| From: | Yuya Watari <watari(dot)yuya(at)gmail(dot)com> |
|---|---|
| To: | David Rowley <dgrowleyml(at)gmail(dot)com> |
| Cc: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us>, pgsql-hackers(at)lists(dot)postgresql(dot)org |
| Subject: | Re: Making empty Bitmapsets always be NULL |
| Date: | 2023-06-27 09:11:14 |
| Message-ID: | CAJ2pMkZFv9PjoyTs+SEjY2utGdiB-0WG5uax15wjys8UpYMKBA@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
Hello,
Thank you for your reply and for creating the patch to measure planning times.
On Sat, Jun 24, 2023 at 1:15 PM David Rowley <dgrowleyml(at)gmail(dot)com> wrote:
> Thanks for benchmarking. It certainly looks like a win for larger
> sets. Would you be able to profile the 256 partition case to see
> where exactly master is so slow? (I'm surprised this patch improves
> performance that much.)
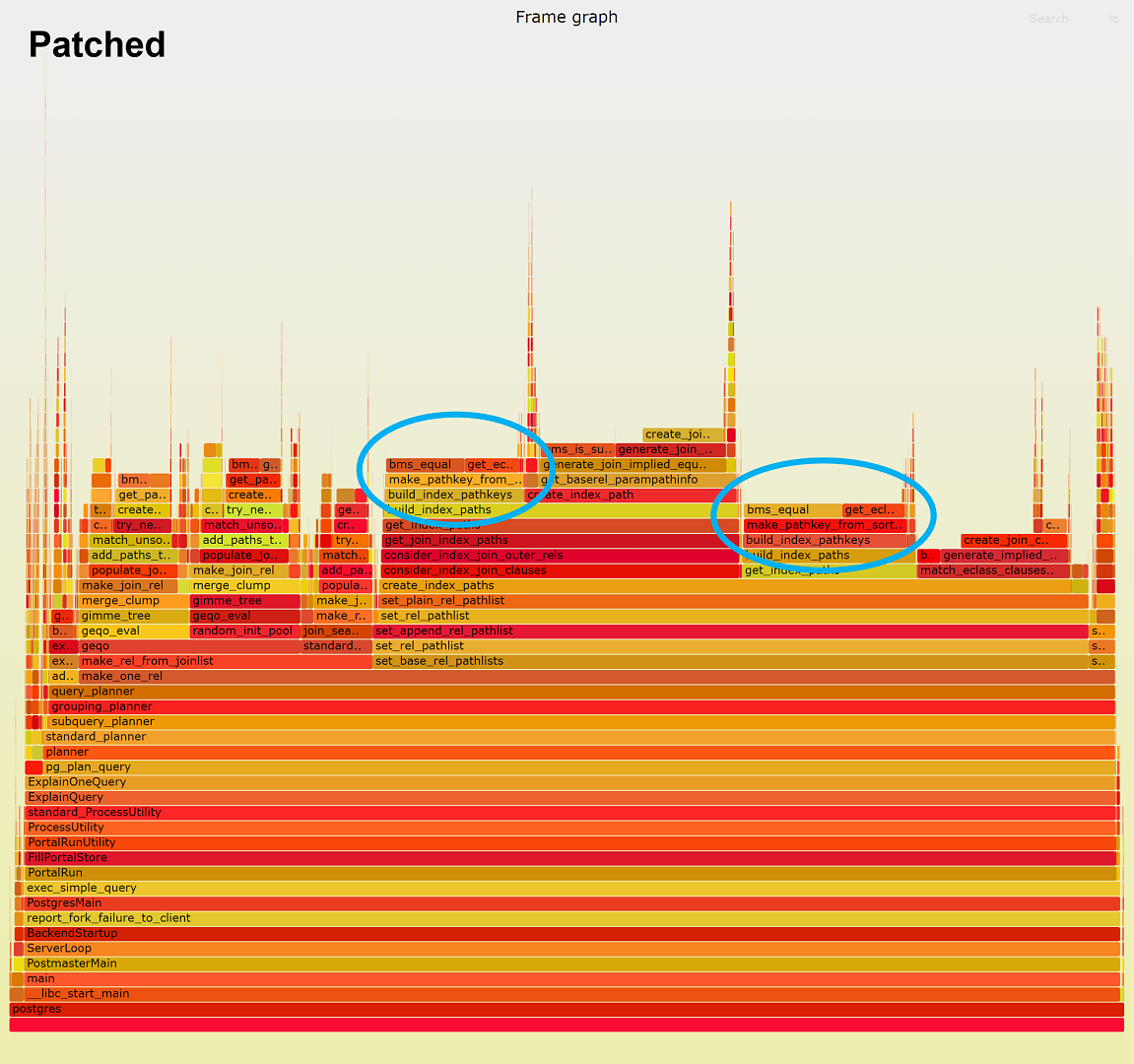
I have profiled the 256 partition case of the Join Order Benchmark
using the perf command. The attached figures are its frame graphs.
