| From: | Konstantin Knizhnik <k(dot)knizhnik(at)postgrespro(dot)ru> |
|---|---|
| To: | PostgreSQL Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Cc: | Bruce Momjian <bruce(at)momjian(dot)us>, Dimitri Fontaine <dim(at)tapoueh(dot)org> |
| Subject: | Re: Built-in connection pooler |
| Date: | 2019-03-20 15:32:03 |
| Message-ID: | ede4470a-055b-1389-0bbd-840f0594b758@postgrespro.ru |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
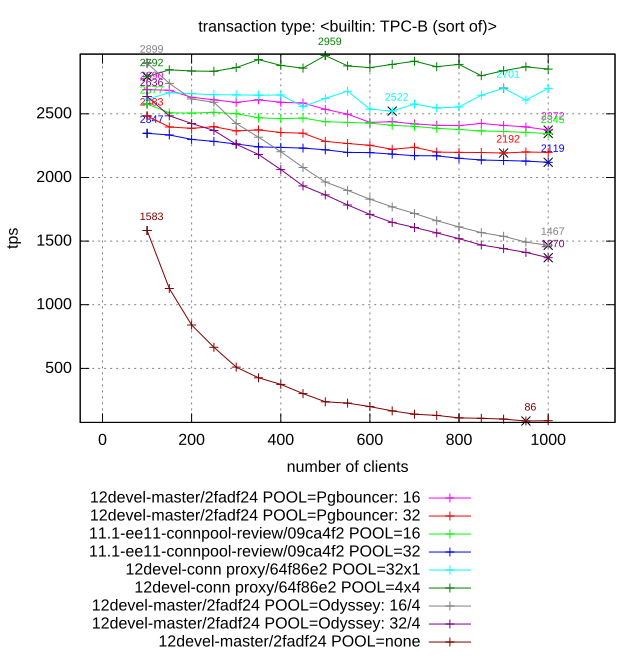
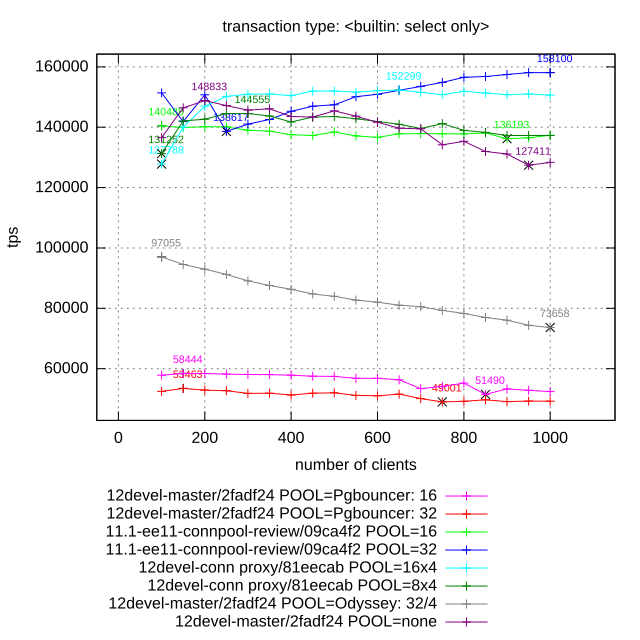
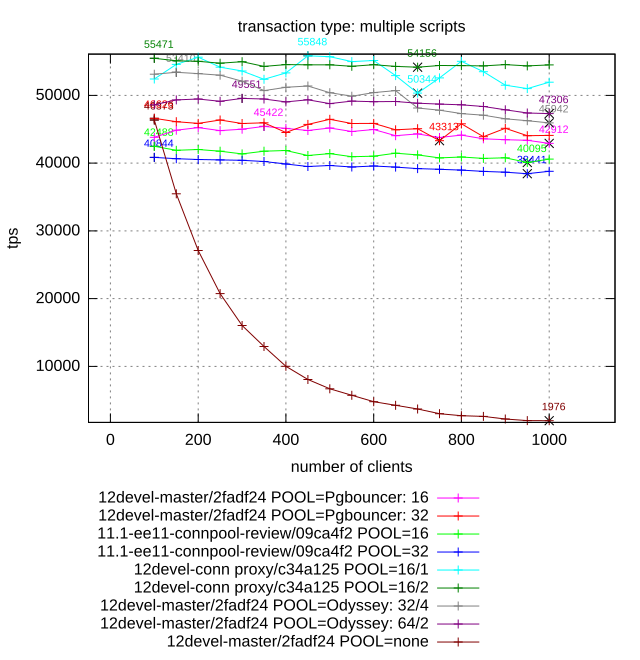
Attached please find results of benchmarking of different connection
poolers.
Hardware configuration:
Intel(R) Xeon(R) CPU X5675 @ 3.07GHz
24 cores (12 physical)
50 GB RAM
Tests:
pgbench read-write (scale 1): performance is mostly limited by
disk throughput
pgbench select-only (scale 1): performance is mostly limited by
efficient utilization of CPU by all workers
pgbench with YCSB-like workload with Zipf distribution:
performance is mostly limited by lock contention
Participants:
1. pgbouncer (16 and 32 pool size, transaction level pooling)
2. Postgres Pro-EE connection poller: redirection of client
connection to poll workers and maintaining of session contexts.
16 and 32 connection pool size (number of worker backend).
3. Built-in proxy connection pooler: implementation proposed in
this thread.
16/1 and 16/2 specifies number of worker backends per proxy and
number of proxies, total number of backends is multiplication of this
values.
4. Yandex Odyssey (32/2 and 64/4 configurations specifies number of
backends and Odyssey threads).
5. Vanilla Postgres (marked at diagram as "12devel-master/2fadf24
POOL=none")
In all cases except 2) master branch of Postgres is used.
Client (pgbench), pooler and postgres are laucnhed at the same host.
Communication is though loopback interface (host=localhost).
We have tried to find the optimal parameters for each pooler.
Three graphics attached to the mail illustrate three different test cases.
Few comments about this results:
- PgPro EE pooler shows the best results in all cases except tpc-b like.
In this case proxy approach is more efficient because more flexible job
schedule between workers
(in EE sessions are scattered between worker backends at connect
time, while proxy chooses least loaded backend for each transaction).
- pgbouncer is not able to scale well because of its single-threaded
architecture. Certainly it is possible to spawn several instances of
pgbouncer and scatter
workload between them. But we have not did it.
- Vanilla Postgres demonstrates significant degradation of performance
for large number of active connections on all workloads except read-only.
- Despite to the fact that Odyssey is new player (or may be because of
it), Yandex pooler doesn't demonstrate good results. It is the only
pooler which also cause degrade of performance with increasing number of
connections. May be it is caused by memory leaks, because it memory
footprint is also actively increased during test.
--
Konstantin Knizhnik
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
| Attachment | Content-Type | Size |
|---|---|---|
| tpc-b.png | image/png | 127.9 KB |
| select-only.png | image/png | 117.9 KB |
| zipf.png | image/png | 127.3 KB |
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Konstantin Knizhnik | 2019-03-20 15:33:42 | Re: Built-in connection pooler |
| Previous Message | Fred .Flintstone | 2019-03-20 15:30:33 | Re: PostgreSQL pollutes the file system |
{kind=link}
{kind=link}
{kind=link}