Re: Measuring replay lag
| From: | Thomas Munro <thomas(dot)munro(at)enterprisedb(dot)com> |
|---|---|
| To: | Simon Riggs <simon(at)2ndquadrant(dot)com> |
| Cc: | Michael Paquier <michael(dot)paquier(at)gmail(dot)com>, Fujii Masao <masao(dot)fujii(at)gmail(dot)com>, Peter Eisentraut <peter(dot)eisentraut(at)2ndquadrant(dot)com>, Masahiko Sawada <sawada(dot)mshk(at)gmail(dot)com>, Pg Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Measuring replay lag |
| Date: | 2017-02-21 21:38:36 |
| Message-ID: | CAEepm=0yus_FDXRuJ2SpJrL7yHhJG4c7OzwoUEWJ4=A+HSmZLw@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
On Tue, Feb 21, 2017 at 6:21 PM, Simon Riggs <simon(at)2ndquadrant(dot)com> wrote:
> And happier again, leading me to move to the next stage of review,
> focusing on the behaviour emerging from the design.
>
> So my current understanding is that this doesn't rely upon LSN
> arithmetic to measure lag, which is good. That means logical
> replication should "just work" and future mechanisms to filter
> physical WAL will also just work. This is important, so please comment
> if you see that isn't the case.
Yes, my understanding (based on
https://www.postgresql.org/message-id/f453caad-0396-1bdd-c5c1-5094371f4776@2ndquadrant.com
) is that this should in principal work for logical replication, it
just might show the same number in 2 or 3 of the lag columns because
of the way it reports LSNs.
However, I think a call like LagTrackerWrite(SendRqstPtr,
GetCurrentTimestamp()) needs to go into XLogSendLogical, to mirror
what happens in XLogSendPhysical. I'm not sure about that.
> I notice that LagTrackerRead() doesn't do anything to interpolate the
> time given, so at present any attempt to prune the lag sample buffer
> would result in falsely increasing the lag times reported. Which is
> probably the reason why you say "There may be better adaptive
> compaction algorithms." We need to look at this some more, an initial
> guess might be that we need to insert fewer samples as the buffer
> fills since the LagTrackerRead() algorithm is O(N) on number of
> samples and thus increasing the buffer itself isn't a great plan.
Interesting idea about interpolation. The lack of it didn't "result
in falsely increasing the lag times reported", it resulted in reported
lag staying static for a period of time even though we were falling
further behind. I finished up looking into fixing this with
interpolation. See below.
About adaptive sampling: This patch does in fact "insert fewer
samples once the buffer fills". Normally, the sender records a sample
every time it sends a message. Now imagine that the standby's
recovery is very slow and the buffer fills up. The sender starts
repeatedly overwriting the same buffer element because the write head
has crashed into the slow moving read head. Every time the standby
makes some progress and reports it, the read head finally advances
releasing some space, so the sender is able to advance to the next
element and record a new sample (and probably overwrite that one many
times). So effectively we reduce our sampling rate for all new
samples. We finish up with a sampling rate that is determined by the
rate of standby progress. I expect you can make something a bit
smoother and more sophisticated that starts lowering the sampling rate
sooner and perhaps thins out the pre-existing samples when the buffer
fills up, and I'm open to ideas, but my intuition is that it would be
complicated and no one would even notice the difference.
LagTrackerRead() is O(N) not in the total number of samples, but in
the number of samples whose LSN is <= the LSN in the reply message
we're processing. Given that the sender record samples as it sends
messages, and the standby sends replies on write/flush of those
messages, I think the N in question here will typically be a very
small number except in the case below called 'overwhelm.png' when the
WAL sender would be otherwise completely idle.
> It would be very nice to be able to say something like that the +/-
> confidence limits of the lag are no more than 50% of the lag time, so
> we have some idea of how accurate the value is at any point. We need
> to document the accuracy of the result, otherwise we'll be answering
> questions on that for some time. So lets think about that now.
The only source of inaccuracy I can think of right now is that if
XLogSendPhysical doesn't run very often, then we won't notice the
local flushed LSN moving until a bit later, and to the extent that
we're late noticing that, we could underestimate the lag numbers. But
actually it runs very frequently and is woken whenever WAL is flushed.
This gap could be closed by recording the system time in shared memory
whenever local WAL is flushed; as described in a large comment in the
patch, I figured this wasn't worth that.
