Group commit, revised
| From: | Peter Geoghegan <peter(at)2ndquadrant(dot)com> |
|---|---|
| To: | PG Hackers <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Group commit, revised |
| Date: | 2012-01-15 22:42:11 |
| Message-ID: | CAEYLb_V5Q8Zdjnkb4+30_dpD3NrgfoXhEurney3HsrCQsyDLWw@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
Attached is a patch that myself and Simon Riggs collaborated on. I
took the group commit patch that Simon posted to the list back in
November, and partially rewrote it. Here is that original thread:
http://archives.postgresql.org/pgsql-hackers/2011-11/msg00802.php
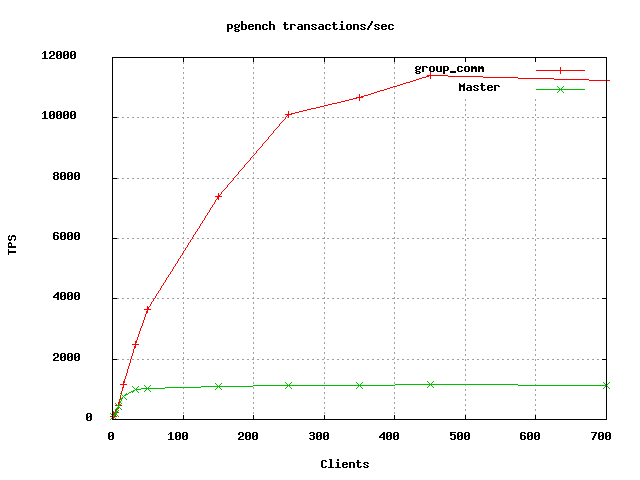
I've also attached the results of a pgbench-tools driven benchmark,
which are quite striking (Just the most relevant image - e-mail me
privately if you'd like a copy of the full report, as I don't want to
send a large PDF file to the list as a courtesy to others). Apart from
the obvious improvement in throughput, there is also a considerable
improvement in average and worst latency at all client counts.
To recap, the initial impetus to pursue this idea came from the
observation that with sync rep, we could get massive improvements in
the transactions-per-second throughput by simply adding clients. Greg
Smith performed a benchmark while in Amsterdam for the PgConf.EU
conference, which was discussed in a talk there. Over an
inter-continental connection from Amsterdam to his office in Baltimore
on the U.S. east coast, he saw TPS as reported by pgbench on what I
suppose was either an insert or update workload grow from a mere 10
TPS for a single connection to over 2000 TPS for about 300
connections. That was with the large, inherent latency imposed by
those sorts of distances (3822 miles/ 6150 km, about a 100ms ping time
on a decent connection). Quite obviously, as clients were added, the
server was able to batch increasing numbers of commits in each
confirmation message, resulting in this effect.
The main way that I've added value here is by refactoring and fixing
bugs. There were some tricky race conditions that caused the
regression tests to fail for that early draft patch, but there were a
few other small bugs too. There is an unprecedented latch pattern
introduced by this patch: Two processes (the WAL Writer and any given
connection backend) have a mutual dependency. Only one may sleep, in
which case the other is responsible for waking it. Much of the
difficulty in debugging this patch, and much of the complexity that
I've added, came from preventing both from simultaneously sleeping,
even in the face of various known failure modes like postmaster death.
If this happens, it does of course represent a denial-of-service, so
that's something that reviewers are going to want to heavily
scrutinise. I suppose that sync rep should be fine here, as it waits
on walsenders, but I haven't actually comprehensively tested the
patch, so there may be undiscovered unpleasant interactions with other
xlog related features. I can report that it passes the regression
tests successfully, and on an apparently consistently basis - I
battled with intermittent failures for a time.
Simon's original patch largely copied the syncrep.c code as an
expedient to prove the concept. Obviously this design was never
intended to get committed, and I've done some commonality and
variability analysis, refactoring to considerably slim down the new
groupcommit.c file by exposing some previously module-private
functions from syncrep.c .
I encourage others to reproduce my benchmark here. I attach a
pgbench-tools config. You can get the latest version of the tool at:
https://github.com/gregs1104/pgbench-tools
I also attach hdparm information for the disk that was used during
these benchmarks. Note that I have not disabled the write cache. It's
a Linux box, with ext4, running a recent kernel.
The benefits (and, admittedly, the controversies) of this patch go
beyond mere batching of commits: it also largely, though not entirely,
obviates the need for user backends to directly write/flush WAL, and
the WAL Writer may never sleep if it continually finds work to do -
wal_writer_delay is obsoleted, as are commit_siblings and
commit_delay. I suspect that they will not be missed. Of course, it
does all this to facilitate group commit itself. The group commit
feature does not have a GUC to control it, as this seems like
something that would be fairly pointless to turn off. FWIW, this is
currently the case for the recently introduced Maria DB group commit
implementation.
Auxiliary processes cannot use group commit. The changes made prevent
them from availing of commit_siblings/commit_delay parallelism,
because it doesn't exist anymore.
Group commit is sometimes throttled, which seems appropriate - if a
backend requests that the WAL Writer flush an LSN deemed too far from
the known flushed point, that request is rejected and the backend goes
through another path, where XLogWrite() is called. Currently the group
commit infrastructure decides that on the sole basis of there being a
volume of WAL that is equivalent in size to checkpoint_segments
between the two points. This is probably a fairly horrible heuristic,
not least since it overloads checkpoint_segments, but is of course
only a first-pass effort. Bright ideas are always welcome.
Thoughts?
--
Peter Geoghegan http://www.2ndQuadrant.com/
PostgreSQL Development, 24x7 Support, Training and Services
| Attachment | Content-Type | Size |
|---|---|---|
| hd_details.txt | text/plain | 3.1 KB |
|
image/png | 4.7 KB |
| group_commit_2012_01_15.patch.gz | application/x-gzip | 20.5 KB |
| config | application/octet-stream | 1.3 KB |
Responses
- Re: Group commit, revised at 2012-01-16 08:11:53 from Heikki Linnakangas
- Re: Group commit, revised at 2012-01-18 00:21:57 from Jim Nasby
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Thomas Munro | 2012-01-15 23:01:44 | SKIP LOCKED DATA |
| Previous Message | Ants Aasma | 2012-01-15 22:14:45 | Re: Patch: add timing of buffer I/O requests |