| From: | Pavel Borisov <pashkin(dot)elfe(at)gmail(dot)com> |
|---|---|
| To: | Andres Freund <andres(at)anarazel(dot)de> |
| Cc: | Alexander Korotkov <aekorotkov(at)gmail(dot)com>, Postgres hackers <pgsql-hackers(at)lists(dot)postgresql(dot)org> |
| Subject: | Re: Lockless queue of waiters in LWLock |
| Date: | 2022-11-11 11:39:05 |
| Message-ID: | CALT9ZEHSX1Hpz5xjDA62yHAHtpinkA6hg8Zt-odyxqppmKbQFA@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
Hi, Andres, and Alexander!
I've done some more measurements to check the hypotheses regarding the
performance of a previous patch v2, and explain the results of tests
in [1].
The results below are the same (tps vs connections) plots as in [1],
and the test is identical to the insert test in this thread [2].
Additionally, in each case, there is a plot with results relative to
Andres Freund's patch [3]. Log plots are good for seeing details in
the range of 20-30 connections, but they somewhat hide the fact that
the effect in the range of 500+ connections is much more significant
overall, so I'd recommend looking at the linear plots as well.
The particular tests:
1. Whether CAS operation cost in comparison to the atomic-sub affects
performance.
The patch (see attached
atomic-sub-instead-of-CAS-for-shared-lockers-without.patch) uses
atomic-sub to change LWlock state variable for releasing a shared lock
that doesn't have a waiting queue.
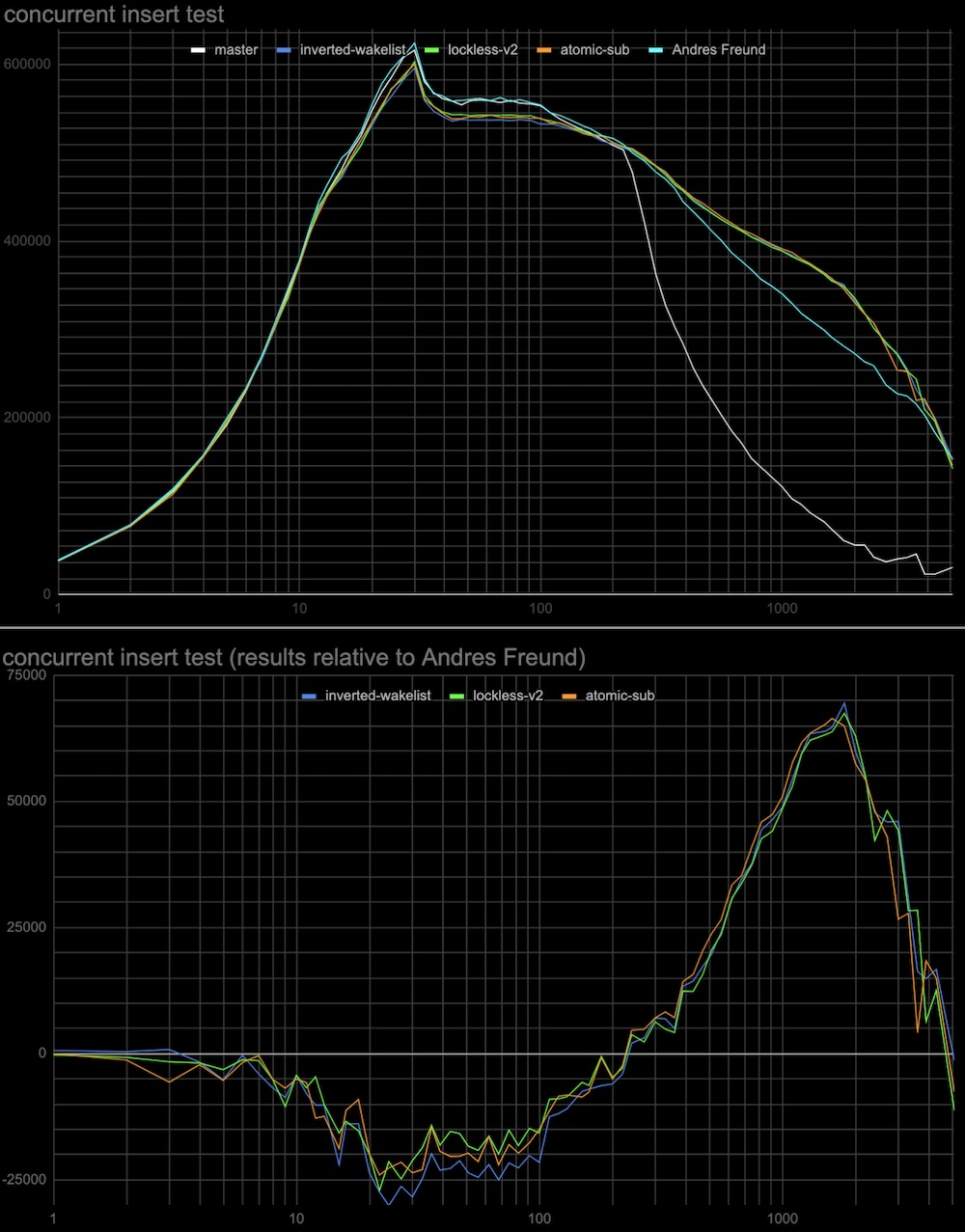
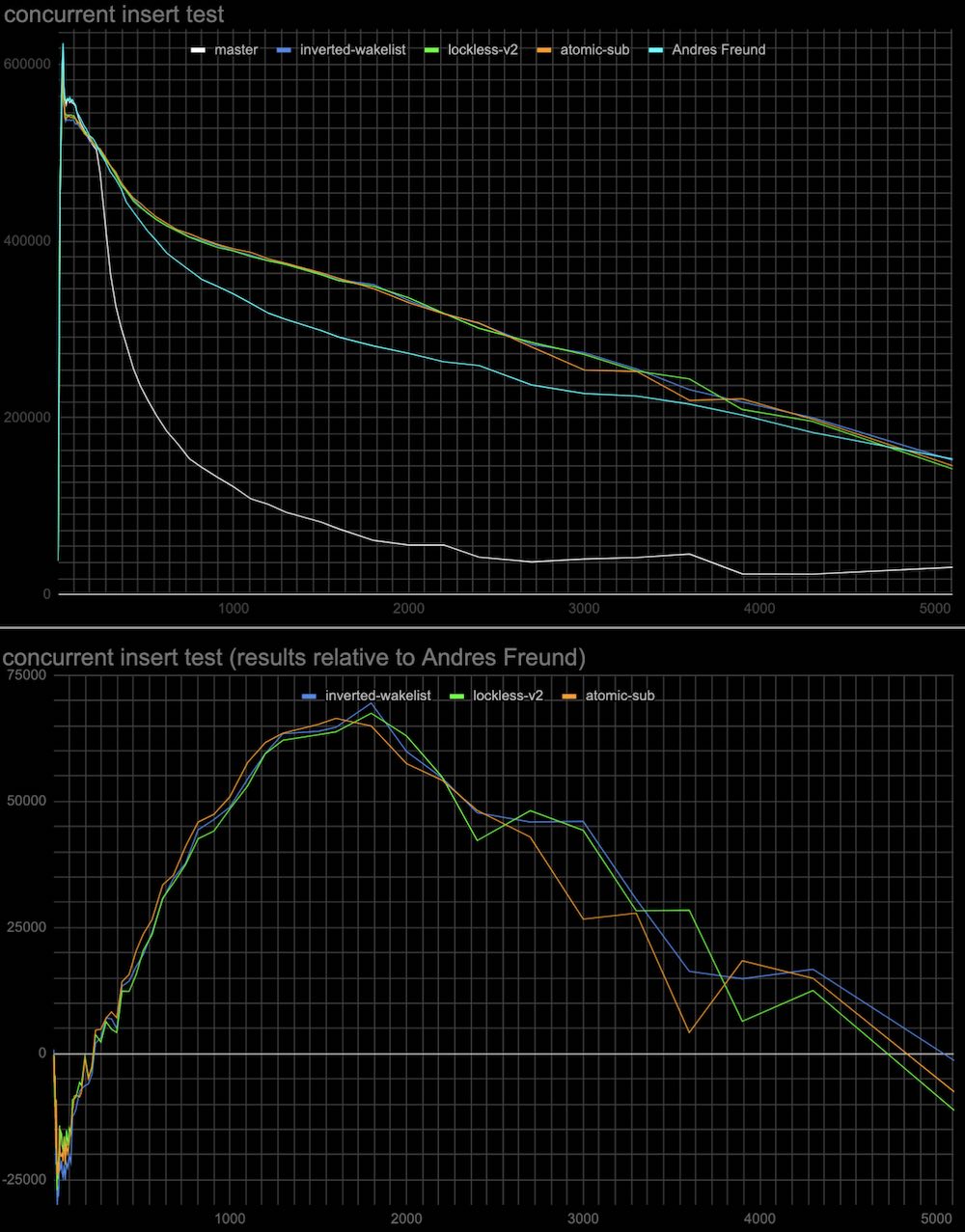
The results are attached (see atomic-sub-inverted-queue-*.jpg)