> Given LagTrackerRead() is reading the 3 positions in order, it seems
> sensible to start reading the LAG_TRACKER_FLUSH_HEAD from the place
> you finished reading LAG_TRACKER_WRITE_HEAD etc.. Otherwise we end up
> doing way too much work with larger buffers.
Hmm. I was under the impression that we'd nearly always be eating a
very small number of samples with each reply message, since standbys
usually report progress frequently. But yeah, if the buffer is full
AND the standby is sending very infrequent replies because the primary
is idle, then perhaps we could try to figure out how to skip ahead
faster than one at a time.
> Which makes me think about the read more. The present design
> calculates everything on receipt of standby messages. I think we
> should simply record the last few messages and do the lag calculation
> when the values are later read, if indeed they are ever read. That
> would allow us a much better diagnostic view, at least. And it would
> allow you to show a) latest value, b) smoothed in various ways, or c)
> detail of last few messages for diagnostics. The latest value would be
> the default value in pg_stat_replication - I agree we shouldn't make
> that overly wide, so we'd need another function to access the details.
I think you need to record at least the system clock time and advance
the read heads up to the reported LSNs when you receive a reply. So
the amount of work you could defer to some later time would be almost
none; subtracting one time from another.
> What is critical is that we report stable values as lag increases.
> i.e. we need to iron out any usage cases so we don't have to fix them
> in PG11 and spend a year telling people "yeh, it does that" (like
> we've been doing for some time). So the diagnostics will help us
> investigate this patch over various use cases...
+1
> I think what we need to show some test results with the graph of lag
> over time for these cases:
> 1. steady state - pgbench on master, so we can see how that responds
> 2. blocked apply on standby - so we can see how the lag increases but
> also how the accuracy goes down as the lag increases and whether the
> reported value changes (depending upon algo)
> 3. burst mode - where we go from not moving to moving at high speed
> and then stop again quickly
> +other use cases you or others add
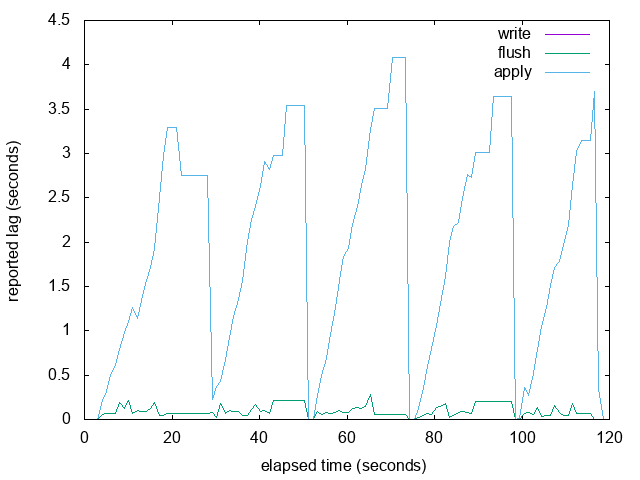
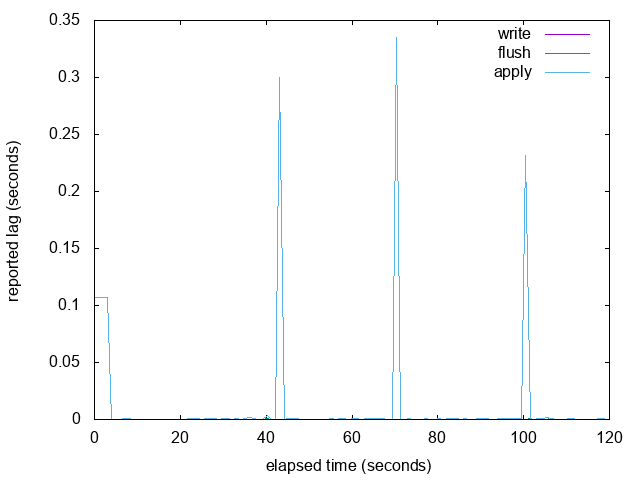
Good idea. Here are some graphs. This is from a primary/standby pair
running on my local development machine, so the times are low in the
good cases. For 1 and 2 I used pgbench TPCB-sort-of. For 3 I used a
loop that repeatedly dropped and created a huge table, sleeping in
between.
> Does the proposed algo work for these cases? What goes wrong with it?
> It's the examination of these downsides, if any, are the things we
> need to investigate now to allow this to get committed.
