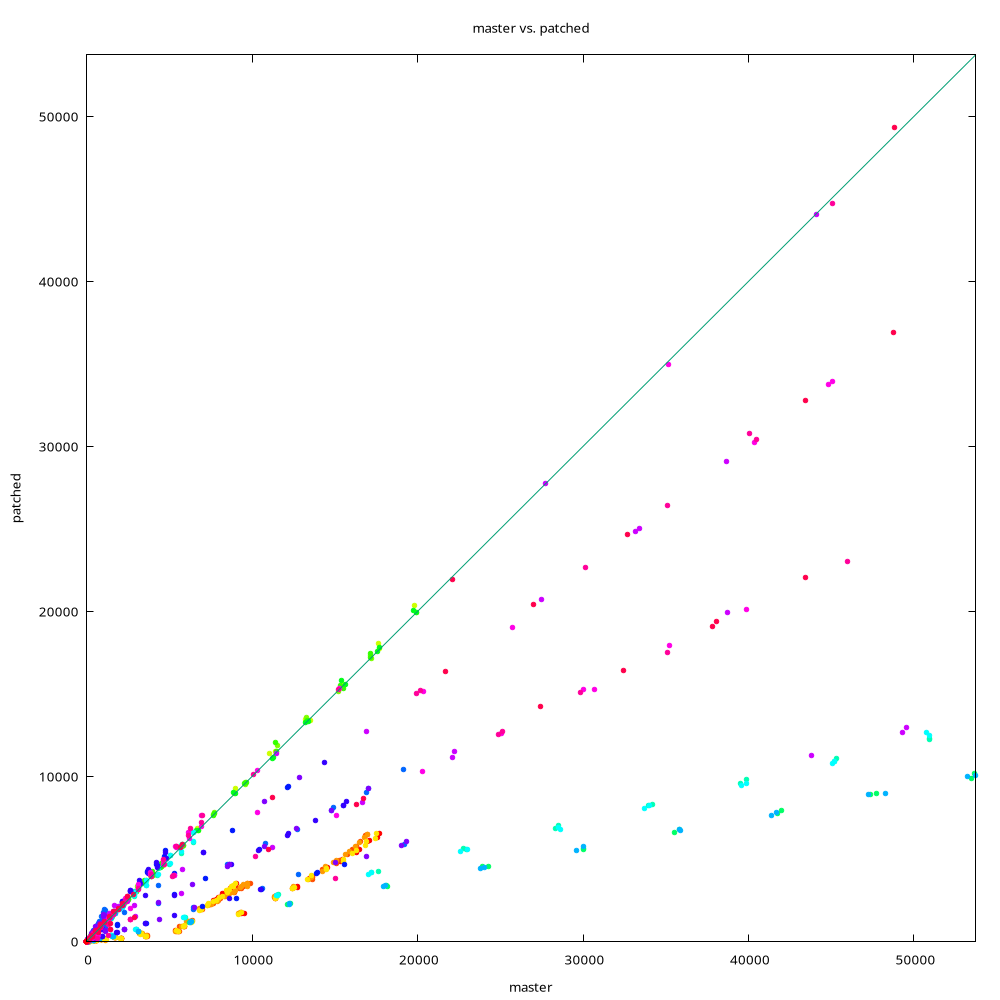
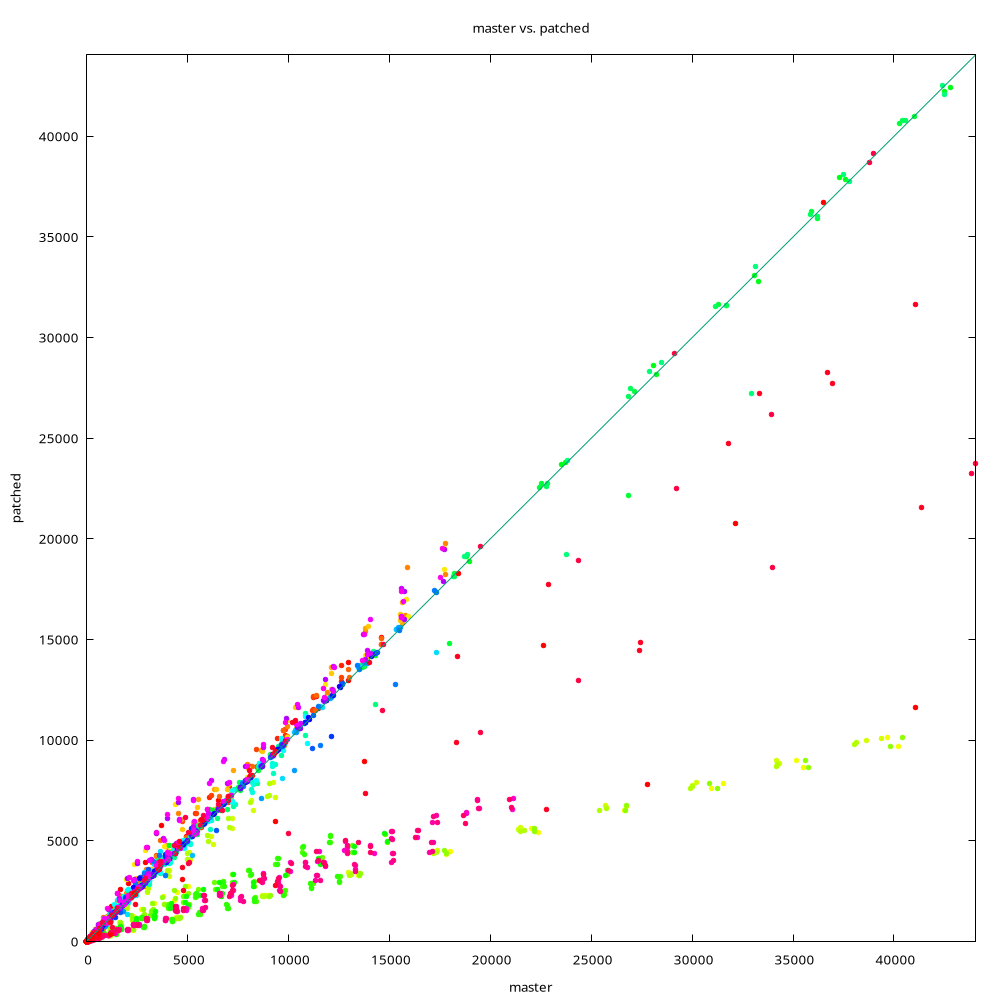
I'm attaching three charts, comparing master to "patched" build with the
20250910 patch applied. I don't think I posted these charts before, so
let me explain a bit. Each chart is a simple XY chart, comparing timings
from master (x-axis) to patched build (y-axis).
Data points on the diagonal mean "same performance", below diagonal is
"patched is faster", above diagonal is "master is faster". So the close
the data point is to x-axis the better, and we want few points above the
diagonal, because those are regressions.
The colors identify different data sets. The script (available in git
repo) generates data sets with different parameters (number of distinct
values, randomness, ...), and the prefetch behavior depends on that.
The charts are from three different setups, with different types of SSD
storage (SATA RAID, NVMe RAID, single NVMe drive). There are some
differences, but the overall behavior is quite similar.
Note: The charts show different number of data sets, the data sets are
not comparable. Each run generates new random parameters, so the same
color does not mean the same parameters.
The git has charts with the patch adjusting the prefetch distance [1].
It does improve behavior with some data sets, but it does not change the
overall behavior (and it does not eliminate the small regressions).
regards
[1]
https://www.postgresql.org/message-id/9b2106a4-4901-4b03-a0b2-db2dbaee4c1f%40vondra.me
--
Tomas Vondra
| Attachment | Content-Type | Size |
|---|---|---|
|
image/png | 72.8 KB |
|
image/png | 48.8 KB |
|
image/png | 72.2 KB |
In response to
- Re: index prefetching at 2025-09-10 22:24:16 from Peter Geoghegan
Responses
- Re: index prefetching at 2025-09-15 15:12:16 from Peter Geoghegan
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Philipp Marek | 2025-09-15 13:16:33 | [PATCH] Better Performance for PostgreSQL with large INSERTs |
| Previous Message | Kirill Reshke | 2025-09-15 12:56:08 | Remove custom redundant full page write description from GIN |