From these figures, we can see that bms_equal() function calls in blue
circles were heavy, and their performance improved after applying the
patch.
To investigate this further, I have created a patch
(profile-patch-for-*.txt) that profiles the bms_equal() function in
more detail. This patch
(1) prints what we are comparing by bms_equal, and
(2) measures the number of loops executed within bms_equal.
(1) is for debugging. (2) intends to see the effect of the
optimization to remove trailing zero words. The guarantee that the
last word is always non-zero enables us to immediately determine two
Bitmapsets having different nwords are not the same. When the patch
works effectively, the (2) will be much smaller than the total number
of the function calls. I will show the results as follows.
=== Master ===
[bms_equal] Comparing (b 335) and (b 35)
[bms_equal] Comparing (b 1085) and (b 61)
[bms_equal] Comparing (b 1208) and (b 86)
[bms_equal] Comparing (b 781) and (b 111)
[bms_equal] Comparing (b 361) and (b 135)
...
[bms_equal] Comparing (b 668) and (b 1773)
[bms_equal] Comparing (b 651) and (b 1781)
[bms_equal] Comparing (b 1191) and (b 1789)
[bms_equal] Comparing (b 771) and (b 1797)
[bms_equal] Total 3950748839 calls, 3944762037 loops executed
==============
=== Patched ===
[bms_equal] Comparing (b 335) and (b 35)
[bms_equal] Comparing (b 1085) and (b 61)
[bms_equal] Comparing (b 1208) and (b 86)
[bms_equal] Comparing (b 781) and (b 111)
[bms_equal] Comparing (b 361) and (b 135)
...
[bms_equal] Comparing (b 668) and (b 1773)
[bms_equal] Comparing (b 651) and (b 1781)
[bms_equal] Comparing (b 1191) and (b 1789)
[bms_equal] Comparing (b 771) and (b 1797)
[bms_equal] Total 3950748839 calls, 200215204 loops executed
===============
The above results reveal that the bms_equal() in this workload
compared two singleton Bitmapsets in most cases, and their members
were more than 64 apart. Therefore, we could have omitted 94.9% of
3,950,748,839 loops with the patch, whereas the percentage was only
0.2% in the master. This is why we obtained a significant performance
improvement and is evidence that the optimization of this patch worked
very well.
The attached figures show these bms_equal() function calls exist in
make_pathkey_from_sortinfo(). The actual location is
get_eclass_for_sort_expr(). I quote the code below.
=====
EquivalenceClass *
get_eclass_for_sort_expr(PlannerInfo *root,
Expr *expr,
List *opfamilies,
Oid opcintype,
Oid collation,
Index sortref,
Relids rel,
bool create_it)
{
...
foreach(lc1, root->eq_classes)
{
EquivalenceClass *cur_ec = (EquivalenceClass *) lfirst(lc1);
...
foreach(lc2, cur_ec->ec_members)
{
EquivalenceMember *cur_em = (EquivalenceMember *) lfirst(lc2);
/*
* Ignore child members unless they match the request.
*/
if (cur_em->em_is_child &&
!bms_equal(cur_em->em_relids, rel)) // <--- Here
continue;
...
}
}
...
}
=====
The bms_equal() is used to find an EquivalenceMember satisfying some
conditions. The above heavy loop was the bottleneck in the master.
This bottleneck is what I am trying to optimize in another thread [1]
with you. I hope the optimization in this thread will help [1]'s speed
up. (Looking at CFbot, I noticed that [1]'s patch does not compile due
to some compilation errors. I will send a fixed version soon.)
> I think it's also important to check we don't slow anything down for
> more normal-sized sets. The vast majority of sets will contain just a
> single word, so we should probably focus on making sure we're not
> slowing anything down for those.
I agree with you and thank you for sharing the results. I ran
installcheck with your patch. The result is as follows. The speedup
was 0.33%. At least in my environment, I did not observe any
regression with this test. So, the patch looks very good.
Master: 2.559648 seconds
Patched: 2.551116 seconds (0.33% faster)
--
Best regards,
Yuya Watari
| Attachment | Content-Type | Size |
|---|---|---|
| profile-patch-for-master.txt | text/plain | 2.1 KB |
| frame-graph-master.png | image/png | 474.3 KB |
| frame-graph-patched.png | image/png | 435.7 KB |
| profile-patch-for-patched.txt | text/plain | 2.1 KB |
| From | Date | Subject | |
|---|---|---|---|
| Next Message | David Rowley | 2023-06-27 09:19:26 | Add bump memory context type and use it for tuplesorts |
| Previous Message | Joel Jacobson | 2023-06-27 08:26:44 | Re: Do we want a hashset type? |
{kind=link}
{kind=link}