Re: index prefetching
| From: | Alexandre Felipe <o(dot)alexandre(dot)felipe(at)gmail(dot)com> |
|---|---|
| To: | Tomas Vondra <tomas(at)vondra(dot)me> |
| Cc: | Andres Freund <andres(at)anarazel(dot)de>, Peter Geoghegan <pg(at)bowt(dot)ie>, Thomas Munro <thomas(dot)munro(at)gmail(dot)com>, Nazir Bilal Yavuz <byavuz81(at)gmail(dot)com>, Robert Haas <robertmhaas(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com>, PostgreSQL Hackers <pgsql-hackers(at)lists(dot)postgresql(dot)org>, Georgios <gkokolatos(at)protonmail(dot)com>, Konstantin Knizhnik <knizhnik(at)garret(dot)ru>, Dilip Kumar <dilipbalaut(at)gmail(dot)com> |
| Subject: | Re: index prefetching |
| Date: | 2026-02-17 03:22:41 |
| Message-ID: | CAE8JnxOacD1bKB-rKeSC1ThHKevuYa5NtU7ksNQVqxiTgar_rg@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
>
> Can you share how is the system / Postgres configured? It's a good
> practice to provide all the information others might need to reproduce
> your results.
>
All defaults form initdb this time.
> In particular, what is shared_buffers set to? Are you still using
> io_method=worker? With how many io workers?
>
The command line argument --workers 0 is passed to
max_parallel_workers_per_gather.
What's the distance in those cases? You may need to add some logging to
> read_stream to show that. If the distance is not ~1.0 then it's not the
> issue described by Andres, I think.
>
Andres theory is correct, how likely are these scenarios?
I created a script to produce miss/hit patterns, and add a function to the
pg_buffercache extension to get the distances, not nice, but better than
printing and parsing logs..
python3 test_distance_oscillation.py --samples 10 --pages 2000 --pattern
"$p";
Table: 2000 pages, samples: 3
Pattern: h{400}(mh)+ -> hhhhhhhhhhhhhhhhhhhh...
Cache: 1200 hits, 800 misses
Distance plot saved to: pattern-h{400}(mh)+.png
Prefetch OFF: 131.1ms ± 17.8ms (n=3)
Prefetch ON: 137.4ms ± 20.8ms (n=3)
Effect: +4.8% (slower)
--- Pattern: h{400}m(mh)+ ---
Creating 2000 pages...
Table: 2000 pages, samples: 3
Pattern: h{400}m(mh)+ -> hhhhhhhhhhhhhhhhhhhh...
Cache: 1199 hits, 801 misses
Distance plot saved to: pattern-h{400}m(mh)+.png
Prefetch OFF: 562.6ms ± 208.0ms (n=3)
Prefetch ON: 423.0ms ± 99.8ms (n=3)
Effect: -24.8% (faster)
Two experiments, one with 800 misses, one with 801 misses with very
different results.
But this is an unlikely situation in practice, because a single extra miss
