Re: Hash Indexes
| From: | Jesper Pedersen <jesper(dot)pedersen(at)redhat(dot)com> |
|---|---|
| To: | Amit Kapila <amit(dot)kapila16(at)gmail(dot)com> |
| Cc: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, Mithun Cy <mithun(dot)cy(at)enterprisedb(dot)com>, Robert Haas <robertmhaas(at)gmail(dot)com>, pgsql-hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Hash Indexes |
| Date: | 2016-09-16 18:58:25 |
| Message-ID: | c3ebb759-6353-7745-952f-fbe7068bff66@redhat.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
On 09/16/2016 03:18 AM, Amit Kapila wrote:
>> Attached is a run with 1000 rows.
>>
>
> I think 1000 is also less, you probably want to run it for 100,000 or
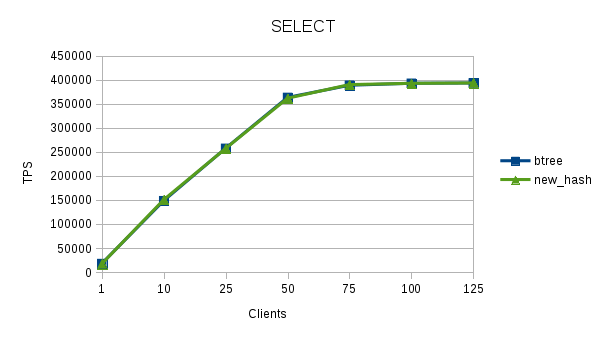
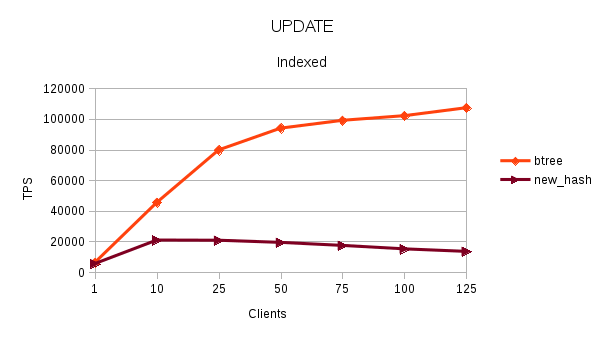
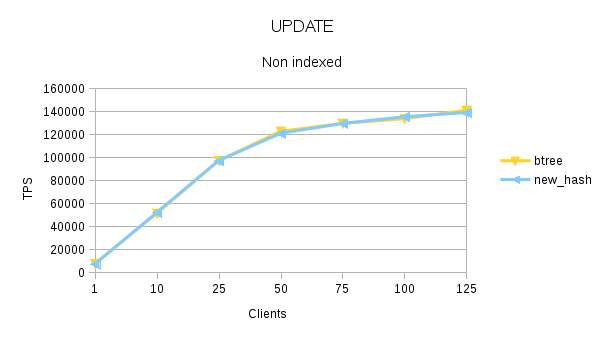
> more rows. I suspect that the reason why you are seeing the large
> difference between btree and hash index is that the range of values is
> narrow and there may be many overflow pages.
>
Attached is 100,000.
>> I think for CHI is would be Robert's and others feedback. For WAL, there is
>> [1].
>>
>
> I have fixed your feedback for WAL and posted the patch.
Thanks !
> I think the
> remaining thing to handle for Concurrent Hash Index patch is to remove
> the usage of hashscan.c from code if no one objects to it, do let me
> know if I am missing something here.
>
Like Robert said, hashscan.c can always come back, and it would take a
call-stack out of the 'am' methods.
Best regards,
Jesper
| Attachment | Content-Type | Size |
|---|---|---|
|
image/png | 14.9 KB |
|
image/png | 14.8 KB |
|
image/png | 14.8 KB |
In response to
- Re: Hash Indexes at 2016-09-16 07:18:10 from Amit Kapila
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Julien Rouhaud | 2016-09-16 19:53:59 | Re: Rename max_parallel_degree? |
| Previous Message | Andres Freund | 2016-09-16 18:38:08 | Re: Hash Indexes |