| From: | Alexandre Felipe <o(dot)alexandre(dot)felipe(at)gmail(dot)com> |
|---|---|
| To: | Andres Freund <andres(at)anarazel(dot)de> |
| Cc: | Tomas Vondra <tomas(at)vondra(dot)me>, Peter Geoghegan <pg(at)bowt(dot)ie>, Thomas Munro <thomas(dot)munro(at)gmail(dot)com>, Nazir Bilal Yavuz <byavuz81(at)gmail(dot)com>, Robert Haas <robertmhaas(at)gmail(dot)com>, Melanie Plageman <melanieplageman(at)gmail(dot)com>, PostgreSQL Hackers <pgsql-hackers(at)lists(dot)postgresql(dot)org>, Georgios <gkokolatos(at)protonmail(dot)com>, Konstantin Knizhnik <knizhnik(at)garret(dot)ru>, Dilip Kumar <dilipbalaut(at)gmail(dot)com> |
| Subject: | Re: index prefetching |
| Date: | 2026-02-16 23:05:26 |
| Message-ID: | CAE8JnxNmKP+iAhfRwt9C8BTHK1KYBUBZLQav5=1wudEzSFmMSg@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
Hi guys,
There seems to be some very interesting stuff here, I have to try to
catch up with your analysis Andres.
In the meantime.
I am sharing the results I have got on a well behaved Linux system.
No sophisticated algorithm here but evicting OS cache helps to verify the
benefit of prefetching at a much smaller scale, and I think this is useful
