Re: Block level parallel vacuum WIP
| From: | Masahiko Sawada <sawada(dot)mshk(at)gmail(dot)com> |
|---|---|
| To: | David Steele <david(at)pgmasters(dot)net> |
| Cc: | Robert Haas <robertmhaas(at)gmail(dot)com>, Claudio Freire <klaussfreire(at)gmail(dot)com>, Simon Riggs <simon(at)2ndquadrant(dot)com>, Amit Kapila <amit(dot)kapila16(at)gmail(dot)com>, Michael Paquier <michael(dot)paquier(at)gmail(dot)com>, Pavan Deolasee <pavan(dot)deolasee(at)gmail(dot)com>, PostgreSQL-development <pgsql-hackers(at)postgresql(dot)org> |
| Subject: | Re: Block level parallel vacuum WIP |
| Date: | 2017-08-15 01:13:38 |
| Message-ID: | CAD21AoAXmbFQDTDm=AiV95C6NhsM8Hh2zEWhR7CsrB5Ofyd1NA@mail.gmail.com |
| Views: | Whole Thread | Raw Message | Download mbox | Resend email |
| Thread: | |
| Lists: | pgsql-hackers |
On Wed, Jul 26, 2017 at 5:38 PM, Masahiko Sawada <sawada(dot)mshk(at)gmail(dot)com> wrote:
> On Sun, Mar 5, 2017 at 4:09 PM, Masahiko Sawada <sawada(dot)mshk(at)gmail(dot)com> wrote:
>> On Sun, Mar 5, 2017 at 12:14 PM, David Steele <david(at)pgmasters(dot)net> wrote:
>>> On 3/4/17 9:08 PM, Masahiko Sawada wrote:
>>>> On Sat, Mar 4, 2017 at 5:47 PM, Robert Haas <robertmhaas(at)gmail(dot)com> wrote:
>>>>> On Fri, Mar 3, 2017 at 9:50 PM, Masahiko Sawada <sawada(dot)mshk(at)gmail(dot)com> wrote:
>>>>>> Yes, it's taking a time to update logic and measurement but it's
>>>>>> coming along. Also I'm working on changing deadlock detection. Will
>>>>>> post new patch and measurement result.
>>>>>
>>>>> I think that we should push this patch out to v11. I think there are
>>>>> too many issues here to address in the limited time we have remaining
>>>>> this cycle, and I believe that if we try to get them all solved in the
>>>>> next few weeks we're likely to end up getting backed into some choices
>>>>> by time pressure that we may later regret bitterly. Since I created
>>>>> the deadlock issues that this patch is facing, I'm willing to try to
>>>>> help solve them, but I think it's going to require considerable and
>>>>> delicate surgery, and I don't think doing that under time pressure is
>>>>> a good idea.
>>>>>
>>>>> From a fairness point of view, a patch that's not in reviewable shape
>>>>> on March 1st should really be pushed out, and we're several days past
>>>>> that.
>>>>>
>>>>
>>>> Agreed. There are surely some rooms to discuss about the design yet,
>>>> and it will take long time. it's good to push this out to CF2017-07.
>>>> Thank you for the comment.
>>>
>>> I have marked this patch "Returned with Feedback." Of course you are
>>> welcome to submit this patch to the 2017-07 CF, or whenever you feel it
>>> is ready.
>>
>> Thank you!
>>
>
> I re-considered the basic design of parallel lazy vacuum. I didn't
> change the basic concept of this feature and usage, the lazy vacuum
> still executes with some parallel workers. In current design, dead
> tuple TIDs are shared with all vacuum workers including leader process
> when table has index. If we share dead tuple TIDs, we have to make two
> synchronization points: before starting vacuum and before clearing
> dead tuple TIDs. Before starting vacuum we have to make sure that the
> dead tuple TIDs are not added no more. And before clearing dead tuple
> TIDs we have to make sure that it's used no more.
>
> For index vacuum, each indexes is assigned to a vacuum workers based
> on ParallelWorkerNumber. For example, if a table has 5 indexes and
> vacuum with 2 workers, the leader process and one vacuum worker are
> assigned to 2 indexes, and another vacuum process is assigned the
> remaining one. The following steps are how the parallel vacuum
> processes if table has indexes.
>
> 1. The leader process and workers scan the table in parallel using
> ParallelHeapScanDesc, and collect dead tuple TIDs to shared memory.
> 2. Before vacuum on table, the leader process sort the dead tuple TIDs
> in physical order once all workers completes to scan the table.
> 3. In vacuum on table, the leader process and workers reclaim garbage
> on table in block-level parallel.