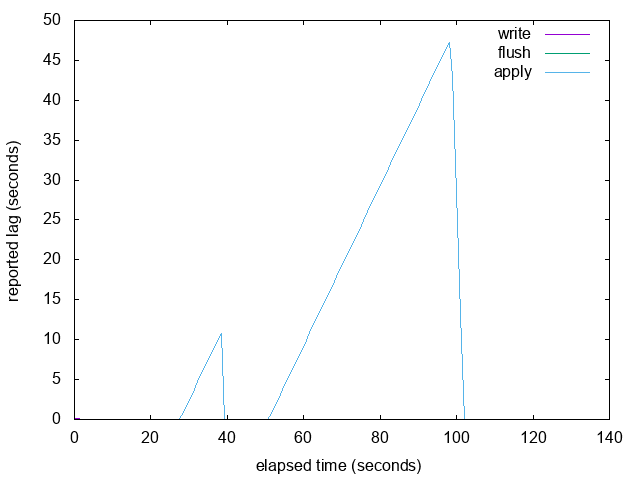
The main problem I discovered was with 2. If replay is paused, then
the reported LSN completely stops advancing, so replay_lag plateaus.
When you resume replay, it starts reporting LSNs advancing again and
suddenly discovers and reports a huge lag because it advances past the
next sample in the buffer.
I realised that you had suggested the solution to this problem
already: interpolation. I have added simple linear interpolation that
checks if there is a future LSN in the buffer, and if so it
interpolates linearly to synthesise the local flush time of the
reported LSN, which is somewhere between the last and next sample's
recorded local flush time. This seems to work well for the
apply-totally-stopped case.
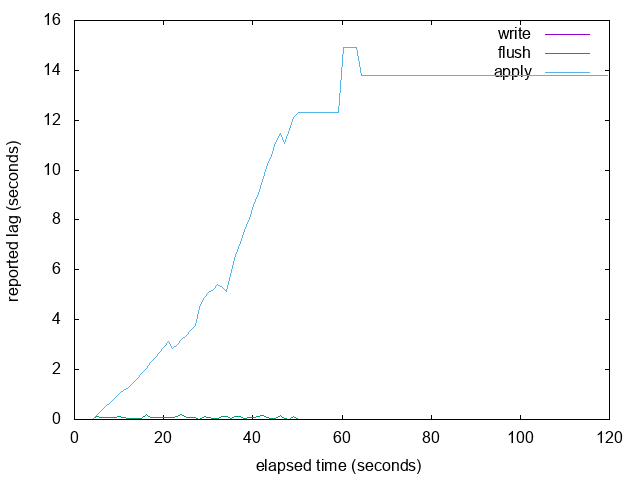
I added a fourth case 'overwhelm.png' which you might find
interesting. It's essentially like one 'burst' followed by a 100% ide
primary. The primary stops sending new WAL around 50 seconds in and
then there is no autovacuum, nothing happening at all. The standby
start is still replaying its backlog of WAL, but is sending back
replies only every 10 seconds (because no WAL arriving so no other
reason to send replies except status message timeout, which could be
lowered). So we see some big steps, and then we finally see it
flat-line around 60 seconds because there is still now new WAL so we
keep showing the last measured lag. If new WAL is flushed it will pop
back to 0ish, but until then its last known measurement is ~14
seconds, which I don't think is technically wrong.
> Some minor points on code...
> Why are things defined in walsender.c and not in .h?
Because they are module-private.
> Why is LAG_TRACKER_NUM_READ_HEADS not the same as NUM_SYNC_REP_WAIT_MODE?
> ...and other related constants shouldn't be redefined either.
Hmm. Ok, changed.
Please see new patch attached.
--
Thomas Munro
http://www.enterprisedb.com
| Attachment | Content-Type | Size |
|---|---|---|
| replication-lag-v3.patch | application/octet-stream | 19.4 KB |
|
image/png | 5.8 KB |
|
image/png | 7.8 KB |
|
image/png | 6.2 KB |
|
image/png | 6.6 KB |
In response to
- Re: Measuring replay lag at 2017-02-21 12:51:47 from Simon Riggs
Responses
- Re: Measuring replay lag at 2017-02-23 20:05:53 from Simon Riggs
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Alvaro Herrera | 2017-02-21 22:03:10 | Re: Speedup twophase transactions |
| Previous Message | Stephen Frost | 2017-02-21 20:05:19 | Re: pg_dump does not refresh matviews from extensions |