Re: Hash Indexes
| From: | Jesper Pedersen <jesper(dot)pedersen(at)redhat(dot)com> |
|---|---|
| To: | Amit Kapila <amit(dot)kapila16(at)gmail(dot)com> |
| Cc: | Jeff Janes <jeff(dot)janes(at)gmail(dot)com>, Mithun Cy <mithun(dot)cy(at)enterprisedb(dot)com>, Robert Haas <robertmhaas(at)gmail(dot)com>, pgsql-hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Hash Indexes |
| Date: | 2016-09-14 19:13:01 |
| Message-ID: | a49b17a9-bf5c-822b-4a89-be7d9fdca35c@redhat.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
Hi,
On 09/14/2016 07:24 AM, Amit Kapila wrote:
> On Wed, Sep 14, 2016 at 12:29 AM, Jesper Pedersen
> <jesper(dot)pedersen(at)redhat(dot)com> wrote:
>> On 09/13/2016 07:26 AM, Amit Kapila wrote:
>>>
>>> Attached, new version of patch which contains the fix for problem
>>> reported on write-ahead-log of hash index thread [1].
>>>
>>
>> I have been testing patch in various scenarios, and it has a positive
>> performance impact in some cases.
>>
>> This is especially seen in cases where the values of the indexed column are
>> unique - SELECTs can see a 40-60% benefit over a similar query using b-tree.
>>
>
> Here, I think it is better if we have the data comparing the situation
> of hash index with respect to HEAD as well. What I mean to say is
> that you are claiming that after the hash index improvements SELECT
> workload is 40-60% better, but where do we stand as of HEAD?
>
The tests I have done are with a copy of a production database using the
same queries sent with a b-tree index for the primary key, and the same
with a hash index. Those are seeing a speed-up of the mentioned 40-60%
in execution time - some involve JOINs.
Largest of those tables is 390Mb with a CHAR() based primary key.
>> UPDATE also sees an improvement.
>>
>
> Can you explain this more? Is it more compare to HEAD or more as
> compare to Btree? Isn't this contradictory to what the test in below
> mail shows?
>
Same thing here - where the fields involving the hash index aren't updated.
>> In cases where the indexed column value isn't unique, it takes a long time
>> to build the index due to the overflow page creation.
>>
>> Also in cases where the index column is updated with a high number of
>> clients, ala
>>
>> -- ddl.sql --
>> CREATE TABLE test AS SELECT generate_series(1, 10) AS id, 0 AS val;
>> CREATE INDEX IF NOT EXISTS idx_id ON test USING hash (id);
>> CREATE INDEX IF NOT EXISTS idx_val ON test USING hash (val);
>> ANALYZE;
>>
>> -- test.sql --
>> \set id random(1,10)
>> \set val random(0,10)
>> BEGIN;
>> UPDATE test SET val = :val WHERE id = :id;
>> COMMIT;
>>
>> w/ 100 clients - it takes longer than the b-tree counterpart (2921 tps for
>> hash, and 10062 tps for b-tree).
>>
>
> Thanks for doing the tests. Have you applied both concurrent index
> and cache the meta page patch for these tests? So from above tests,
> we can say that after these set of patches read-only workloads will be
> significantly improved even better than btree in quite-a-few useful
> cases.
Agreed.
> However when the indexed column is updated, there is still a
> large gap as compare to btree (what about the case when the indexed
> column is not updated in read-write transaction as in our pgbench
> read-write transactions, by any chance did you ran any such test?).
I have done a run to look at the concurrency / TPS aspect of the
implementation - to try something different than Mark's work on testing
the pgbench setup.
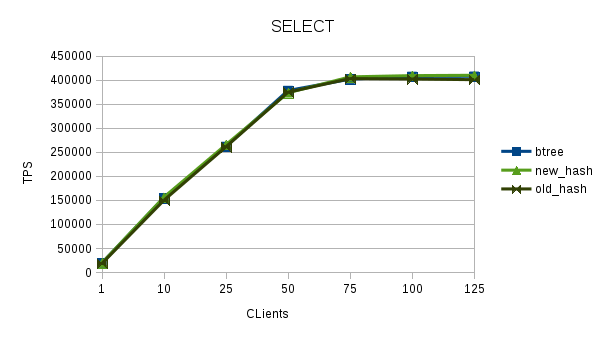
With definitions as above, with SELECT as
-- select.sql --
\set id random(1,10)
BEGIN;
SELECT * FROM test WHERE id = :id;
COMMIT;
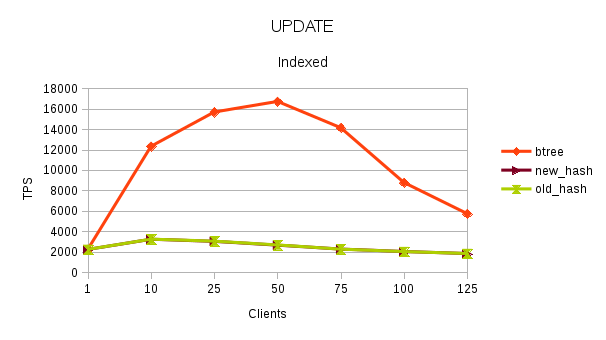
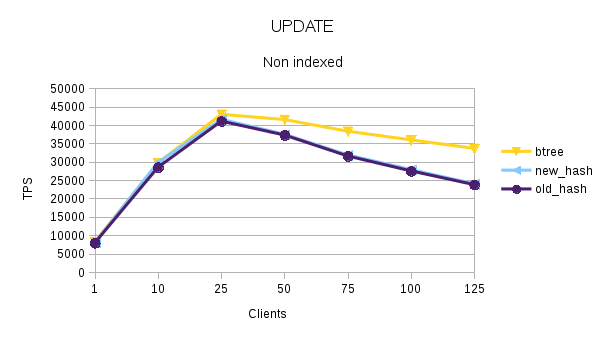
and UPDATE/Indexed with an index on 'val', and finally UPDATE/Nonindexed
w/o one.
[1] [2] [3] is new_hash - old_hash is the existing hash implementation
on master. btree is master too.
Machine is a 28C/56T with 256Gb RAM with 2 x RAID10 SSD for data + wal.
Clients ran with -M prepared.
[1]
https://www.postgresql.org/message-id/CAA4eK1+ERbP+7mdKkAhJZWQ_dTdkocbpt7LSWFwCQvUHBXzkmA@mail.gmail.com
[2]
https://www.postgresql.org/message-id/CAD__OujvYghFX_XVkgRcJH4VcEbfJNSxySd9x=1Wp5VyLvkf8Q@mail.gmail.com
[3]
https://www.postgresql.org/message-id/CAA4eK1JUYr_aB7BxFnSg5+JQhiwgkLKgAcFK9bfD4MLfFK6Oqw@mail.gmail.com
Don't know if you find this useful due to the small number of rows, but
let me know if there are other tests I can run, f.ex. bump the number of
rows.
> I
> think we need to focus on improving cases where index columns are
> updated, but it is better to do that work as a separate patch.
>
Ok.
Best regards,
Jesper
| Attachment | Content-Type | Size |
|---|---|---|
|
image/png | 17.1 KB |
|
image/png | 19.3 KB |
|
image/png | 20.2 KB |
In response to
- Re: Hash Indexes at 2016-09-14 11:24:42 from Amit Kapila
Responses
- Re: Hash Indexes at 2016-09-15 06:03:24 from Amit Kapila
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Petr Jelinek | 2016-09-14 19:17:42 | Re: Logical Replication WIP |
| Previous Message | Andres Freund | 2016-09-14 18:50:11 | Re: Logical Replication WIP |