| From: | Tomas Vondra <tomas(dot)vondra(at)enterprisedb(dot)com> |
|---|---|
| To: | Melanie Plageman <melanieplageman(at)gmail(dot)com>, Heikki Linnakangas <hlinnaka(at)iki(dot)fi> |
| Cc: | Dilip Kumar <dilipbalaut(at)gmail(dot)com>, Robert Haas <robertmhaas(at)gmail(dot)com>, Nazir Bilal Yavuz <byavuz81(at)gmail(dot)com>, Andres Freund <andres(at)anarazel(dot)de>, Pg Hackers <pgsql-hackers(at)postgresql(dot)org>, Thomas Munro <thomas(dot)munro(at)gmail(dot)com> |
| Subject: | Re: BitmapHeapScan streaming read user and prelim refactoring |
| Date: | 2024-03-21 14:55:14 |
| Message-ID: | a31bd142-1d4a-4732-8862-7e009e453b99@enterprisedb.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
On 3/14/24 19:16, Melanie Plageman wrote:
> ...
>
> Attached v6 is rebased over your new commit. It also has the "fix" in
> 0010 which moves BitmapAdjustPrefetchIterator() back above
> table_scan_bitmap_next_block(). I've also updated the Streaming Read API
> commit (0013) to Thomas' v7 version from [1]. This has the update that
> we theorize should address some of the regressions in the bitmapheapscan
> streaming read user in 0014.
>
Based on the recent discussions in this thread I've been wondering how
does the readahead setting for the device affect the behavior, so I've
modified the script to test different values for this parameter too.
Considering the bug in the v7 patch (reported yesterday elsewhere in
this thread), I had to use the v6 version for now. I don't think it
makes much difference, the important parts of the patch do not change.
The complete results are far too large to include here (multiple MBs),
so I'll only include results for a small subset of parameters (one
dataset on i5), and some scatter charts with all results to show the
overall behavior. (I only have results for 1M rows so far).
Complete results (including the raw CSV etc.) are available in a git
repo, along with jupyter notebooks that I started using for experiments
and building the other charts:
https://github.com/tvondra/jupyterlab-projects/tree/master
If you look at the attached PDF table, the first half is for serial
execution (no parallelism), the second half is with 4 workers. And there
are 3 different readahead settings 0, 1536 and 12288 (and then different
eic values for each readahead value). The readahead values are chosen as
"disabled", 6x128kB and the default that was set by the kernel (or
wherever it comes from).
There are pretty clear patterns:
* serial runs with disabled readahead - The patch causes fairly serious
regressions (compared to master), if eic>0.
* serial runs with enabled readahead - there's still some regression for
lower matches values. Presumably, at higher values (which means larger
fraction of the table matches) the readahead kicks in, leaving the lower
values as if readahead was not enabled.
* parallel runs - The regression is much smaller, either because the
parallel workers issue requests almost as if there was readahead, or
maybe it implicitly disrupts the readahead. Not sure.
The other datasets are quite similar, feel free to check the git repo
for complete results.