2. Whether sending wake signals in inverted order affects performance.
In patch v2 the most recent shared lockers taken are woken up first
(but anyway they all get wake signals at the same wake pass).
The patch (see attached Invert-wakeup-queue-order.patch) inverts the
wake queue of lockers so the last lockers come first to wake.
The results are attached to the same plot as the previous test (see
atomic-sub-inverted-queue-*.jpg)
It seems that 1 and 2 don't have a visible effect on performance.
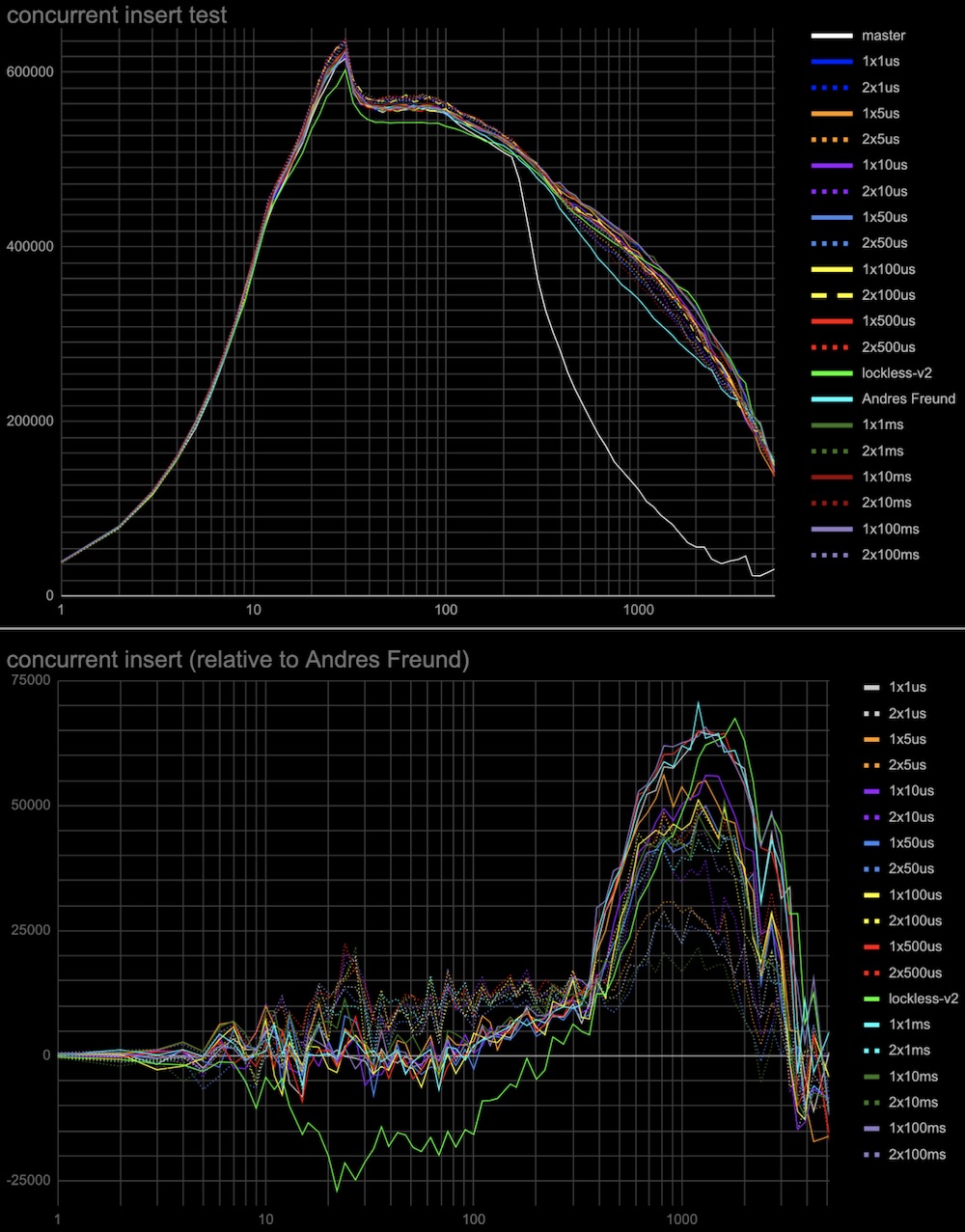
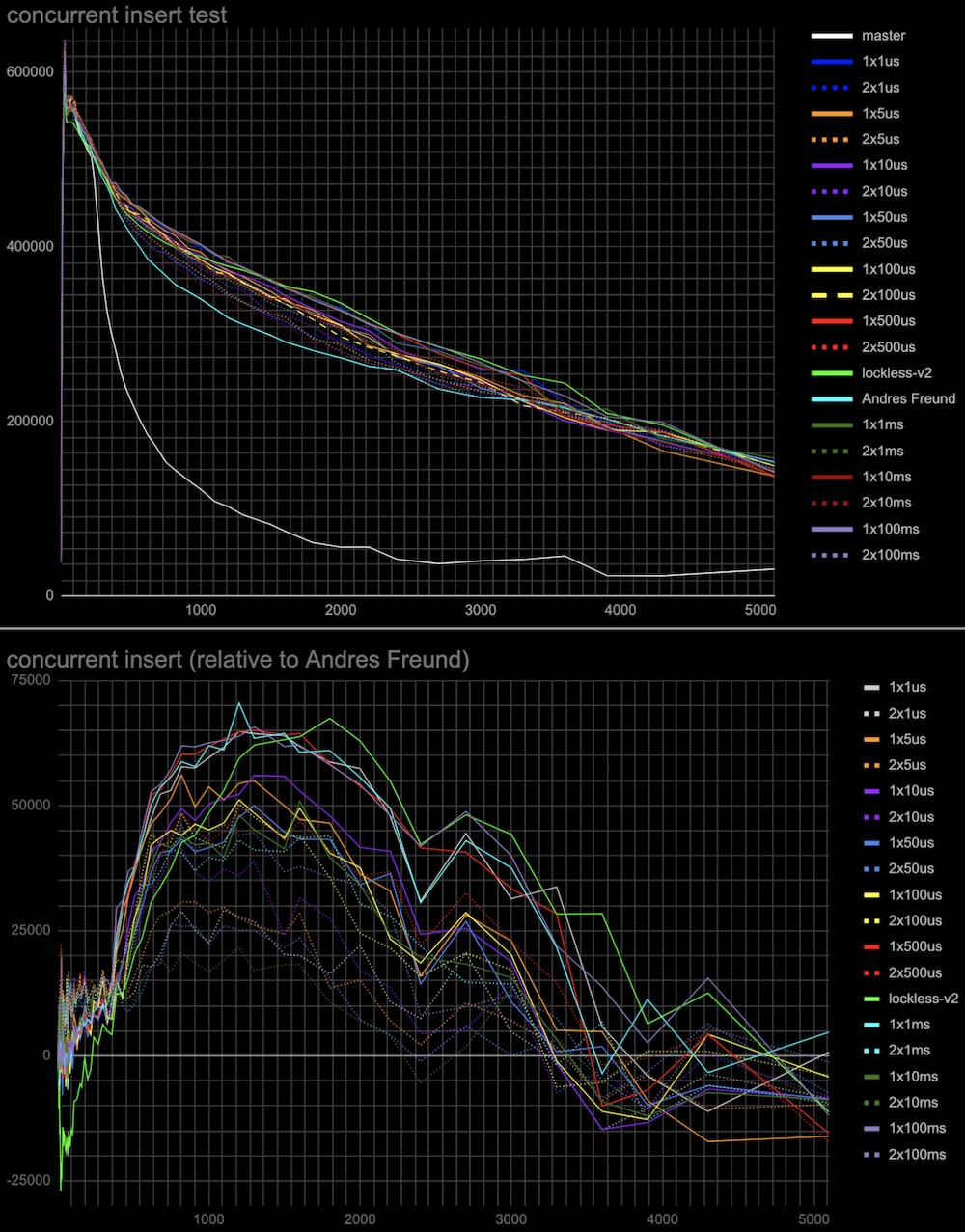
3. In the original master patch lock taking is tried twice separated
by the cheap spin delay before waiting on a more expensive semaphore.
