Re: pg_upgrade failing for 200+ million Large Objects
| From: | Robins Tharakan <tharakan(at)gmail(dot)com> |
|---|---|
| To: | Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> |
| Cc: | "Kumar, Sachin" <ssetiya(at)amazon(dot)com>, Nathan Bossart <nathandbossart(at)gmail(dot)com>, Jan Wieck <jan(at)wi3ck(dot)info>, Bruce Momjian <bruce(at)momjian(dot)us>, Zhihong Yu <zyu(at)yugabyte(dot)com>, Andrew Dunstan <andrew(at)dunslane(dot)net>, Magnus Hagander <magnus(at)hagander(dot)net>, Peter Eisentraut <peter(dot)eisentraut(at)enterprisedb(dot)com>, "pgsql-hackers(at)postgresql(dot)org" <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: pg_upgrade failing for 200+ million Large Objects |
| Date: | 2023-12-28 11:38:46 |
| Message-ID: | CAEP4nAxbrDM5b4g-+pPskuLmZWphZiuGGV7qpB7aAZ08ZMZSjw@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
On Thu, 28 Dec 2023 at 01:48, Tom Lane <tgl(at)sss(dot)pgh(dot)pa(dot)us> wrote:
> Robins Tharakan <tharakan(at)gmail(dot)com> writes:
> > Applying all 4 patches, I also see good performance improvement.
> > With more Large Objects, although pg_dump improved significantly,
> > pg_restore is now comfortably an order of magnitude faster.
>
> Yeah. The key thing here is that pg_dump can only parallelize
> the data transfer, while (with 0004) pg_restore can parallelize
> large object creation and owner-setting as well as data transfer.
> I don't see any simple way to improve that on the dump side,
> but I'm not sure we need to. Zillions of empty objects is not
> really the use case to worry about. I suspect that a more realistic
> case with moderate amounts of data in the blobs would make pg_dump
> look better.
>
Thanks for elaborating, and yes pg_dump times do reflect that
expectation.
The first test involved a fixed number (32k) of
Large Objects (LOs) with varying sizes - I chose that number
intentionally since this was being tested on a 32vCPU instance
and the patch employs 1k batches.
We again see that pg_restore is an order of magnitude faster.
LO Size (bytes) restore-HEAD restore-patched improvement (Nx)
1 24.182 1.4 17x
10 24.741 1.5 17x
100 24.574 1.6 15x
1,000 25.314 1.7 15x
10,000 25.644 1.7 15x
100,000 50.046 4.3 12x
1,000,000 281.549 30.0 9x
pg_dump also sees improvements. Really small sized LOs
see a decent ~20% improvement which grows considerably as LOs
get bigger (beyond ~10-100kb).
LO Size (bytes) dump-HEAD dump-patched improvement (%)
1 12.9 10.7 18%
10 12.9 10.4 19%
100 12.8 10.3 20%
1,000 13.0 10.3 21%
10,000 14.2 10.3 27%
100,000 32.8 11.5 65%
1,000,000 211.8 23.6 89%
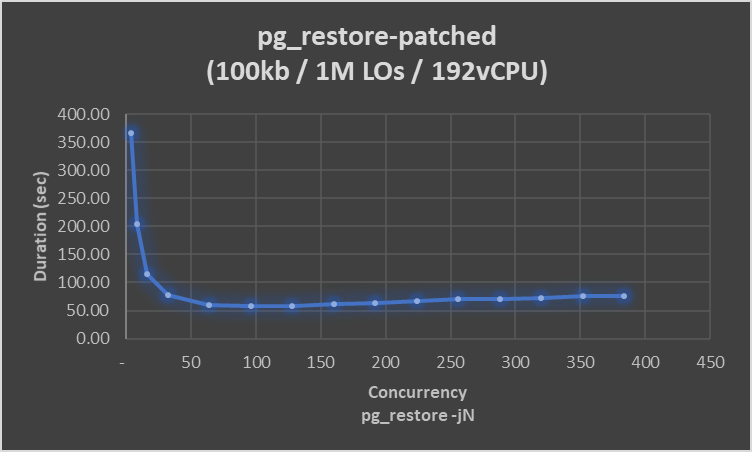
To test pg_restore scaling, 1 Million LOs (100kb each)
were created and pg_restore times tested for increasing
concurrency (on a 192vCPU instance). We see major speedup
upto -j64 and the best time was at -j96, after which
performance decreases slowly - see attached image.
Concurrency pg_restore-patched
384 75.87
352 75.63
320 72.11
288 70.05
256 70.98
224 66.98
192 63.04
160 61.37
128 58.82
96 58.55
64 60.46
32 77.29
16 115.51
8 203.48
4 366.33
Test details:
- Command used to generate SQL - create 1k LOs of 1kb each
- echo "SELECT lo_from_bytea(0, '\x` printf 'ff%.0s' {1..1000}`') FROM
generate_series(1,1000);" > /tmp/tempdel
- Verify the LO size: select pg_column_size(lo_get(oid));
- Only GUC changed: max_connections=1000 (for the last test)
-
Robins Tharakan
Amazon Web Services
| Attachment | Content-Type | Size |
|---|---|---|
|
image/png | 35.6 KB |
In response to
- Re: pg_upgrade failing for 200+ million Large Objects at 2023-12-27 15:18:21 from Tom Lane
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Bharath Rupireddy | 2023-12-28 11:56:19 | Re: Switching XLog source from archive to streaming when primary available |
| Previous Message | Alexander Korotkov | 2023-12-28 11:29:05 | Re: POC: GROUP BY optimization |