One possible caveat is that maybe this affects only cases that would not
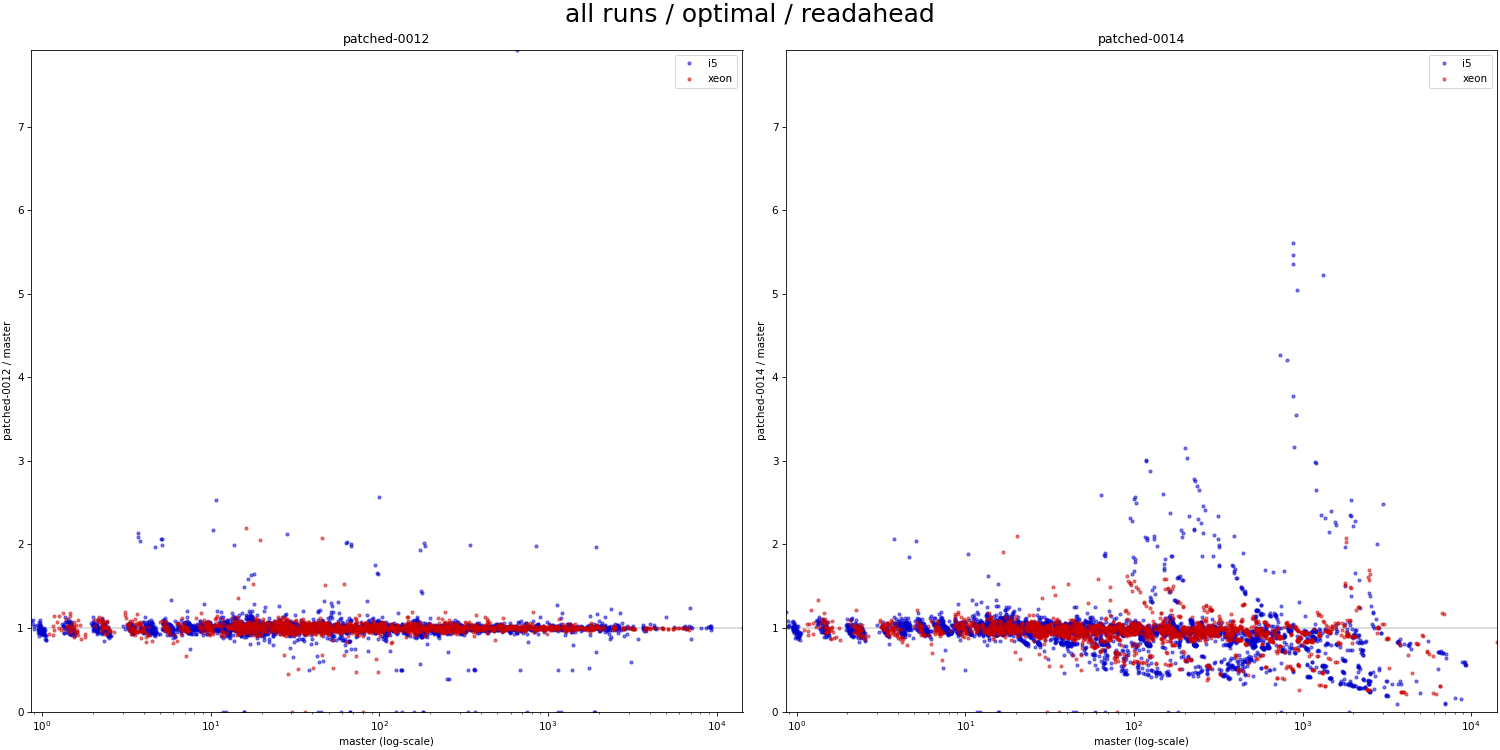
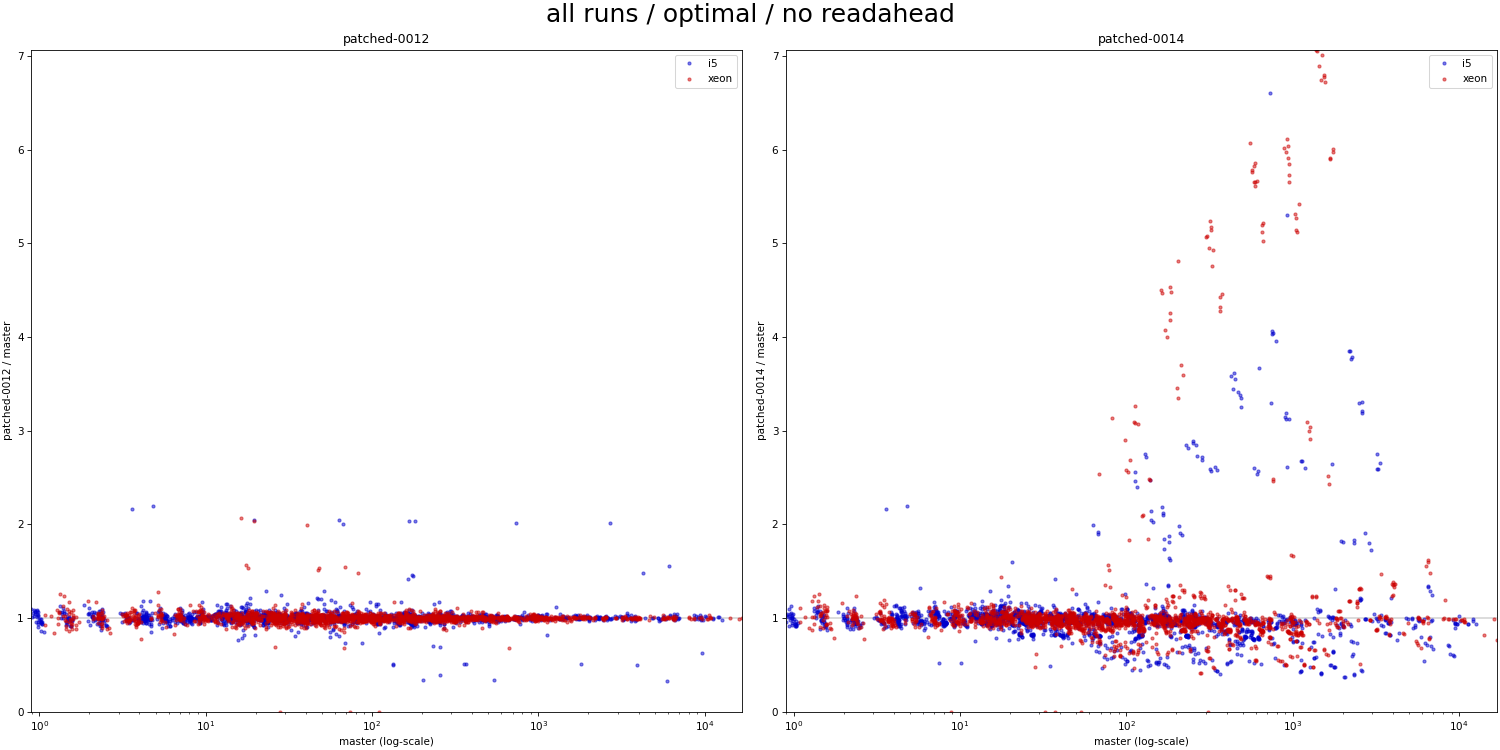
actually use bitmap scans? But if you check the attached scatter charts
(PNG), that only show results for cases where the planner would actually
pick bitmap scans on it's own, there are plenty such cases.
For the 0012 patch (chart on left), there's almost no such problem - the
results are very close to master. Similarly, there are regressions even
on the chart with readahead, but it's far less frequent/significant.
The question is whether readahead=0 is even worth worrying about? If
disabling readahead causes serious regressions even on master (clearly
visible in the PDF table), would anyone actually run with it disabled?
But I'm not sure that argument is very sound. Surely there are cases
where readahead may not detect a pattern, or where it's not supported
for some arbitrary reason (e.g. I didn't have much luck with this on
ZFS, perhaps other filesystems have similar limitations). But also what
about direct I/O? Surely that won't have readahead by kernel, right?
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
| Attachment | Content-Type | Size |
|---|---|---|
| i5-uncached-cyclic.pdf | application/pdf | 150.1 KB |
| relative-all-optimal-readahead-small.png | image/png | 110.3 KB |
| relative-all-optimal-no-readahead-small.png | image/png | 104.1 KB |
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Peter Eisentraut | 2024-03-21 14:57:20 | Re: SQL:2011 application time |
| Previous Message | Jelte Fennema-Nio | 2024-03-21 14:41:44 | Re: Support a wildcard in backtrace_functions |
{kind=link}
{kind=link}