Re: New IndexAM API controlling index vacuum strategies
| From: | Masahiko Sawada <sawada(dot)mshk(at)gmail(dot)com> |
|---|---|
| To: | Peter Geoghegan <pg(at)bowt(dot)ie> |
| Cc: | PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: New IndexAM API controlling index vacuum strategies |
| Date: | 2020-12-29 06:18:55 |
| Message-ID: | CAD21AoDS_J4NEPu6J41+EhE4PO_T+Hs-MjvROBOc8LKxFeui8g@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
On Mon, Dec 28, 2020 at 4:42 PM Peter Geoghegan <pg(at)bowt(dot)ie> wrote:
>
> On Sun, Dec 27, 2020 at 10:55 PM Masahiko Sawada <sawada(dot)mshk(at)gmail(dot)com> wrote:
> > > As you said, the next question must be: How do we teach lazy vacuum to
> > > not do what gets requested by amvacuumcleanup() when it cannot respect
> > > the wishes of one individual indexes, for example when the
> > > accumulation of LP_DEAD items in the heap becomes a big problem in
> > > itself? That really could be the thing that forces full heap
> > > vacuuming, even with several indexes.
> >
> > You mean requested by amvacuumstreategy(), not by amvacuumcleanup()? I
> > think amvacuumstrategy() affects only ambulkdelete(). But when all
> > ambulkdelete() were skipped by the requests by index AMs we might want
> > to skip amvacuumcleanup() as well.
>
> No, I was asking about how we should decide to do a real VACUUM even
> (a real ambulkdelete() call) when no index asks for it because
> bottom-up deletion works very well in every index. Clearly we will
> need to eventually remove remaining LP_DEAD items from the heap at
> some point if nothing else happens -- eventually LP_DEAD items in the
> heap alone will force a traditional heap vacuum (which will still have
> to go through indexes that have not grown, just to be safe/avoid
> recycling a TID that's still in the index).
>
> Postgres heap fillfactor is 100 by default, though I believe it's 90
> in another well known DB system. If you set Postgres heap fill factor
> to 90 you can fit a little over 200 LP_DEAD items in the "extra space"
> left behind in each heap page after initial bulk loading/INSERTs take
> place that respect our lower fill factor setting. This is about 4x the
> number of initial heap tuples in the pgbench_accounts table -- it's
> quite a lot!
>
> If we pessimistically assume that all updates are non-HOT updates,
> we'll still usually have enough space for each logical row to get
> updated several times before the heap page "overflows". Even when
> there is significant skew in the UPDATEs, the skew is not noticeable
> at the level of individual heap pages. We have a surprisingly large
> general capacity to temporarily "absorb" extra garbage LP_DEAD items
> in heap pages this way. Nobody really cared about this extra capacity
> very much before now, because it did not help with the big problem of
> index bloat that you naturally see with this workload. But that big
> problem may go away soon, and so this extra capacity may become
> important at the same time.
>
> I think that it could make sense for lazy_scan_heap() to maintain
> statistics about the number of LP_DEAD items remaining in each heap
> page (just local stack variables). From there, it can pass the
> statistics to the choose_vacuum_strategy() function from your patch.
> Perhaps choose_vacuum_strategy() will notice that the heap page with
> the most LP_DEAD items encountered within lazy_scan_heap() (among
> those encountered so far in the event of multiple index passes) has
> too many LP_DEAD items -- this indicates that there is a danger that
> some heap pages will start to "overflow" soon, which is now a problem
> that lazy_scan_heap() must think about. Maybe if the "extra space"
> left by applying heap fill factor (with settings below 100) is
> insufficient to fit perhaps 2/3 of the LP_DEAD items needed on the
> heap page that has the most LP_DEAD items (among all heap pages), we
> stop caring about what amvacuumstrategy()/the indexes say. So we do
> the right thing for the heap pages, while still mostly avoiding index
> vacuuming and the final heap pass.
Agreed. I like the idea that we calculate how many LP_DEAD items we
can absorb based on the extra space left by applying the fill factor.
Since there is a limit on the maximum number of line pointers in a
heap page we might need to consider that limit when calculation.
From another point of view, given the maximum number of heap tuple in
one 8kb heap page (MaxHeapTuplesPerPage) is 291, I think how bad to
store LP_DEAD items in a heap page vary depending on the tuple size.