This might explain why the proposed lockless queue patch [1] has a
little performance degradation around 20-30 connections. While we
don't need two-step lock-taking anymore I've tried to add it to see
whether it can improve performance. I've tried different initial
spinlock delays from 1 microsecond to 100 milliseconds and 1 or 2
retries (in case the lock is still busy in each case. (see the
attached: Extra-spin-waits-for-the-lock-to-be-freed-by-concurr.patch)
The results attached (see add-spin-delays-*.jpg) are interesting.
Indeed second attempt to take lock after the spin delay will increase
performance in any combinations of delays and retries. Also, the delay
and the number of retries act in opposite directions to the regions of
20-30 connections and 500+ connections. So we can choose to have a
more even performance gain at any number of connections (e.g. 2
retries x 500 microseconds) or better performance at 500+ connections
and the same performance as in Andres's patch around 20-30 connections
(e.g. 1 retry x 100 milliseconds).
4. I've also collected some statistics for the overall (sum for all
backends) number and duration of spin-delays in the same test in
Andres Freund's patch gathered using a slightly modified LWLOCK_STATS
mechanism.
conns / overall spin delays, s / overall number of spin delays /
average time of spin delay, ms
20 / 0 / 0 / 0
100 / 1.9 / 1177 / 1.6
200 / 21.9 / 14833 / 1.5
1000 / 12.9 / 11909 / 1.1
2000 / 3.2 / 2297 / 1.4
I've attached v3 of the lockless queue patch with added 2 retries x
500 microseconds spin delay which makes the test results superior to
the existing patch, leaves no performance degradation, and with steady
performance gain in the whole range of connections. But it's surely
worth discussing which parameters we want to have in the production
patch.
I'm also planning to do the same tests on an ARM server when the free
one comes available to me.
Thoughts?
Regards,
Pavel Borisov.
[1] https://www.postgresql.org/message-id/CALT9ZEF7q%2BSarz1MjrX-fM7OsoU7CK16%3DONoGCOkY3Efj%2BGrnw%40mail.gmail.com
[2] https://www.postgresql.org/message-id/CALT9ZEEz%2B%3DNepc5eti6x531q64Z6%2BDxtP3h-h_8O5HDdtkJcPw%40mail.gmail.com
[3] https://www.postgresql.org/message-id/20221031235114.ftjkife57zil7ryw%40awork3.anarazel.de
| Attachment | Content-Type | Size |
|---|---|---|
| atomic-sub-inverted-queue-log.jpg | image/jpeg | 273.3 KB |
| add-spin-delays-log.jpg | image/jpeg | 318.7 KB |
| atomic-sub-inverted-queue-linear.jpg | image/jpeg | 213.9 KB |
| add-spin-delays-linear.jpg | image/jpeg | 343.1 KB |
| v3-0001-Lockless-queue-of-LWLock-waiters.patch | application/octet-stream | 44.2 KB |
| Extra-spin-waits-for-the-lock-to-be-freed-by-concurr.patch | application/octet-stream | 2.3 KB |
| Invert-wakeup-queue-order.patch | application/octet-stream | 3.2 KB |
| atomic-sub-instead-of-CAS-for-shared-lockers-without.patch | application/octet-stream | 1.7 KB |
| From | Date | Subject | |
|---|---|---|---|
| Next Message | David Geier | 2022-11-11 12:01:15 | Optimize join selectivity estimation by not reading MCV stats for unique join attributes |
| Previous Message | Amit Kapila | 2022-11-11 11:37:35 | Re: Perform streaming logical transactions by background workers and parallel apply |
{kind=link}
{kind=link}
{kind=link}
{kind=link}