% gcc drop_cache.c -o drop_cache;
% sudo chown root:root drop_cache;
% sudo chmod 4755 drop_cache;
I was executing like this
python3 .../run_regression_test.py --port 5433 --iterations 10 \
--columns sequential,random --workers 0 --evict os,off \
--payload-size 50 \
--rows 10000 \
--reset \
--ntables 5
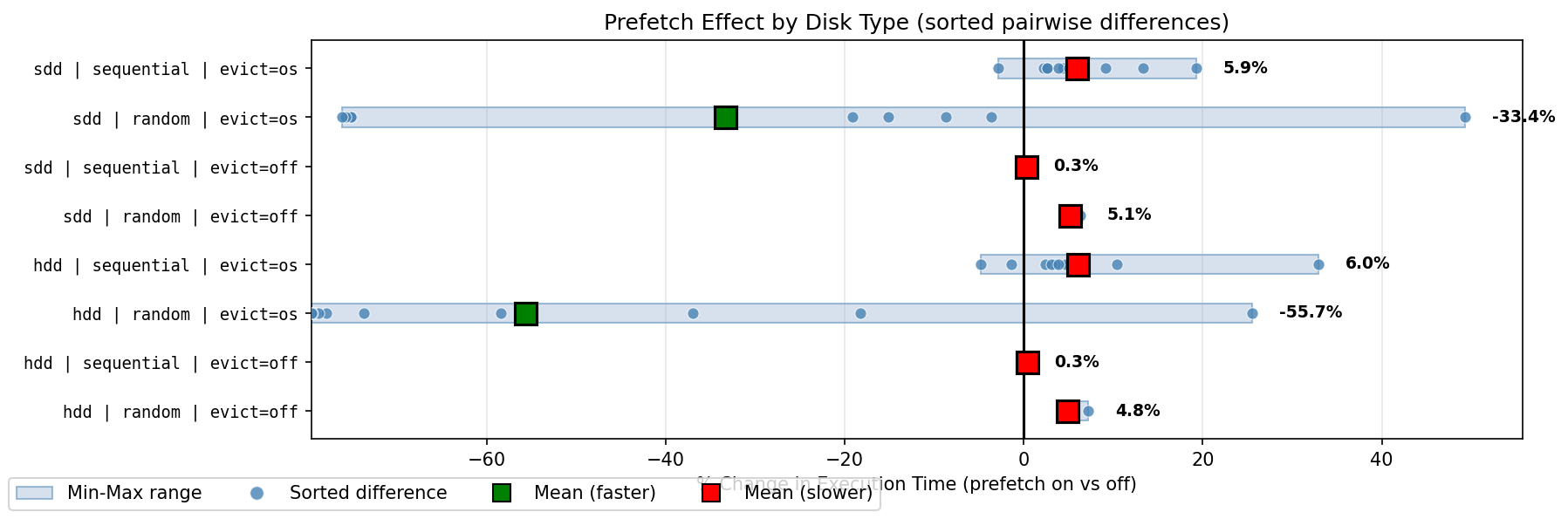
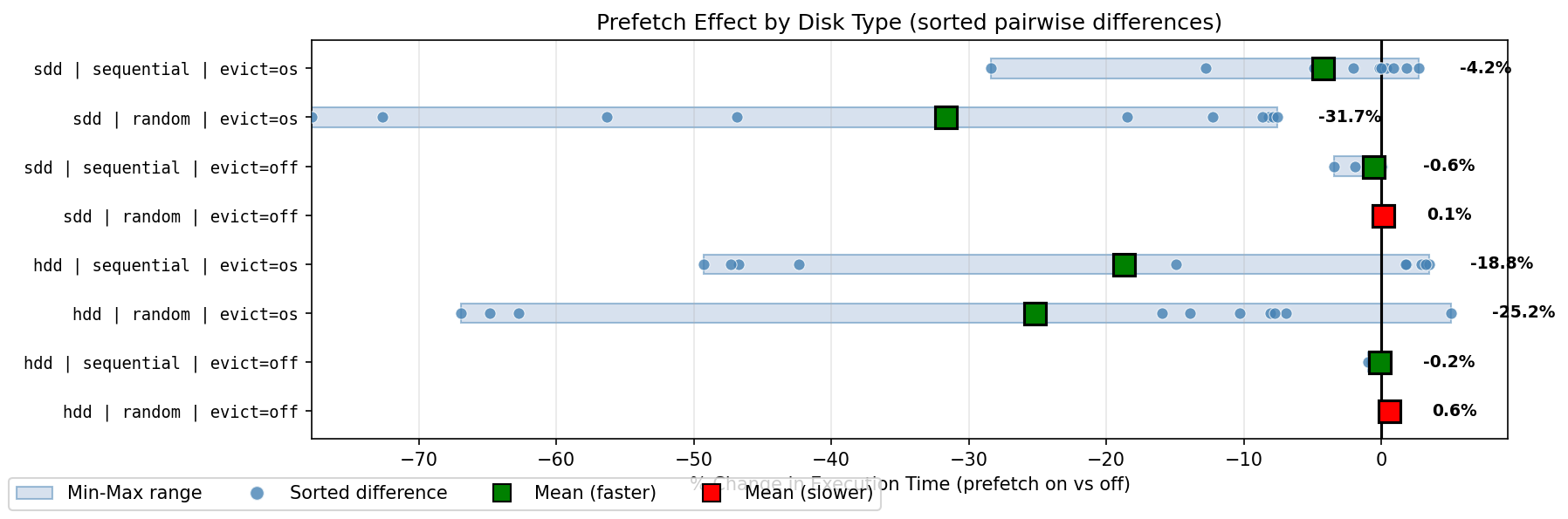
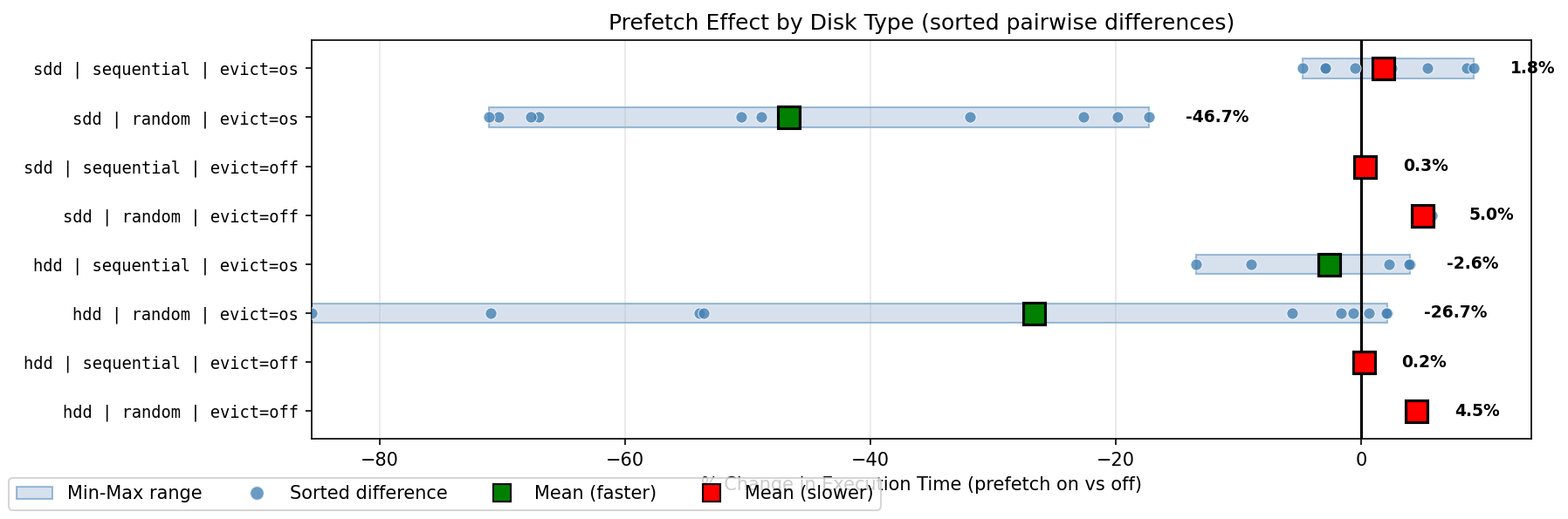
1 table: significant benefit with HDD cold, SSD random cold access.
5 tables: significant benefit for random cold access. Somewhat detrimental
for sequential cold access, and random hot access.
10 tables: significant benefit for random cold access. Slightly better than
5 tables for cold sequential access, and somewhat detrimental for random
hot access.
These results are hard to explain, but maybe Andres has the answer:
> I think this specific issue is a bit different, because today you get
> drastically different behaviour if you have
>
> a) [miss, (miss, hit)+]
> vs
> b) [(miss, hit)+]
Tomas said
> I think a "proper" solution would require some sort of cost model for
> the I/O part, so that we can schedule the I/Os just so that the I/O
> completes right before we actually need the page.
I dare to ask
Why not use this on a feedback loop?
while (!current_buffer.ready && reasonable to prefetch) {
fetch next index tuple.
if necessary prefetch one more buffer
}
I also dare to ask
Is it possible to skip an unavailable buffer and gain time processing the
rows that will be needed afterwards?
This could also help by releasing buffers more quickly if they need to be
recycled.
Regards,
Alexandre
| Attachment | Content-Type | Size |
|---|---|---|
| drop_cache.c | application/octet-stream | 884 bytes |
| run_regression_test.py | text/x-python-script | 9.9 KB |
| 5tables.png | image/png | 91.7 KB |
| 1table.png | image/png | 93.0 KB |
| 10tables.png | image/png | 90.1 KB |
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Michael Paquier | 2026-02-16 23:19:45 | Re: generating function default settings from pg_proc.dat |
| Previous Message | Sami Imseih | 2026-02-16 22:42:50 | Re: Flush some statistics within running transactions |
{kind=link}
{kind=link}
{kind=link}