For example, suppose the tuple size is 200 we can store 40 tuples into
one heap page if there is no LP_DEAD item at all. Even if there are
150 LP_DEAD items on the page, we still are able to store 37 tuples
because we still can have 141 line pointers at most, which is enough
number to store the maximum number of heap tuples when there are no
LP_DEAD items, and we have (8192 - (4 * 150)) bytes space to store
tuples (with line pointers). That is, we can think that having 150
LP_DEAD items end up causing an overflow of 3 tuples. On the other
hand, suppose the tuple size is 40 we can store 204 tuples into one
heap page if there is no LP_DEAD item at all. If there are 150 LP_DEAD
items on the page, we are able to store 141 tuples. That is, having
150 LP_DEAD items end up causing an overflow of 63 tuples. I think
the impact on the table bloat by absorbing LP_DEAD items is larger in
the latter case.
The larger the tuple size, the more LP_DEAD items can be absorbed in a
heap page with less bad effect. Considering 32 bytes tuple, the
minimum heap tuples size including the tuple header, absorbing
approximately up to 70 LP_DEAD items would not affect much in terms of
bloat. In other words, if a heap page has more than 70 LP_DEAD items,
absorbing LP_DEAD items may become a problem of the table bloat. This
threshold of 70 LP_DEAD items is a conservative value and probably
would be a lower bound. If the tuple size is larger, we may be able to
absorb more LP_DEAD items.
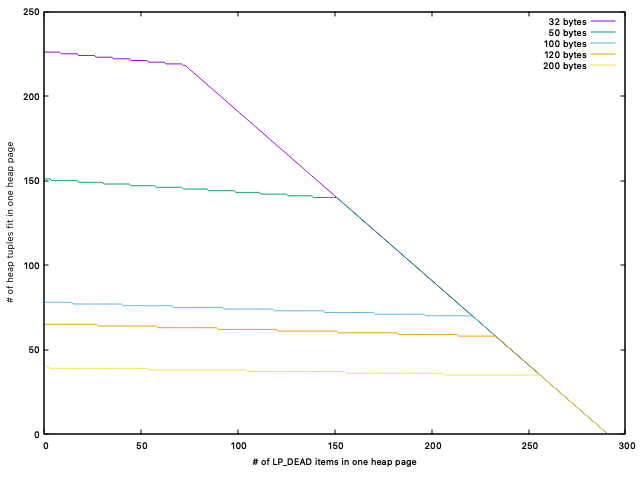
FYI I've attached a graph showing how the number of LP_DEAD items on
one heap page affects the maximum number of heap tuples on the same
heap page. The X-axis is the number of LP_DEAD items in one heap page
and the Y-axis is the number of heap tuples that can be stored on the
page. The lines in the graph are heap tuple size respectively. For
example, in pgbench workload, since the tuple size is about 120 bytes
the page bloat accelerates if we leave more than about 230 LP_DEAD
items in a heap page.
>
> I experimented with this today, and I think that it is a good way to
> do it. I like the idea of choose_vacuum_strategy() understanding that
> heap pages that are subject to many non-HOT updates have a "natural
> extra capacity for LP_DEAD items" that it must care about directly (at
> least with non-default heap fill factor settings). My early testing
> shows that it will often take a surprisingly long time for the most
> heavily updated heap page to have more than about 100 LP_DEAD items.
Agreed.
>
> > > I will need to experiment in order to improve my understanding of how
> > > to make this cooperate with bottom-up index deletion. But that's
> > > mostly just a question for my patch (and a relatively easy one).
> >
> > Yeah, I think we might need something like statistics about garbage
> > per index so that individual index can make a different decision based
> > on their status. For example, a btree index might want to skip
> > ambulkdelete() if it has a few dead index tuples in its leaf pages. It
> > could be on stats collector or on btree's meta page.
>
> Right. I think that even a very conservative approach could work well.
> For example, maybe we teach nbtree's amvacuumstrategy() routine to ask
> to do a real ambulkdelete(), except in the extreme case where the
> index is *exactly* the same size as it was after the last VACUUM.
> This will happen regularly with bottom-up index deletion. Maybe that
> approach is a bit too conservative, though.
Agreed.
Regards,
--
Masahiko Sawada
EnterpriseDB: https://www.enterprisedb.com/
| Attachment | Content-Type | Size |
|---|---|---|
|
image/png | 23.3 KB |
In response to
- Re: New IndexAM API controlling index vacuum strategies at 2020-12-28 07:41:44 from Peter Geoghegan
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Masahiko Sawada | 2020-12-29 06:25:55 | Re: New IndexAM API controlling index vacuum strategies |
| Previous Message | Peter Geoghegan | 2020-12-29 05:49:58 | Re: HOT chain bug in latestRemovedXid calculation |