RE: [PATCH] Reuse Workers and Replication Slots during Logical Replication
| From: | "Hayato Kuroda (Fujitsu)" <kuroda(dot)hayato(at)fujitsu(dot)com> |
|---|---|
| To: | "Hayato Kuroda (Fujitsu)" <kuroda(dot)hayato(at)fujitsu(dot)com>, 'Melih Mutlu' <m(dot)melihmutlu(at)gmail(dot)com> |
| Cc: | Peter Smith <smithpb2250(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com>, "Wei Wang (Fujitsu)" <wangw(dot)fnst(at)fujitsu(dot)com>, "Yu Shi (Fujitsu)" <shiy(dot)fnst(at)fujitsu(dot)com>, Amit Kapila <amit(dot)kapila16(at)gmail(dot)com>, pgsql-hackers <pgsql-hackers(at)postgresql(dot)org>, shveta malik <shveta(dot)malik(at)gmail(dot)com> |
| Subject: | RE: [PATCH] Reuse Workers and Replication Slots during Logical Replication |
| Date: | 2023-07-10 02:37:30 |
| Message-ID: | TYAPR01MB58665E956EE02241218E6E18F530A@TYAPR01MB5866.jpnprd01.prod.outlook.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
Dear hackers,
Hi, I did a performance testing for v16 patch set.
Results show that patches significantly improves the performance in most cases.
# Method
Following tests were done 10 times per condition, and compared by median.
do_one_test.sh was used for the testing.
1. Create tables on publisher
2. Insert initial data on publisher
3. Create tables on subscriber
4. Create a replication slot (mysub_slot) on publisher
5. Create a publication on publisher
6. Create tables on subscriber
--- timer on ---
7. Create subscription with pre-existing replication slot (mysub_slot)
8. Wait until all srsubstate in pg_subscription_rel becomes 'r'
--- timer off ---
# Tested sources
I used three types of sources
* HEAD (f863d82)
* HEAD + 0001 + 0002
* HEAD + 0001 + 0002 + 0003
# Tested conditions
Following parameters were changed during the measurement.
### table size
* empty
* around 10kB
### number of tables
* 10
* 100
* 1000
* 2000
### max_sync_workers_per_subscription
* 2
* 4
* 8
* 16
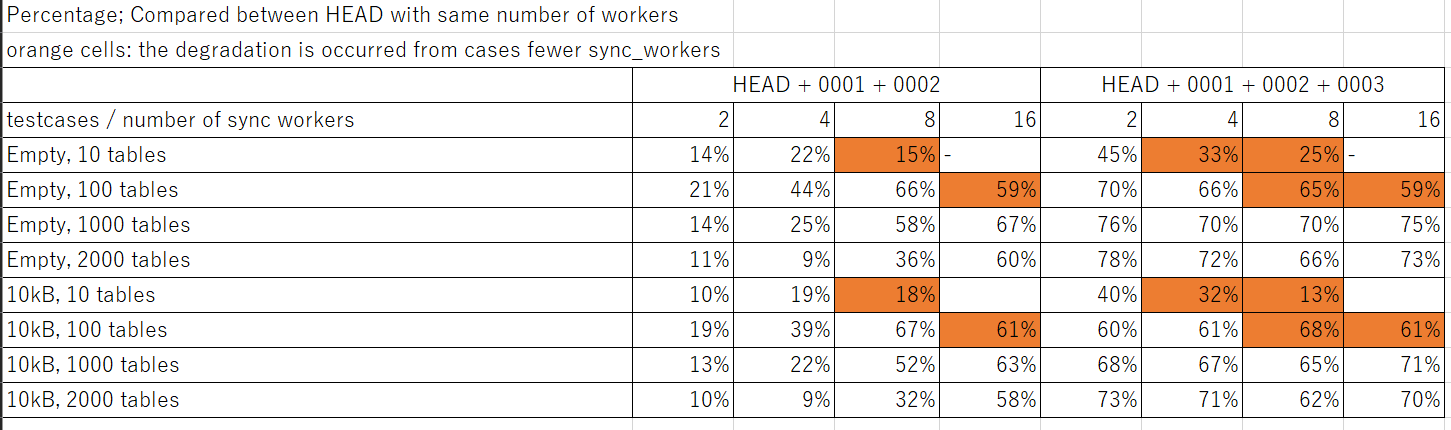
## Results
Please see the attached image file. Each cell shows the improvement percentage of
measurement comapred with HEAD, HEAD + 0001 + 0002, and HEAD + 0001 + 0002 + 0003.
According to the measurement, we can say following things:
* In any cases the performance was improved from the HEAD.
* The improvement became more significantly if number of synced tables were increased.
* 0003 basically improved performance from first two patches
* Increasing workers could sometimes lead to lesser performance due to contention.
This was occurred when the number of tables were small. Moreover, this was not only happen by patchset - it happened even if we used HEAD.
Detailed analysis will be done later.
Mored deital, please see the excel file. It contains all the results of measurement.
## Detailed configuration
* Powerful machine was used:
- Number of CPU: 120
- Memory: 755 GB
* Both publisher and subscriber were on the same machine.
* Following GUC settings were used for both pub/sub:
```
wal_level = logical
shared_buffers = 40GB
max_worker_processes = 32
max_parallel_maintenance_workers = 24
max_parallel_workers = 32
synchronous_commit = off
checkpoint_timeout = 1d
max_wal_size = 24GB
min_wal_size = 15GB
autovacuum = off
max_wal_senders = 200
max_replication_slots = 200
```
Best Regards,
Hayato Kuroda
FUJITSU LIMITED
| Attachment | Content-Type | Size |
|---|---|---|
|
image/png | 47.5 KB |
| perftest_result.xlsx | application/vnd.openxmlformats-officedocument.spreadsheetml.sheet | 32.3 KB |
| do_one_test.sh | application/octet-stream | 3.9 KB |
In response to
- RE: [PATCH] Reuse Workers and Replication Slots during Logical Replication at 2023-07-06 09:47:40 from Hayato Kuroda (Fujitsu)
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Thomas Munro | 2023-07-10 02:51:37 | Re: check_strxfrm_bug() |
| Previous Message | Peter Smith | 2023-07-10 02:24:43 | Re: doc: improve the restriction description of using indexes on REPLICA IDENTITY FULL table. |