already disturbs the cycle.
Attached I have
- h{400}m(mh)+: i.e. 400 hits, two misses and alternates hit/miss
saturates above 80
- h{400}(mh)+: i.e. 400 hits, followed by alternated miss/hit, fixed at 1
- h{400}(mh){300}m(mh)+: 400 hits, 400 alternating miss/hit one extra
miss, followed by alternating hit/miss. Is stuck at 1 until, but unlocks on
the extra miss
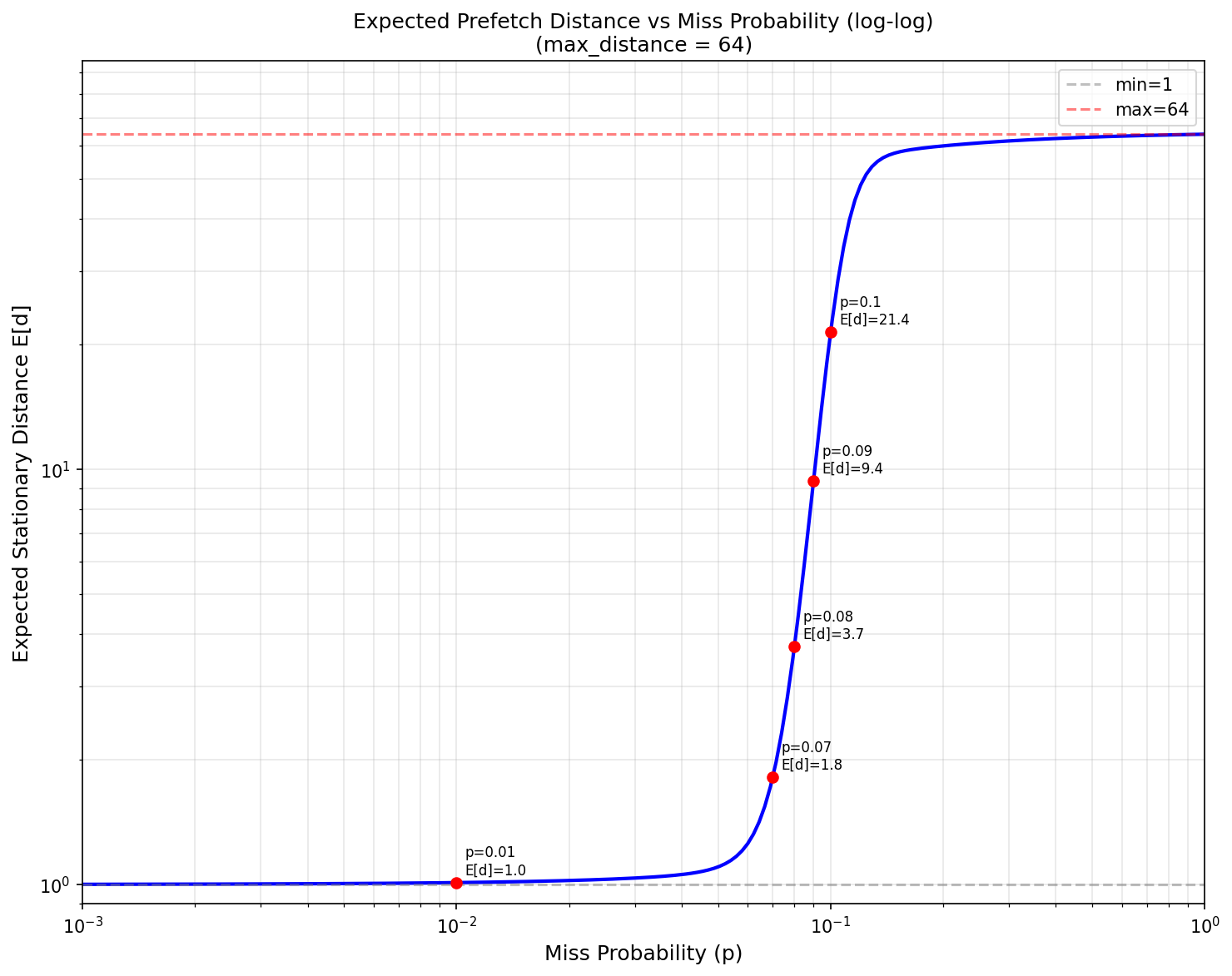
If we assume that the buffers have independent miss probability, we have a
markov chain and we can compute the average, I did that and plotted the
expected-distances, attached here too. Under this model, the distance
should be a straight line so that the number of prefetched buffers stay
constant.
> There are other ways to look at issued IOs, either using iostat, or
> tools like perf-trace.
>
Noted.
> What does "reasonable to prefetch" mean in practice, and how you
> determine it at runtime, before initiating the buffer prefetch?
>
Probably what you already do, set a limit, e.g. don't exceed the maximum
number of pinned buffers.
Not at the moment, AFAIK. And for most index-only scans that would not
> really work anyway, because those need to produce sorted output.
>
Yes, return in order, but if we have a long scan, what can be done is to
have a buffer of rows. Say the buffers come in the sequence 1,2,4,5,3
process 1, output 1
process 2, output 2
3 not there, process 4
3 not there, process 5
process 3, output 3, 4, 5
If we read rows of 1kB and unpin buffers of 8kB that is memory savings
that can be used elsewhere, or if you like prefetch with a higher distance.
I imagine you would want this on a separate patch, as this one seems to be
very mature already.
Regards,
Alexandre
| Attachment | Content-Type | Size |
|---|---|---|
| distance-tracking.txt | text/plain | 4.7 KB |
| test_distance_oscillation.py | text/x-python-script | 8.1 KB |
+.png)
|
image/png | 43.6 KB |
+.png)
|
image/png | 45.4 KB |
{300}m(mh)+.png)
|
image/png | 48.4 KB |
| expected-distances.png | image/png | 83.8 KB |
{kind=link}
In response to
- Re: index prefetching at 2026-02-16 23:33:21 from Tomas Vondra
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | shveta malik | 2026-02-17 03:42:55 | Re: Improve pg_sync_replication_slots() to wait for primary to advance |
| Previous Message | Thomas Munro | 2026-02-17 02:38:05 | Re: Questionable description about character sets |