> 4. In vacuum on indexes, the indexes on table is assigned to
> particular parallel worker or leader process. The process assigned to
> a index vacuums on the index.
> 5. Before back to scanning the table, the leader process clears the
> dead tuple TIDs once all workers completes to vacuum on table and
> indexes.
>
> Attached the latest patch but it's still PoC version patch and
> contains some debug codes. Note that this patch still requires another
> patch which moves the relation extension lock out of heavy-weight
> lock[1]. The parallel lazy vacuum patch could work even without [1]
> patch but could fail during vacuum in some cases.
>
> Also, I attached the result of performance evaluation. The table size
> is approximately 300MB ( > shared_buffers) and I deleted tuples on
> every blocks before execute vacuum so that vacuum visits every blocks.
> The server spec is
> * Intel Xeon E5620 @ 2.4Ghz (8cores)
> * 32GB RAM
> * ioDrive
>
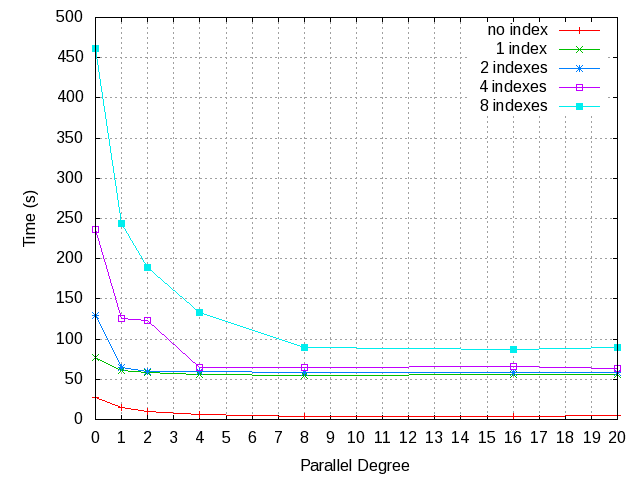
> According to the result of table with indexes, performance of lazy
> vacuum improved up to a point where the number of indexes and parallel
> degree are the same. If a table has 16 indexes and vacuum with 16
> workers, parallel vacuum is 10x faster than single process execution.
> Also according to the result of table with no indexes, the parallel
> vacuum is 5x faster than single process execution at 8 parallel
> degree. Of course we can vacuum only for indexes
>
> I'm planning to work on that in PG11, will register it to next CF.
> Comment and feedback are very welcome.
>
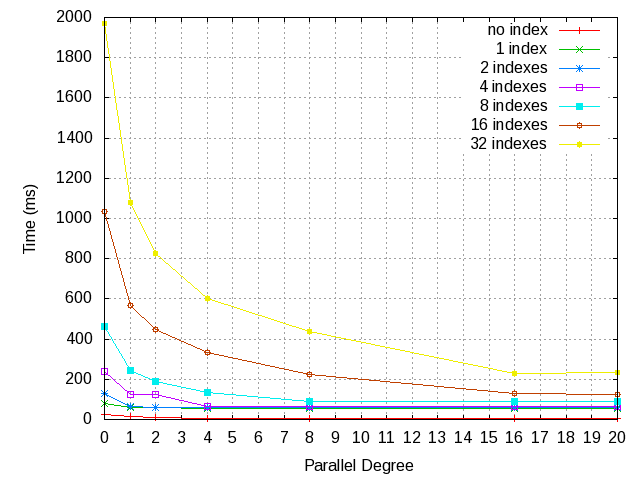
Since the previous patch conflicts with current HEAD I attached the
latest version patch. Also, I measured performance benefit with more
large 4GB table and indexes and attached the result.
Regards,
--
Masahiko Sawada
NIPPON TELEGRAPH AND TELEPHONE CORPORATION
NTT Open Source Software Center
| Attachment | Content-Type | Size |
|---|---|---|
|
image/png | 7.8 KB |
|
image/png | 8.6 KB |
| parallel_vacuum_v4.patch | application/octet-stream | 94.9 KB |
In response to
- Re: Block level parallel vacuum WIP at 2017-07-26 08:38:32 from Masahiko Sawada
Responses
- Re: Block level parallel vacuum WIP at 2017-09-08 10:37:13 from Masahiko Sawada
Browse pgsql-hackers by date
| From | Date | Subject | |
|---|---|---|---|
| Next Message | Marko Tiikkaja | 2017-08-15 01:23:23 | INSERT .. ON CONFLICT DO SELECT [FOR ..] |
| Previous Message | Moon Insung | 2017-08-15 01:11:42 | Re: [PATCH] pageinspect function to decode infomasks |